标签:clean UNC hosts dir end 报错 tcp 版本 tps
# kubeadm是一位高中生的作品,他叫Lucas Kaldstrom,芬兰人,17岁用业余时间完成的一个社区项目:
# kubeadm的源代码,就在kubernetes/cmd/kubeadm目录下,是kubernetes项目的一部分,
# 其中,app/phases文件夹下代码,对应的就是工作原理中详细介绍的每一个具体步骤:
# 两条指令完成一个Kubernetes集群的部署:
# 创建一个Master节点
# init
# 将一个Node节点加入到当前集群中
# kubeadm join <Master 节点的IP和端口>
# kubeadm工作原理
# Kubernetes部署时,他的每一个组件都是一个需要被执行的、单独的二进制文件
# kubeadm的方案
# kubelet直接运行在宿主机上,然后使用容器部署到其他的kubernetes组件:
# 1.在机器上手动安装Kubeadm,kubelet和kubectl三个二进制文件,kubeadm作者已经为各个发行版linux准备好了安装包
# 你只需执行: apt-get install kubeadm
# 2.使用kubeadm init 部署Master节点
# kubeadm init 工作流程
# 执行kubeadm init指令后, kubeadm首先要做的,是一系列的检查工作,
# 以确定这台机器可以用来部署kubernetes这一步检查,称之为“Preflight checks" ,可以省去很多后续麻烦。
# preflight check包括(部分)
# Linux内部版本是否3.10以上?
# Linux Cgroups模块是否可用?
# 机器的hostname是否标准? 在Kubenetes项目,机器的名字以及一切存储在Etcd中的API对象,
# 必须使用标准的DNS命名、
# 用户安装的Kubeadm和Kubelet版本是否匹配?
# kubenetes工作端口10250/10251/10252端口是不是被占用?
# ip、mount等linux指令是否存在?
# Docker是否已经安装?
# 通过Preflight Checks之后,kubeadm生成Kubernetes对外提供服务所需各种证书和对应的目录:
# kubernetes对外提供服务时,除非专门开启“不安全模式”,否则要通过HTTPS才能访问kube-apiserver,
# 这需要为kubernetes集群配置好证书文件。
# kubeadm为kubernetes项目生成证书文件都放在Master节点的/etc/kubernetes/pki目录下,在这个目录下,
# 最主要证书文件是ca.cra和对应的私钥ca.key;
CentOS7.3
kubernetes-cni-0.7.5-0.x86_64
kubectl-1.17.0-0.x86_64
kubelet-1.17.0-0.x86_64
kubeadm-1.17.0-0.x86_64
docker-ce-18.09.9-3.el7.x86_64
| 节点名 | IP | 软件版本 | 说明 |
|---|---|---|---|
| Master | 116.196.83.113 | docker:1809/kubernetes1.6 | 阿里云 |
| Node1 | 121.36.43.223 | docker:1809/kubernetes1.6 | 阿里云 |
| Node2 | 120.77.248.31 | docker:1809/kubernetes1.6 | 阿里云 |
注意事项:
1. 跟传统服务器上部署k8s集群一样操作却kubeadm init一直超时报错?
# 一般情况下,"kubeadm"部署集群时指定"--apiserver-advertise-address=<public_ip>"参数,
# 即可在其他机器上,通过公网IP join到本机器,然而,阿里云和一些其他云服务器没配置公网IP,
# etcd会无法启动,导致初始化失败.我们只需要自己创建一个公网IP即可.
# 初始化
init_security() {
systemctl stop firewalld
systemctl disable firewalld &>/dev/null
setenforce 0
sed -i ‘/^SELINUX=/ s/enforcing/disabled/‘ /etc/selinux/config
sed -i ‘/^GSSAPIAu/ s/yes/no/‘ /etc/ssh/sshd_config
sed -i ‘/^#UseDNS/ {s/^#//;s/yes/no/}‘ /etc/ssh/sshd_config
systemctl enable sshd crond &> /dev/null
rpm -e postfix --nodeps
echo -e "\033[32m [安全配置] ==> OK \033[0m"
}
init_security
init_yumsource() {
if [ ! -d /etc/yum.repos.d/backup ];then
mkdir /etc/yum.repos.d/backup
fi
mv /etc/yum.repos.d/* /etc/yum.repos.d/backup 2>/dev/null
if ! ping -c2 www.baidu.com &>/dev/null
then
echo "您无法上外网,不能配置yum源"
exit
fi
curl -o /etc/yum.repos.d/163.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo &>/dev/null
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo &>/dev/null
yum clean all
timedatectl set-timezone Asia/Shanghai
echo "nameserver 114.114.114.114" > /etc/resolv.conf
echo "nameserver 8.8.8.8" >> /etc/resolv.conf
chattr +i /etc/resolv.conf
yum -y install ntpdate
ntpdate -b ntp1.aliyun.com # 对时很重要
echo -e "\033[32m [YUM Source] ==> OK \033[0m"
}
init_yumsource
# 关掉swap分区
swapoff -a
# 如果想永久关掉swap分区,打开如下文件注释掉swap哪一行即可.
vim /etc/fstab
# 配置主机名解析
tail -3 /etc/hosts
116.196.83.113 master
121.36.43.223 node1
120.77.248.31 node2
安装一些必要的系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加软件源信息
# docker 官方源
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 阿里云源
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker-ce
# 如果想安装特定版本的Docker-ce版本,先列出repo中可用版本,然后选择安装
yum list docker-ce --showduplicates |sort -r
yum install docker-ce-<VERSION STRING>
# 选择安装 docker-ce-18.09.9-3.el7
yum -y install docker-ce-18.09.9-3.el7
# Docker镜像加速
# 没有启动/etc/docker 目录不存在,需要自己建立,启动会自己创建;
# 为了期望我们镜像下载快一点,应该定义一个镜像加速器,加速器在国内
mkdir /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
EOF
systemctl start docker && systemctl enable docker && systemctl daemon-reload
systemctl start docker && systemctl enable docker && systemctl daemon-reload # 守护进程重启
docker info |grep Cgroup # 注意看出来信息是否是cgroupfs
# 这个时候我们过滤信息会有两个警告,这一步一定要做,不然可能初始化集群会报错
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness=0
EOF
# 这三个包在所有机器上安装
# kubeadm: 从零开始配置K8s cluster的tools;
# kubelet: 集群的每个机器上都需要运行的组件,用来启动pods和containers
# kubectl: 用来和集群交互的命令行工具
vim /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
enabled=1
yum -y install ipset fast makecache kubelet kubeadm kubectl ipvsadm
systemctl --system
# 如果 net.bridge.bridge-nf-call-iptables 报错,加载 br_netfilter 模块,就是之前创建的k8s.conf文件
#
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
# 加载 ipvs 相关内核模块 如果重新开机,需要重新加载(可以写在 /etc/rc.local 中开机自动加载)
# cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
# lsmod | grep ip_vs 查看是否加载成功
# 配置启动kubelet(所有节点)
# 如果使用谷歌的镜像: cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=cgroupfs --pod-infra-container-image=k8s.gcr.io/pause:3.1"
EOF
# 如果docker使用systemd就不用做上面这一步,需要修改daemon.json文件
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
# 使用systemd作为docker的cgroup driver可以确保服务器节点在资源紧张的情况更加稳定
# 每个节点都启动kubelet
systemctl daemon-reload && systemctl enable kubelet && systemctl restart kubelet
# 这个时候看状态会看到错误信息,等kubeadm init 生成CA证书会被自动解决;
所有节点获取镜像
cat k8s2.sh
for i in `kubeadm config images list`; do
imageName=${i#k8s.gcr.io/}
docker pull registry.aliyuncs.com/google_containers/$imageName
docker tag registry.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.aliyuncs.com/google_containers/$imageName
done
每个节点执行此脚本
初始化Master节点
# 一般情况下,"kubeadm"部署集群时指定"--apiserver-advertise-address=<public_ip>"参数,
# 即可在其他机器上,通过公网IP join到本机器,然而,阿里云和一些其他云服务器没配置公网IP,
# etcd会无法启动,导致初始化失败.
ipconfig eth0:1 116.196.83.113 netmask 255.255.255.255 broadcast 116.196.83.113 up
# 说明与注意
# 1. 必须用up启动,让这个IP生效.
# 2. 这种方法只是临时的,如果reboot的话,则会全部消失.
# 我们可以将增加ip的命令填写到/etc/rc.local文件中
# 接下来我们只需要配置master节点,运行初始化过程如下:
kubeadm init --kubernetes-version=v1.17.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=116.196.83.113 --ignore-preflight-errors=Swap
# 注意此处的版本,版本更替有点快.
# --apiserver-advertise-address: 指定Master的那个IP地址与Cluster的其他节点通信
# --service-cidr: 指定Service网络的范围,及负载均衡使用的IP地址段.
# --pod-network-cidr: 指定Pod网络的范围,即Pod的IP地址段.
# --image-repository: Kubernetes默认Registries地址是k8s.gcr.io,在国内并不能访问gcr.io,
# 在1.13版本我们可以增加-image-repository参数,默认值是k8s.gcr.io,
# 将其指定为阿里云镜像地址: registry.aliyuncs.com/....
# --kubernetes-version=v1.17.0,指定要安装的版本号
# --ignore-prefilght-errors=: 忽略运行时的错误.
如果出现以下信息就说明初始化成功
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable
kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 116.196.83.113:6443 --token dm73l2.y68gl7lwq18kpuss --discovery-token-ca-cert-hash sha256:5139a172cd23276b70ec964795a6833c11e104c4b5c212aeb7fca23a3027914f
#出来一长串信息记录了完成初始化输出内容,根据内容可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤
# 有以下关键内容
# [kubelet] 生成kubelet的配置文件"/var/lib/kubelet/config.yaml"
# [certificates] 生成相关的各种证书
# [kubeconfig] 生成相关的kubeconfig文件
# [bootstraptoken] 生成的token记录下来,后边使用kubeadm join往集群中添加节点会用到
# 配置使用kubectl
# 如下操作在master节点操作
rm -rf $HOME/.kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master ~] kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 84s v1.16.0
# 将admin.conf传给其他节点,不然网络插件装不上去
[root@master ~]# scp /etc/kubernetes/admin.conf k8s-node1:/etc/kubernetes/admin.conf
[root@master ~]# scp /etc/kubernetes/admin.conf k8s-node2:/etc/kubernetes/admin.conf
# 下面命令在node节点上执行
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
# 配置使用网络插件
# 将node节点加入到主节点(所有node节点)
kubeadm join 116.196.83.113:6443 --token dm73l2.y68gl7lwq18kpuss --discovery-token-ca-cert-hash sha256:5139a172cd23276b70ec964795a6833c11e104c4b5c212aeb7fca23a3027914f
# 配置网络插件
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
正常来说过一段时间master节点就会出现下面信息,即代表成功
kubectl get nodes # 查看节点状态
NAME STATUS ROLES AGE VERSION
master Ready master 44m v1.17.0
node1 Ready <none> 16m v1.17.0
node2 Ready <none> 15m v1.17.0
# 如果主节点一直处于NotReady,coredns处于pending,可能是网络插件的问题,可以先下载flannel.yml网络插件,
# 手动装
# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
# 如果一直装不上,可以先装一个第三方的,然后删除这个pod,过一会就好了
# docker pull jmgao1983/flannel
# 整个集群所有节点(包括master)重置/移除节点
# 驱离k8s-node-1节点上的pod(master上执行)
[root@k8s-master ~]# kubectl drain k8s-node-1 --delete-local-data --force --ignore-daemonsets
# 删除节点 (master上执行)
[root@k8s-master ~]# kubectl delete node k8s-node-1
# 重置节点 (node上-也就是在被删除的节点上)
[root@k8s-node-1 ~]# kubeadm reset
# 1:需要把 master 也驱离、删除、重置,第一次没有驱离和删除 master,最后的结果是查看结 果一切正常,
# 但 coredns 死活不能用;
# 2.master上在reset之后需要删除如下文件
rm -rf /var/lib/cni/$HOME/.kube/config
# kubeadm生成的token过期后,集群增加节点会报错,该token就不可用了
# 解决办法
# 一、
# 1.重新生成新的token;
# kubeadm token create
# kiyfhw.xiacqbch8o8fa8qj
# kubeadm token list
# 2.获取ca证书sha256编码的hash值
# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | \
# openssl rsa -pubin -outform der 2 >/dev/null \
#| openssl dgst -sha256 -hex | sed ‘s/^.* //‘
# 3.节点加入集群
# kubeadm join 18.16.202.35:6443 --token kiyfhw.xiacqbch8o8fa8qj \
# --discovery-token-ca-cert-hash sha256:5417eb1b68bd4e7a4c82aded83abc55ec91bd601e45734d6abde8b1ebb057
# 几秒钟后,kubectl get nodes在主服务器上运行时输出此节点,如果嫌繁琐可直接使用
# kubeadm token create --print-join-command
# 二、
# token=$(kubeadm token generate) kubeadm token create $token --print-join-command --ttl=0
kubectl taint nodes --all node-role.kubernetes.io/master-
# k8s集群如果重启后kubelet起不来,从selinux,防火墙,swap分区以及路由转发,环境变量排查一下
# 1. 查看node状态
kubectl get node # 简写no也行
NAME STATUS ROLES AGE VERSION
master Ready master 91m v1.17.0
node1 Ready <none> 62m v1.17.0
node2 Ready <none> 62m v1.17.0
kubectl get node node1 node2 # 可用空格写多个
NAME STATUS ROLES AGE VERSION
node1 Ready <none> 63m v1.17.0
node2 Ready <none> 63m v1.17.0
# 2. 删除节点
kubectl delete node node1
# 3. 查看节点详细信息,用于排错.
kubectl describe node node1
1. 查看所有pod
kubectl get pods
2. 查看某一个Pod
kubectl get pod nginx1
3. 查看Pod的详细信息
kubectl describe pod nginx1
1. 查看service信息
kubectl get service # 查看service的信息,可以简写svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 84m
# 使用service暴露端口,service本身有一个cluster ip,此ip不能被ping,
# 只能看到默认空间的.
2. 查看所有名称空间的资源
kubectl get service --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 98m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 98m
3. 查看kube-system名称空间的资源
kubectl get pods -n kube-system # 查看kube-system名称空间内的资源,可以在pod前加上svc等同时查看
NAME READY STATUS RESTARTS AGE
coredns-6955765f44-h4wp5 1/1 Running 0 45m
coredns-6955765f44-zg7bf 1/1 Running 0 45m
etcd-master 1/1 Running 0 45m
kube-apiserver-master 1/1 Running 0 45m
kube-controller-manager-master 1/1 Running 0 45m
kube-flannel-ds-amd64-9l5rn 1/1 Running 0 20m
kube-flannel-ds-amd64-9vtfm 1/1 Running 0 16m
kube-flannel-ds-amd64-zzqbb 1/1 Running 0 16m
kube-proxy-d2qfg 1/1 Running 0 16m
kube-proxy-lr945 1/1 Running 0 16m
kube-proxy-tnqsz 1/1 Running 0 45m
kube-scheduler-master 1/1 Running 0 45m
1. 查看集群信息
kubectl cluster-info
2. 查看各组件信息
kubectl get pod -n kube-system -o wide
# 在Kubectl各个组件都是以应用部署的,故需要看到ip地址才能查看组件信息.
-n: --namespace命名空间,给k8s不同的应用分类用的
-o: 显示pod运行在哪个节点上和ip地址.
3. 查看组件状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
4. 查询api server
至此,基础环境部署是完成了,接下来我们去创建个Pod,大概熟悉下kubernetes
# 旧方式创建Pod
kubectl run nginx-test1 --image=daocloud.io/library/nginx --port=80 --replicas=1
# 此时会有一个警告,因为这个方式创建Pod比较旧了.
# 新方式创建Pod
kubectl run --generator=run-pod/v1 nginx-test2 --image=daocloud.io/library/nginx --port=80 --replicas=1
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-test1-6d4686d78d-ftdj9 1/1 Running 0 2m20s 10.244.2.3 node2 <none> <none>
nginx-test2 1/1 Running 0 76s 10.244.1.3 node1 <none> <none>
# 去相应的节点访问指定IP即可访问
curl -I -s 10.244.1.3 |grep 200
HTTP/1.1 200 OK
kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-test1 1/1 1 1 10m nginx-test1 daocloud.io/library/nginx run=nginx-test1
# 我们可以发现旧方式创建的Pod能直接创建deployent,新方式是直接创建Pod,
# deployment里面的服务是可以集群内每个节点访问的,但是Pod只能被所属节点访问.
# 查看Pod定义的详细信息
kubectl get pods second-nginx -o yaml
kubectl get pods second-nginx -o json
# 以GoTemplate方式过滤指定的信息--查询Pod的运行状态(类似docker的inspect)
kubectl get pods nginx-test2 --output=go-template --template={{.status.phase}}
Running
# 查看Pod中定义执行命令的输出 ---和docker logs一样
kubectl log pod名称
# 查看Pod的状态和声明周期事件
kubectl describe pod nginx-test2
Name: nginx-test2 # 名字段含义
Namespace: default
Priority: 0
Node: node1/192.168.0.110
Start Time: Sun, 15 Dec 2019 19:52:10 +0800
Labels: run=nginx-test2
Annotations: <none>
Status: Running
IP: 10.244.1.3
IPs:
IP: 10.244.1.3
Containers: # Pod中容器的信息
nginx-test2: # 容器的ID
Container ID: docker://3df2a2e16d6eaf909022627fac23c829bad006657fb03b4275bb536c8f5c9d90
Image: daocloud.io/library/nginx #容器的镜像
Image ID: docker-pullable://daocloud.io/library/nginx@sha256:f83b2ff11fc3fb90aebdebf76
Port: 80/TCP
Host Port: 0/TCP
State: Running # 容器状态
Started: Sun, 15 Dec 2019 19:52:14 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-8lcxt (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes: # 容器的数据卷
default-token-8lcxt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-8lcxt
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events: # 与Pod相关的事件表
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 22m default-scheduler Successfully assigned default/nginx-test2 to node1
Normal Pulling 22m kubelet, node1 Pulling image "daocloud.io/library/nginx"
Normal Pulled 22m kubelet, node1 Successfully pulled image "daocloud.io/library/nginx"
Normal Created 22m kubelet, node1 Created container nginx-test2
Normal Started 22m kubelet, node1 Started container nginx-test2
# 扩展Pod数量为4
kubectl scale --replicas=4 deployment nginx-test1
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-test1-6d4686d78d-dsgdv 1/1 Running 0 89s
nginx-test1-6d4686d78d-ftdj9 1/1 Running 0 31m
nginx-test1-6d4686d78d-k49br 1/1 Running 0 89s
nginx-test1-6d4686d78d-wsnsh 1/1 Running 0 89s
nginx-test2 1/1 Running 0 30m
# 缩减只用修改replicas后面数字即可
kubectl scale --replicas=1 deployment nginx-test1
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-test1-6d4686d78d-ftdj9 1/1 Running 0 32m
nginx-test2 1/1 Running 0 31m
# 为了验证更加明显,更新时将nginx替换为httpd服务
kubectl set image deployment nginx-test nginx-test=httpd
# 实时查看更新过程
kubectl get deployment -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-test1 4/5 3 4 54m
nginx-test1 5/5 3 5 54m
nginx-test1 4/5 3 4 54m
nginx-test1 4/5 4 4 54m
nginx-test1 5/5 4 5 54m
# 我们可以去相应节点去访问试试
curl 10.244.1.20
<html><body><h1>It works!</h1></body></html>
# 更新后回滚原来的nginx
kubectl rollout undo deployment nginx-test1
deployment.apps/nginx-test1 rolled back
# 实时查看回滚的进度
kubectl get deployment -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-test1 4/5 3 4 56m
nginx-test1 5/5 3 5 57m
nginx-test1 4/5 3 4 57m
nginx-test1 4/5 4 4 57m
nginx-test1 5/5 4 5 57m
# 回滚完成后验证.
curl -s 10.244.1.23 -I |grep Server
Server: nginx/1.17.6
kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=2
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
myapp 2/2 2 2 3m21s
nginx-test1 5/5 5 5 89m
kubectl get pods -o wide |grep myapp
# 我们去相应的节点访问,通过循环不断访问,可以看出更新的效果.但是因为更换pod后可能IP会换.
while true; do curl 10.244.1.25; sleep 1 ;done
# 滚动更新
kubectl set image deployment myapp myapp=ikubernetes/myapp:v2
# 接下来我们可以看deployment控制器详细信息
kubectl describe deployment myapp |grep myapp:v2
Image: ikubernetes/myapp:v2
# 接下来我们回滚一下试试
kubectl rollout undo deployment myapp
kubectl describe deployment myapp |grep Image:
Image: ikubernetes/myapp:v1
curl 10.244.1.27
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
将pod创建完成后,访问该pod内的服务只能在集群内部通过Pod的地址去访问该服务;当该pod出现故障后,该pod的控制器会重新创建一个包括该服务的pod,此时访问该服务须要获取该服务所在的新的pod地址去访问,对此可以创建一个service,当新的pod创建完成后,service会通过pod的label连接到该服务,只需通过service即可访问该服务;
# 接下来我们可以删除当前Pod
kubectl delete pod myapp-7c468db58f-4grch
# 删除Pod后,查看Pod信息发现又创建了一个新的Pod。
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-7c468db58f-j7qdj 1/1 Running 0 32s 10.244.2.29 node
myapp-7c468db58f-pms57 1/1 Running 0 14m 10.244.1.27 node
# 我们可以创建一个service,并将包含myapp的标签加入进来.
# service的创建通过“kubectl expose”命令创建,该命令的具体用法可以通过kubectl expose --help查看,
# service创建完成后,通过service地址访问pod中的服务依然只能通过集群地址去访问.
kubectl expose deployment nginx-test1 --name=nginx --port=80 --target-port=80 --protocol=TCP
# 查看一下service,待会直接访问这个service的IP地址.
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4h55m
myapp ClusterIP 10.96.241.42 <none> 80/TCP 88m
nginx ClusterIP 10.96.11.13 <none> 80/TCP 4m41s
# 因为是通过service地址去访问nginx,Pod被删除重新创建后,依然可以通过service访问Service下的Pod中的服务.
# 但前提是需要配置Pod地址为core dns服务的地址,新建的Pod中DNS地址
curl 10.96.11.13 -I
HTTP/1.1 200 OK
Server: nginx/1.17.6
Date: Sun, 15 Dec 2019 14:50:36 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 19 Nov 2019 12:50:08 GMT
Connection: keep-alive
ETag: "5dd3e500-264"
Accept-Ranges: bytes
kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 5h6m
kubectl describe svc nginx
Name: nginx
Namespace: default
Labels: run=nginx-test1 # 标签是不变的
Annotations: <none>
Selector: run=nginx-test1
Type: ClusterIP
IP: 10.96.11.13
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.22:80,10.244.1.23:80,10.244.1.24:80 + 2 more...
Session Affinity: None
Events: <none>
# 查看Pod的标签
kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-test1-7798fd9994-559tc 1/1 Running 0 141m pod-template-hash=7798fd9994,run=nginx-test1
# coredns 服务队service名称的解析是实时的,在service被重新创建后或者修改service的ip地址后,
# 依然可以通过service名称访问pod中的服务;
# 删除并重新创建一个名称为nginx的service
kubectl delete svc nginx
service端口暴露
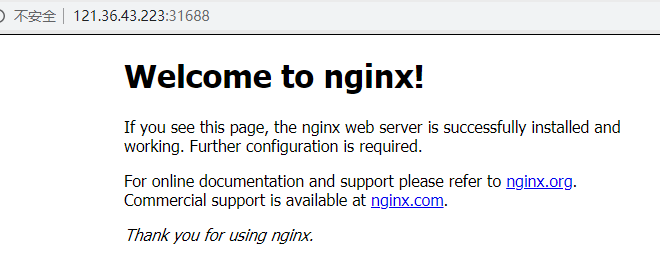
创建好pod及service后,无论是通过pod地址及service地址在集群外部都无法访问pod中的服务:如果想要在集群外部访问pod中的服务,需要修改service的类型为NodePort,修改后会自动添加nat规则,此时就可以通过nade节点地址访问pod中的服务;
# 我们先创建一个名称为web的service
kubectl expose deployment nginx-test1 --name=web
# 编辑配置文件,修改自己要暴露的端口
kubectl edit svc web
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2019-12-15T15:15:03Z"
labels:
run: nginx-test1
name: web
namespace: default
resourceVersion: "49527"
selfLink: /api/v1/namespaces/default/services/web
uid: 82ca9472-3e55-495f-94a3-3c826a6f6f6e
spec:
clusterIP: 10.96.18.152
externalTrafficPolicy: Cluster
ports:
- nodePort: 31688 # 添加此行
port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx-test1
sessionAffinity: None
type: NodePort # 修改此处
status:
loadBalancer: {}
netstat -lntp |grep 30837
tcp6 0 0 :::30837 :::* LISTEN 114918/kube-proxy
# 在外部可以通过node节点的地址及该端口访问pod内的服务;
标签:clean UNC hosts dir end 报错 tcp 版本 tps
原文地址:https://www.cnblogs.com/you-men/p/13185384.html