标签:排序 就是 自动 python 参数形式 美国 answer 估计 and
公司有一个数据处理线,上面的数据经过不同环境处理,然后上线到正式库。其中一个环节需要将数据进行处理然后导入到另外一个库(Sql Server)。这个处理的程序是老大用python写的,处理完后进入另外一个库后某些字段出现了乱码。
比如这个字符串:1006?267X(2020)02?0548?10
另外一个库变成:1006?267X(2020)02?0548?10
线上人员反馈回来后老大由于比较忙,一直没有排查,然后我问了下估计是什么原因。老大说他python里面转了utf8,可能是编码问题。我当时问了下就没下文了,因为我不会python,所以这个事情就搁置了。
然后这个问题拖了很久,线上也不断反馈。同时自己也负责这块,空闲时间就主动去排查了下原因。当然这个排查过程还是比较曲折的,所以就把这个过程分享下,同时回顾下涉及到的知识点。
先说结果:最后经过排查是由于python处理后insert语句插入到Sql Server数据库保存字段前没有加N。
1.SQL Server数据类型
首先由于数据写进去出现乱码,所以第一步就是检查写入库的字段是否设置了正确的数据类型。因为有时候对char与varchar的区别或者varchar与nvarchar的区别不是很在意,所以有可能设置了错误的数据类型。至于这几个字符的数据类型区别是什么,这里摘抄官方解释。
字符数据类型 char(大小固定)或 varchar(大小可变) 。 从 SQL Server 2019 (15.x) 起,使用启用了 UTF-8 的排序规则时,这些数据类型会存储 Unicode 字符数据的整个范围,并使用 UTF-8 字符编码。 若指定了非 UTF-8 排序规则,则这些数据类型仅会存储该排序规则的相应代码页支持的字符子集。
参数
char [ ( n ) ]
固定大小字符串数据 。 n 用于定义字符串大小(以字节为单位),并且它必须为 1 到 8,000 之间的值 。 对于单字节编码字符集(如拉丁文),存储大小为 n 个字节,并且可存储的字符数也为 n。 对于多字节编码字符集,存储大小仍为 n 个字节,但可存储的字符数可能小于 n。 char 的 ISO 同义词是 character 。
varchar [ ( n | max ) ]
可变大小字符串数据 。 使用 n 定义字符串大小(以字节为单位),可以是介于 1 和 8,000 之间的值;或使用 max 指明列约束大小上限为最大存储 2^31-1 个字节 (2GB)。 对于单字节编码字符集(如拉丁文),存储大小为 n + 2 个字节,并且可存储的字符数也为 n。 对于多字节编码字符集,存储大小仍为 n + 2 个字节,但可存储的字符数可能小于 n 。
字符数据类型 nchar(大小固定)或 nvarchar(大小可变) 。 从 SQL Server 2012 (11.x) 起,使用启用了补充字符 (SC) 的排序规则时,这些数据类型会存储 Unicode 字符数据的整个范围,并使用 UTF-16 字符编码。 若指定了非 SC 排序规则,则这些数据类型仅会存储 UCS-2 字符编码支持的字符数据子集。
nchar [ ( n ) ]
固定大小字符串数据。 n 用于定义字符串大小(以双字节为单位),并且它必须为 1 到 4,000 之间的值 。 存储大小为 n 字节的两倍。 对于 UCS-2 编码,存储大小为 n 个字节的两倍,并且可存储的字符数也为 n。 对于 UTF-16 编码,存储大小仍为 n 个字节的两倍,但可存储的字符数可能小于 n,因为补充字符使用两个双字节(也称为代理项对)。 nchar 的 ISO 同义词是 national char 和 national character 。
nvarchar [ ( n | max ) ]
可变大小字符串数据。 n 用于定义字符串大小(以双字节为单位),并且它可能为 1 到 4,000 之间的值 。 max 指示最大存储大小是 2^30-1 个字符 (2 GB) 。 存储大小为 n 字节的两倍 + 2 个字节。 对于 UCS-2 编码,存储大小为 n 个字节的两倍 + 2 个字节,并且可存储的字符数也为 n。 对于 UTF-16 编码,存储大小仍为 n 个字节的两倍 + 2 个字节,但可存储的字符数可能小于 n,因为补充字符使用两个双字节(也称为代理项对)。 nvarchar 的 ISO 同义词是 national char varying 和 national character varying 。
通过上面的描述我们可以总结:这几种类型都是存储字符数据,如果存储单字节的字符串(比如英文)使用char、varchar,节约空间。如果存储多字节的字符串(比如包含中文)使用nchar、nvarchar,兼容更多的编码。双字节比单字节对应的多了一个n。
单字节双字节中还有一个区别var,表示可变大小字符串数据。可变是指如果某字段插入的值超过了数据页的长度,该行的字段值将存放到ROW_OVERFLOW_DATA中。但是会造成多余的I/O,比如一个VARCHAR列经常被修改,而且每次被修改的数据的长度不同,这会引起‘行迁移’(Row Migration)现象。这里就不展开了,可以去了解下。
所以我们设计数据库字段的时候需要根据业务设计合理的数据类型,有利于节约空间和时间。而经过我检查数据库字段确实设置的nvarchar,所以不存在存储不了对应编码问题。而且问了老大他说python里面他转了UTF8编码,所以下一步就是排查是否转编码出了问题。
2.编码
因为我经常写C#,C#里面的字符串是Unicode的,当然对于程序员来说这个编码是透明的,因为是Unicode编码可以转换成其它任何编码,所以我们日常开发的时候并不需要时刻去关注编码的问题,其底层已经帮我们进行了处理。既然说是python转了utf8那么我就去大概看了下python的基础并试验了一把。
先找了一条出现乱码的数据,在原库取出来然后进行utf8转码,然后再解码。讲道理同一个编码解码出来存储应该还是原来的字符串,所以我才会好奇去试验。试验后发现果然没有什么问题。
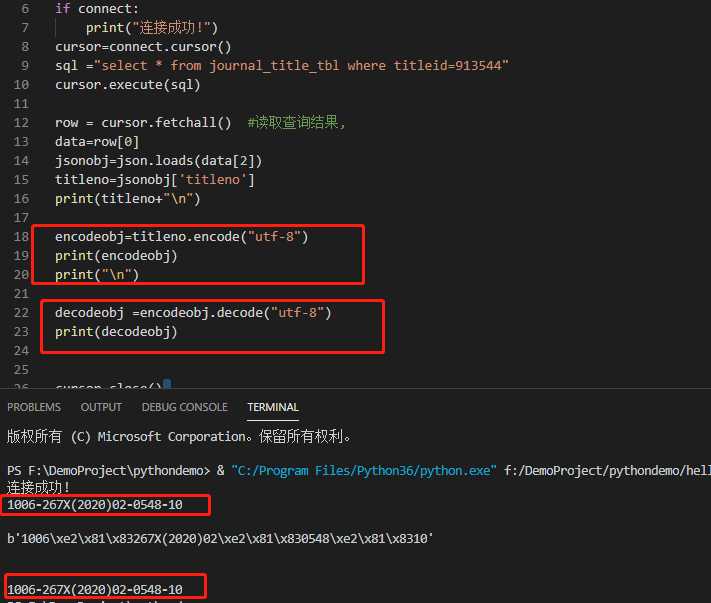
关于编码可以看下这个讲解:编码,因为讲的比较形象而且容易理解,所以我这里就不累述了。
排除python程序编码问题,那接下来就是要排查从程序插入到数据库这一段的问题了。
3.SQL Server排序规则
首先插入这一阶段我想到的还是编码问题,所以去查询了数据库编码。使用sql语句查询数据库排序规则
SELECT COLLATIONPROPERTY(‘Chinese_PRC_Stroke_CI_AI_KS_WS‘, ‘CodePage‘)
对应的字符集编码
936 :简体中文GBK
950 :繁体中文BIG5
437 :美国/加拿大英语
932 :日文
949 :韩文
866 :俄文
65001 :unicode UTF-8
查询了数据排序规则,导入数据库是默认排序规则,也就是936 GBK编码。为什么要看数据库排序规则,第1点中可见“数据类型仅会存储该排序规则的相应代码页支持的字符子集”。
排序规则微软解释:排序规则
SQL Server 中的排序规则可为您的数据提供排序规则、区分大小写属性和区分重音属性。 与诸如 char 和 varchar 等字符数据类型一起使用的排序规则规定可表示该数据类型的代码页和对应字符 。
无论你是要安装 SQL Server 的新实例、还原数据库备份,还是将服务器连接到客户端数据库,都必须了解正在处理的数据的区域设置要求、排序顺序以及是否区分大小写和重音。
所以通过查看排序规则知道,默认编码是GBK。然后我就猜测到是GBK编码问题,因为在python3里面字符串的默认编码也是Unicode,测试下把1006?267X(2020)02?0548?10转成GBK。
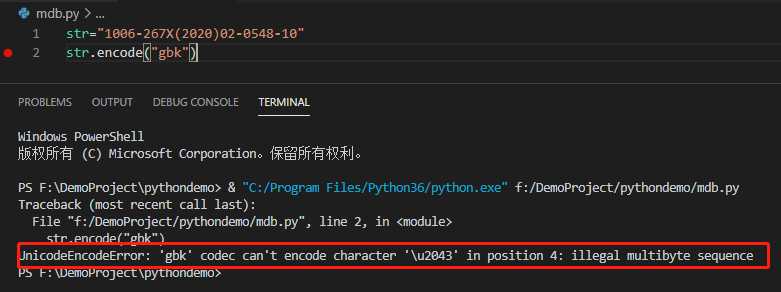
可以看到是无法转码的,gbk识别不了那个短横杠,然后我编码成GB18030能够编码。说明短横杠是更高位的编码,当然unicode是能存储的。那为什么在数据库里面就成了乱码呢?而且字段类型是设置的nvarchar啊。
4、大写字母“N”作为前缀
通过3点的分析,说明了本该存储成Unicode的编码被保存成了默认编码。所以我们只要把保存成Unicode编码就行了,所以到此已经和python程序没什么关系了,带着怀疑的态度,我将这段字符直接拿到Sql Sever里面执行,果然也是乱码。
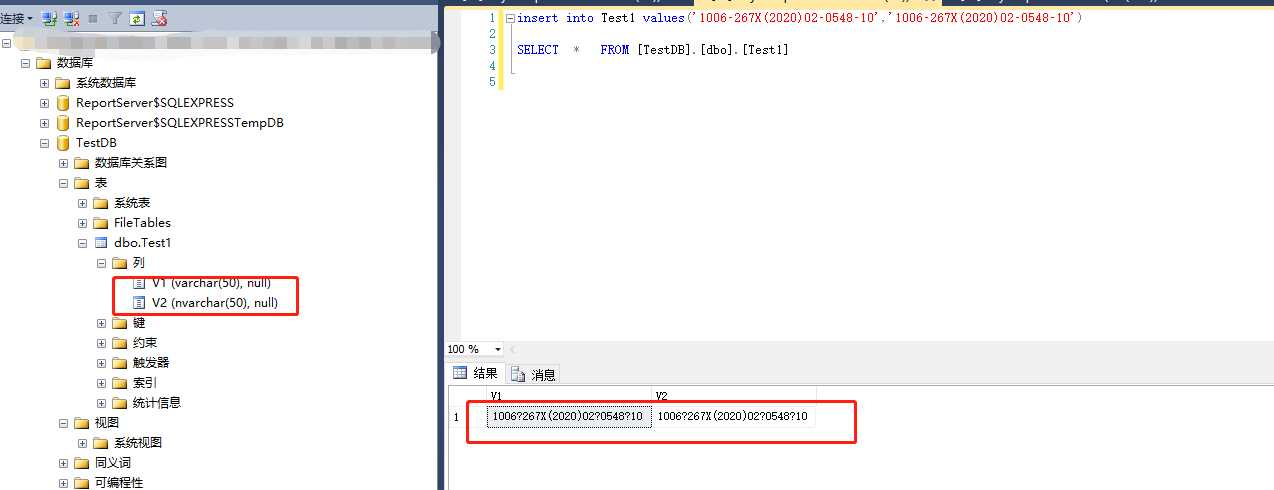
最后就是在参数前加N执行
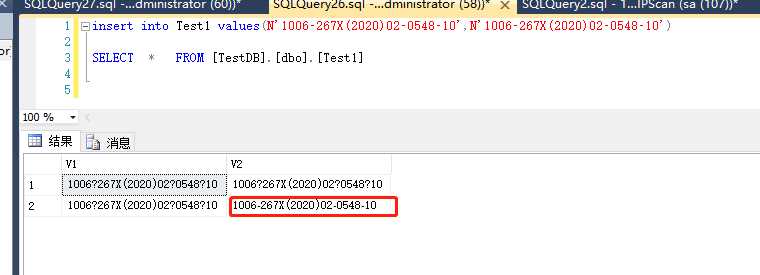
这下结果就正常了。细心的你是否发发现v1字段还是乱码,因为我为了测试varchar单字节,即使我加了N一样的是乱码。所以记得存储中文最好选nvarchar,原因么请看第一点char和varchar的说明中这样一句话:若指定了非 UTF-8 排序规则,则这些数据类型仅会存储该排序规则的相应代码页支持的字符子集。也就是它只会存储我当前数据库的GBK编码。
最后我还在python里面插入的sql语句加了N,同样可以插入成功。

关于加N的解释,微软t-sql文档关于insert说明:链接

5.为什么我们平时很少加N
既然有这样的问题为什么我们平时基本没加过N?原因有几点:
SqlParameter会自动加N?带着怀疑的态度测试下。
首先写一个测试程序,然后开启SQL server跟踪来查看执行的sql。
static void Test()
{
string server = "127.0.0.1";
string database = "TestDB";
string user = "sa";
string password = "******";
string connectionString = $"server={server};database={database};User ID={user};Password={password}";
using (SqlConnection connection = new SqlConnection(connectionString))
{
connection.Open();
using (SqlCommand cmd = new SqlCommand())
{
cmd.Connection = connection;
cmd.CommandText = "insert into Test1 values(‘1006?267X(2020)02?0548?10‘,‘1006?267X(2020)02?0548?10‘)";
cmd.ExecuteNonQuery();
cmd.CommandText = "insert into Test1 values(@v1,@v2)";
cmd.Parameters.Add(new SqlParameter
{
ParameterName = "v1",
Value = "1006?267X(2020)02?0548?10"
});
cmd.Parameters.Add(new SqlParameter
{
ParameterName = "v2",
Value = "1006?267X(2020)02?0548?10"
});
cmd.ExecuteNonQuery();
}
}
}
查看跟踪执行的sql,一个是直接传入拼接sql执行,一个是使用参数方式执行。
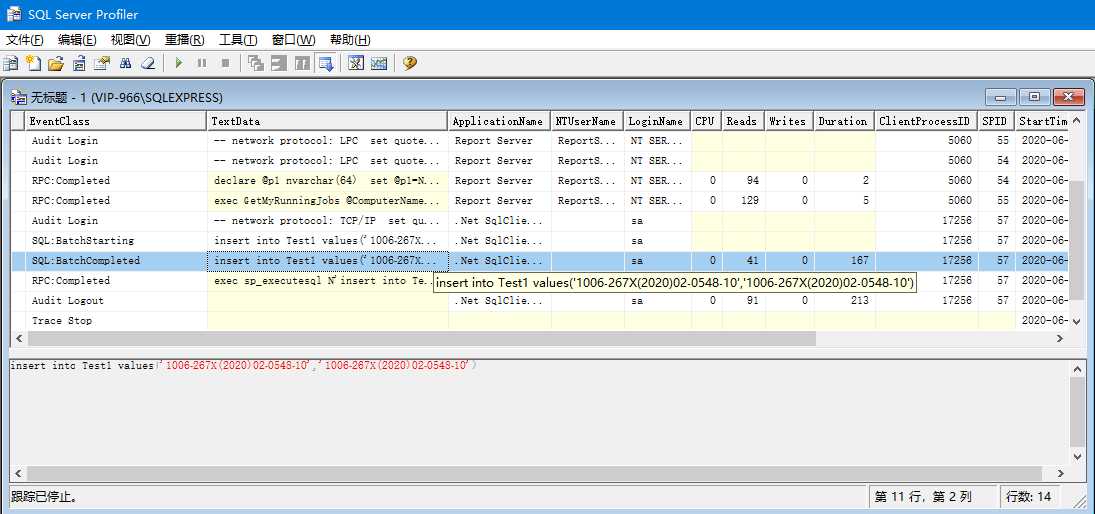
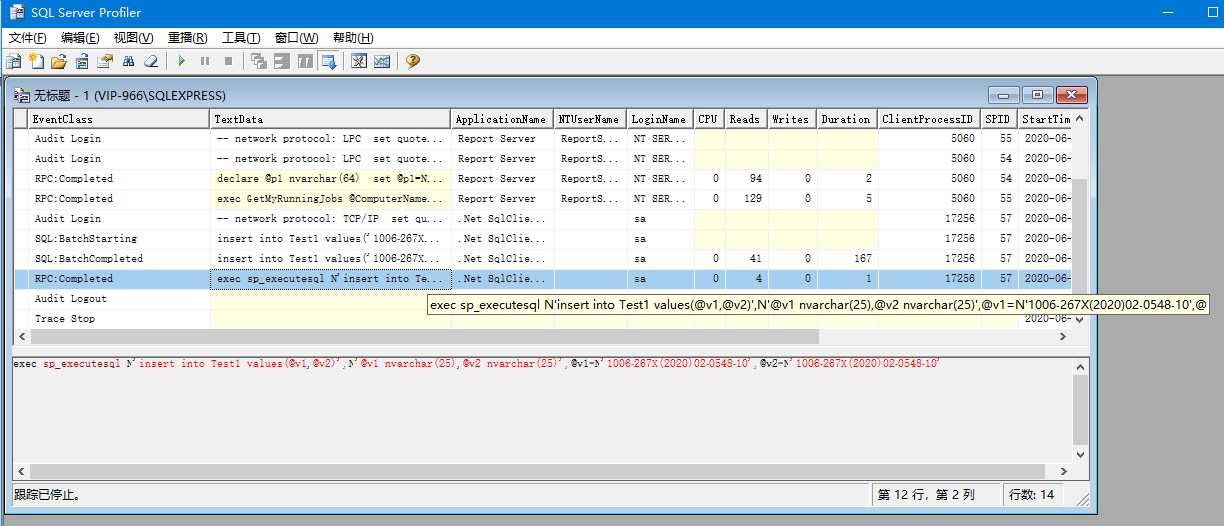
通过一次排查乱码问题,又回顾或者学习了关于数据类型和编码,以及sql存储如何避免乱码问题。平时设计的时候如果是带中文的字段首先考虑带n的char类型。同时在直接使用sql进行insert、update的时候注意在要保存为Unicode编码字符串前面加N。
数据库char varchar nchar nvarchar,编码Unicode,UTF8,GBK等,Sql语句中文前为什么加N(一次线上数据存储乱码排查)
标签:排序 就是 自动 python 参数形式 美国 answer 估计 and
原文地址:https://www.cnblogs.com/SunSpring/p/13177096.html