标签:app policy 定时任务 政策 图片 date start star arw
Kubernetes中的调度是将待处理的pod绑定到节点的过程,由Kubernetes的一个名为kube-scheduler的组件执行。调度程序的决定,无论是否可以或不能调度容器,都由其可配置策略指导,该策略包括一组规则,称为谓词和优先级。调度程序的决定受到其在第一次调度时出现新pod时的Kubernetes集群视图的影响。由于Kubernetes集群非常动态且状态随时间而变化,因此可能需要将已经运行的pod移动到其他节点,原因如下:
因此,可能会在群集中不太理想的节点上安排多个pod。Descheduler根据其政策,发现可以移动并移除它们的pod。请注意,在当前的实现中,descheduler不会安排更换被驱逐的pod,而是依赖于默认的调度程序。
GitHub地址:https://github.com/kubernetes-sigs/descheduler
下面是重要的配置
--- apiVersion: v1 kind: ConfigMap metadata: name: descheduler-policy-configmap namespace: kube-system data: policy.yaml: | apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "RemoveDuplicates": enabled: true "RemovePodsViolatingInterPodAntiAffinity": enabled: true "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 30 "memory": 40 "pods": 50 targetThresholds: "cpu" : 20 "memory": 25 "pods": 15
RemoveDuplicates策略
该策略发现未充分利用的节点,并且如果可能的话,从其他节点驱逐pod,希望在这些未充分利用的节点上安排被驱逐的pod的重新创建。此策略的参数配置在nodeResourceUtilizationThresholds。
节点的利用率低是由可配置的阈值决定的thresholds。thresholds可以按百分比为cpu,内存和pod数量配置阈值 。如果节点的使用率低于所有(cpu,内存和pod数)的阈值,则该节点被视为未充分利用。目前,pods的请求资源需求被考虑用于计算节点资源利用率。
还有另一个可配置的阈值,targetThresholds用于计算可以驱逐pod的潜在节点。任何节点,所述阈值之间,thresholds并且targetThresholds被视为适当地利用,并且不考虑驱逐。阈值targetThresholds也可以按百分比配置为cpu,内存和pod数量。
简单的说:thresholds是没有达到资源使用的node视为资源使用率低可以分配, targetThresholds是已经满足这个条件的node资源紧张要把上面的pod迁移。
--- apiVersion: batch/v1beta1 kind: CronJob metadata: name: descheduler-cronjob namespace: kube-system spec:
#定时任务时间可调 schedule: "*/10 * * * *" concurrencyPolicy: "Forbid" jobTemplate: spec: template: metadata: name: descheduler-pod spec: priorityClassName: system-cluster-critical containers: - name: descheduler image: aveshagarwal/descheduler #image: us.gcr.io/k8s-artifacts-prod/descheduler:v0.10.0 volumeMounts: - mountPath: /policy-dir name: policy-volume command: - "/bin/descheduler" args: - "--policy-config-file" - "/policy-dir/policy.yaml" - "--v" - "3" restartPolicy: "Never" serviceAccountName: descheduler-sa volumes: - name: policy-volume configMap: name: descheduler-policy-configmap
--- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: descheduler-cluster-role namespace: kube-system rules: - apiGroups: [""] resources: ["events"] verbs: ["create", "update"] - apiGroups: [""] resources: ["nodes"] verbs: ["get", "watch", "list"] - apiGroups: [""] resources: ["pods"] verbs: ["get", "watch", "list", "delete"] - apiGroups: [""] resources: ["pods/eviction"] verbs: ["create"] --- apiVersion: v1 kind: ServiceAccount metadata: name: descheduler-sa namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: descheduler-cluster-role-binding namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: descheduler-cluster-role subjects: - name: descheduler-sa kind: ServiceAccount namespace: kube-system
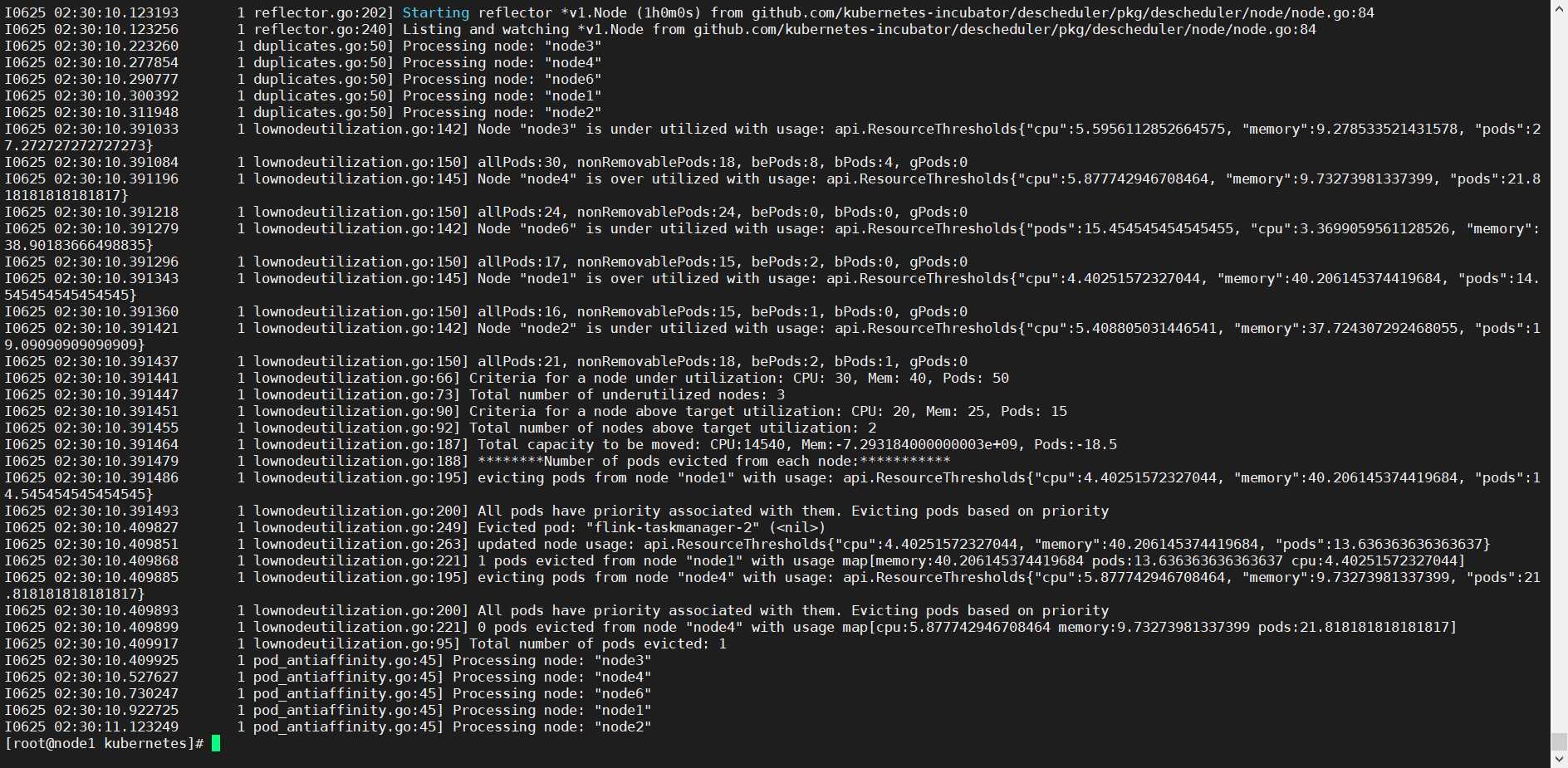
kubectl apply -f 执行上面三个文件,查看日志如有满足再次调度条件的 会重新发起二次调度均衡node资源。
标签:app policy 定时任务 政策 图片 date start star arw
原文地址:https://www.cnblogs.com/Dev0ps/p/13191298.html