标签:增量 tick NPU 系统 div 不同的 特性 work res
特性如下:
可线性伸缩至超过数百个节点;
实现亚秒级延迟处理;
可与Spark批处理和交互式处理无缝集成;
提供简单的API实现复杂算法;
更多的流方式支持,包括Kafka、Flume、Kinesis、Twitter、ZeroMQ等。
原理
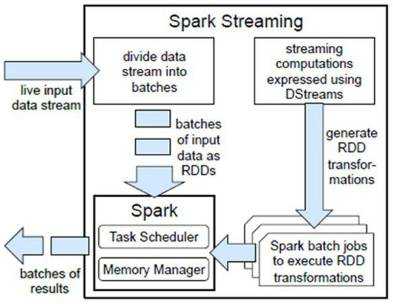
Spark在接收到实时输入数据流后,将数据划分成批次(divides the data into batches),然后转给Spark Engine处理,按批次生成最后的结果流(generate the final stream of results in batches)。

API
DStream
DStream(Discretized Stream,离散流)是Spark Stream提供的高级抽象连续数据流。
组成:一个DStream可看作一个RDDs序列。
核心思想:将计算作为一系列较小时间间隔的、状态无关的、确定批次的任务,每个时间间隔内接收的输入数据被可靠存储在集群中,作为一个输入数据集。
特性:一个高层次的函数式编程API、强一致性以及高校的故障恢复。
应用程序模板:
模板1
模板2

WordCount示例

Input DStream
Input DStream是一种从流式数据源获取原始数据流的DStream,分为基本输入源(文件系统、Socket、Akka Actor、自定义数据源)和高级输入源(Kafka、Flume等)。
每个Input DStream(文件流除外)都会对应一个单一的Receiver对象,负责从数据源接收数据并存入Spark内存进行处理。应用程序中可创建多个Input DStream并行接收多个数据流。
每个Receiver是一个长期运行在Worker或者Executor上的Task,所以会占用该应用程序的一个核(core)。如果分配给Spark Streaming应用程序的核数小于或等于Input DStream个数(即Receiver个数),则只能接收数据,却没有能力全部处理(文件流除外,因为无需Receiver)。
Spark Streaming已封装各种数据源,需要时参考官方文档。
Transformation Operation
常用Transformation
* map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的DStream;
* flatMap(func):与map相似,但是每个输入项可用被映射为0个或者多个输出项;
* filter(func):返回一个新的DStream,仅包含源DStream中满足函数func的项;
* repartition(numPartitions):通过创建更多或者更少的分区改变DStream的并行程度;
* union(otherStream):返回一个新的DStream,包含源DStream和其他DStream的元素;
* count():统计源DStream中每个RDD的元素数量;
* reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream;
* countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数;
* reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来;
* join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新DStream;
* cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组;
* transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作。
updateStateByKey(func)
updateStateByKey可对DStream中的数据按key做reduce,然后对各批次数据累加
WordCount的updateStateByKey版本

transform(func)
通过对原DStream的每个RDD应用转换函数,创建一个新的DStream。
官方文档代码举例

Window operations
窗口操作:基于window对数据transformation(个人认为与Storm的tick相似,但功能更强大)。
参数:窗口长度(window length)和滑动时间间隔(slide interval)必须是源DStream批次间隔的倍数。
举例说明:窗口长度为3,滑动时间间隔为2;上一行是原始DStream,下一行是窗口化的DStream。
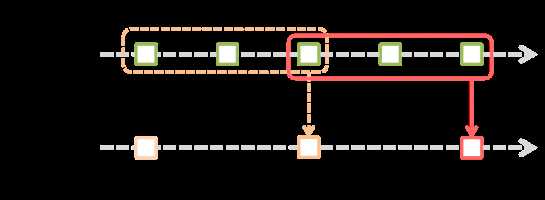
常见window operation
有状态转换包括基于滑动窗口的转换和追踪状态变化(updateStateByKey)的转换。
基于滑动窗口的转换
* window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的DStream;
* countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数;
* reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
* reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数;
* reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
* countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
官方文档代码举例

join(otherStream, [numTasks])
连接数据流
官方文档代码举例1

官方文档代码举例2

Output Operation

缓存与持久化
通过persist()将DStream中每个RDD存储在内存。
Window operations会自动持久化在内存,无需显示调用persist()。
通过网络接收的数据流(如Kafka、Flume、Socket、ZeroMQ、RocketMQ等)执行persist()时,默认在两个节点上持久化序列化后的数据,实现容错。
Kafka、Flume、Kinesis更多的流方式支持,包括Twitter、ZeroMQ等
标签:增量 tick NPU 系统 div 不同的 特性 work res
原文地址:https://www.cnblogs.com/iosboom/p/13193513.html