标签:信息 产生 code alt 慢慢 cap 读写 nod 个人
1、MySQL单机时代
1、数据量如果太大、一个机器放不下了!
2、数据的索引(B+Tree),一个机器内存也放不下
3、访问量(读写混合),一个服务器承受不了
2、Memchached(缓存)+MySQL+垂直拆分(读写分离)
网站80%的情况都是在读,每次都要去查询数据库的话就十分的麻烦!所以说我们希望减轻数据的压力,我们可以使用缓存来保证效率!
发展过程:优化数据结构和索引--> 文件IO --> Memchached
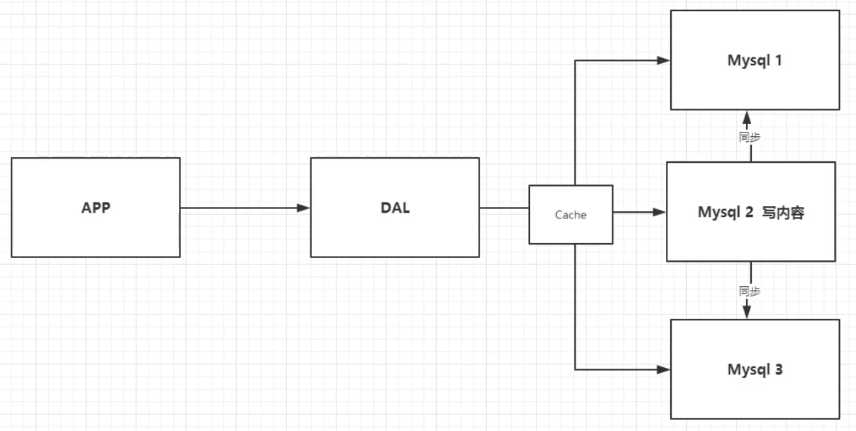
3、分库分表+水平拆分+MySQL集群
数据库本质:读+写
早些年:MyIASM--表锁,十分影响效率,高并发出现十分严重的锁问题
然后:Innodb--行锁
慢慢使用分库分表解决写的压力,MySQL推出了表分区,但是用的人不多
MySQL的集群,很好的满足了当时的需求。
4、如今
MySQL等关系型数据库不够用了,数据量很多,变化快
为什么要用NOSQL
用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长!
这时候我们就需要使用NoSQL数据库的,Nosql可以很好的处理以上的情况!
NoSQL=Not Only SQL(不仅仅仅是SQL)
关系型数据库:表格,行,列
泛指非关系型数据库的,随着web2.0互联网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区!暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!
NoSQL特点
解耦!
1、方便扩展(数据之间没有关系,很好扩展!)
2、大数据量高性能(Redis一秒写8万次,读取11万,NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高!)
3、数据类型是多样型的!(不需要事先设计数据库!随取随用!如果是数据量十分大的表,很多人就无法设计了!)
4、传统RDBMS和NoSQL
传统的RDBMS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中
- 操作操作,数据定义语言
- 严格的一致性
- 基础的事务
- ···
Nosq1
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
- 最终一致性,
- CAP定理和BASE(异地多活)初级架构师!
- 高性能,高可用,高可扩
- ···
3V+3高
大数据时代的3V:主要是描述问题的
1. 海量Volume
2. 多样Variety
3. 实时Velocity
大数据时代的3高:主要是对程序的要求
1. 高并发
2. 高可扩
3. 高性能
kv键值对
文档型数据库(Bson格式和Json一样)
列存储数据库
图关系数据库
标签:信息 产生 code alt 慢慢 cap 读写 nod 个人
原文地址:https://www.cnblogs.com/gcurry/p/13196258.html