标签:第一个 出错 打开 tran 直接 建立 包含 web浏览器 的区别
我们访问网站、使用App时,都是基于Web这种Browser/Server模式,简称B/S架构,它的特点是,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。Web页面具有极强的交互性。由于Web页面是用HTML编写的,而HTML具备超强的表现力,并且,服务器端升级后,客户端无需任何部署就可以使用到新的版本,因此,B/S架构升级非常容易。
在浏览网页时,我们首先会打开浏览器,输入网址,然后按下回车,接着浏览器就会显示出我们想要浏览的内容。那么,这背后到底发生了什么呢?
对于这一过程,概括来说,系统其实做了以下这些事情:
一个Web服务器往往也被称为HTTP服务器,它通过HTTP协议与客户端通信。Web服务器的工作原理可以简单的归纳为如下,其实和上面所说的系统处理过程是一致的。
我们浏览网页都是通过URL访问的,那么URL到底是怎么样的呢?
URL(Uniform Resource Locator)是“统一资源定位符”的英文缩写,用于描述一个网络上的资源, 基本格式如下:
scheme://host[:port#]/path/.../[?query-string][#anchor]
其中
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器端口(默认为80)。例如:http://www.cnblogs.com:8080/
path 访问资源的路径
query-string 发送给http服务器的数据
anchor 锚 // 这个不理解~
识别主机有两种方式,一个是主机名(比如localhost, www.baidu.com),一个是ip地址(比如192.0.0.6)。人们习惯记忆主机名,而路由器则需要规则统一的ip地址。DNS(Domain Name System,域名系统)就是将主机名转换为对应ip的一种服务,另外,要知道DNS是基于UDP协议实现的。从用户主机的角度讲,DNS是一个黑盒的服务。但事实上,这一转换背后发生了如下8个步骤。假定域名为m.xyz.com的主机想知道另一台主机(域名为y.abc.com)的ip地址,查询步骤如下:
这一过程如下图所示:
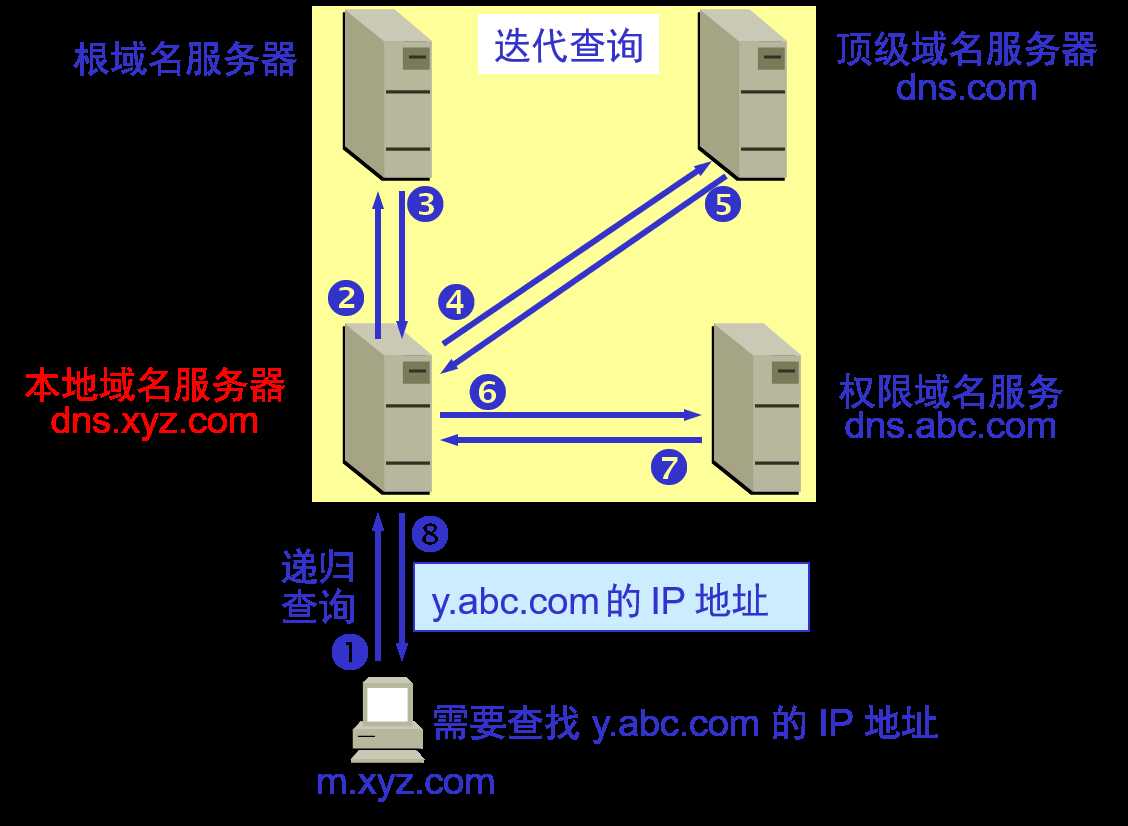
当然,如果每一次网络请求都要这样对域名进行解析势必会造成严重的延时,所以有DNS缓存(DNS caching)技术,比如上面的这次查询结束后,本地域名服务器(dns.zxy.com)就会缓存此次查询的结果,如果下次再有用户查询y.abc.com的ip地址,本地域名服务器就会立刻返回结果。
事实上,当在浏览器访问一个域名时,首先系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,即可完成域名解析;否则,查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析;如果再没有的话,会继续找TCP/IP参数中设置的首选DNS服务器(也就是上图中的本地DNS服务器),此服务器收到查询时,如果要查询的域名包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析。
说明:递归查询和迭代查询的区别。
递归查询:就是如果本地域名服务器没有所需域名的IP地址,本地域名服务器就以客户的方式向其他根域名服务器继续查询,而不是主机自己进行查询。
迭代查询:当某个域名服务器收到本地域名服务器的请求报文时,要么告诉它所需域名的IP地址,要么告诉它下一步应该向哪个服务器发起询问。然后让本地域名服务器自己去查询。
举个例子来说,你想知道某个一起上公共课的女孩的电话,并且你偷偷拍了她的照片,回到寝室告诉一个很仗义的哥们儿,这个哥们儿二话没说,拍着胸脯告诉你,甭急,我替你查(此处完成了一次递归查询,即,问询者的角色更替)。然后他拿着照片问了学院大四学长,学长告诉他,这姑娘是xx系的;然后这哥们儿马不停蹄又问了xx系的办公室主任助理同学,助理同学说是xx系yy班的,然后很仗义的哥们儿去xx系yy班的班长那里取到了该女孩儿电话。(此处完成若干次迭代查询,即,问询者角色不变,但反复更替问询对象)最后,他把号码交到了你手里。完成整个查询过程。
HTTP(HyperText Transfer Protocol:超文本传输协议)是一种应用层协议。HTTP协议是Web工作的核心,常用于在 Web 浏览器和网站服务器之间传递信息,以 http:// 打头的网站都是标准 HTTP 服务。它建立在TCP协议之上,一般采用TCP的80端口。它是一个请求-响应协议,即客户端发出一个请求,服务器响应这个请求(发起请求的只能是客户端,服务器不能主动联系客户端)。
HTTP协议是无状态的,也就是说,同一个客户端的这次请求和上次请求没有对应关系,对HTTP服务器来说,它并不知道这两个请求是否来自同一个客户端。为了解决这个问题, Web程序引入了Cookie机制来维护连接的可持续状态。此外,HTTP 协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如信用卡号、密码等支付信息。
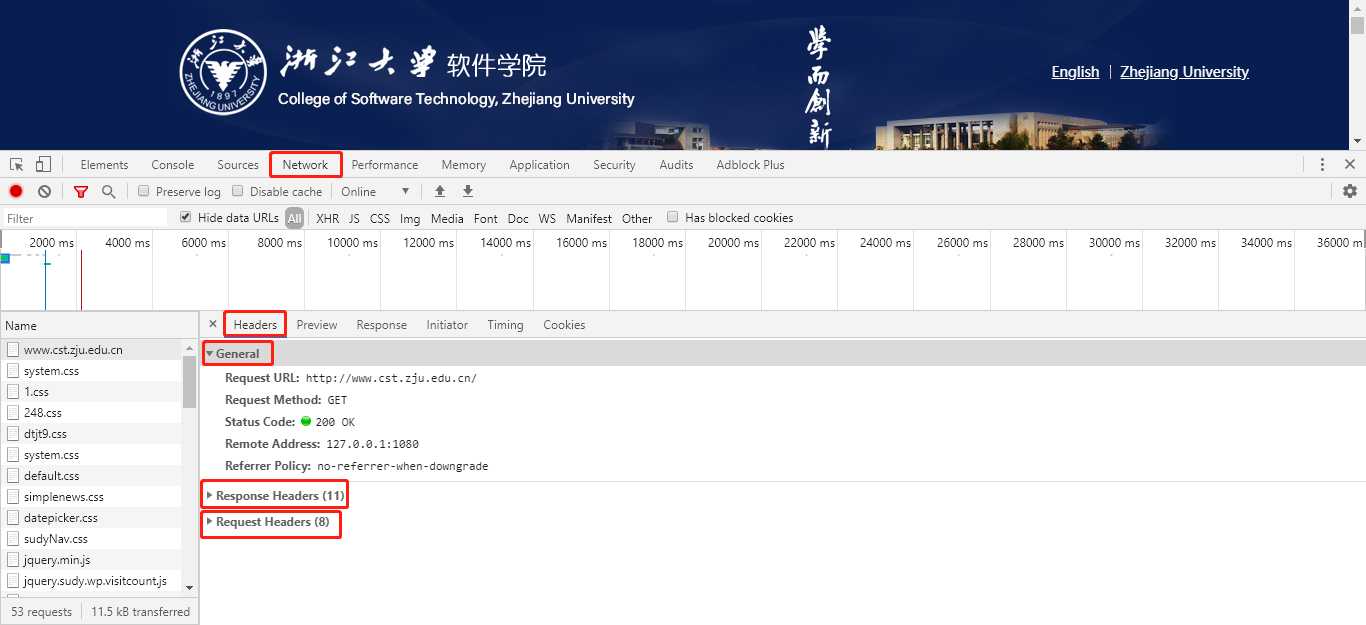
在浏览器的一个页面中,右击"检查"或直接按F12,即可看到如下。
在Elements下可以看到页面的HTML,切换到Network,重新加载页面,可以看到浏览器发出的每一个请求和响应,即Response Headers和Request Headers。
对于浏览器来说,请求页面的流程如下:
HTTP Request 包分为3部分,第一部分叫Request line(请求行),第二部分叫Request header(请求头),第三部分是body(主体)。请求头和消息体之间有个空行,用于分割请求头和消息体。
下面是一个HTTP Request Header示例:
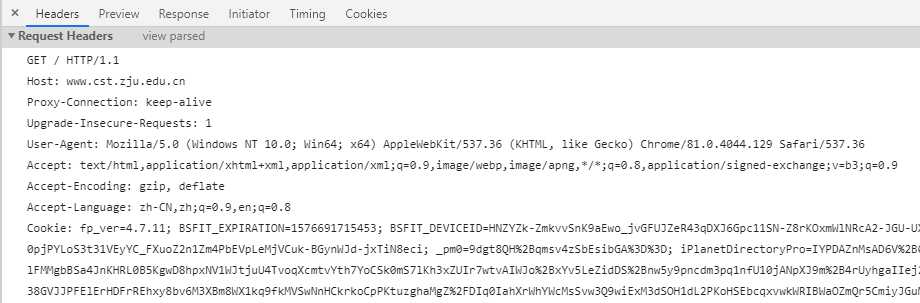
其中,第一行即请求行,GET是请求方法,请求获取路径为/的资源,并使用HTTP/1.1协议。从第二行开始,每行都是以Header: Value形式表示的HTTP头,比较常用的HTTP Header包括:
Mozilla/5.0 ... Chrome/79,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...) like Gecko;text/*,image/*或者*/*表示所有;gzip, deflate, br ;HTTP协议定义了很多与服务器交互的请求方法,最基本的有4种,分别是GET、POST、PUT、DELETE。一个URL用于描述网络上的一个资源,而HTTP中的GET、POST、PUT、DELETE就对应着对这个资源的查询、修改、添加和删除操作。其中最常见的就是GET和POST,GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。
这里有两个知识点,即GET和POST的区别?以及PUT和POST的区别?另外详见文章。
我们再来看看HTTP Response 包,它同样由状态行、消息头和消息体构成。下面是服务器响应的Response Header示例。
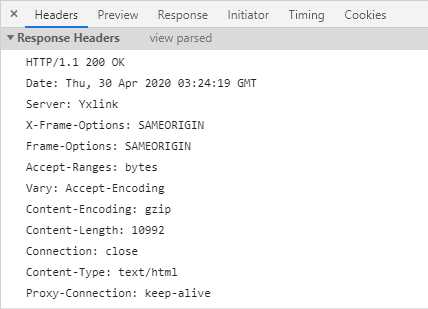
第一行是状态行,由HTTP/版本号,数字,文本3部分组成。数字表示状态码,其中2xx表示成功,3xx表示重定向,要完成请求必须进行更进一步的处理,4xx表示客户端引发的错误,5xx表示服务器端引发的错误。数字是给程序识别,文本则是给开发者调试使用的。常见的状态码有:
从第二行开始,服务器每一行均返回一个HTTP头。服务器经常返回的HTTP Header包括:
text/html,image/jpeg;gzip;max-age=300表示可以最多缓存300秒。HTTP请求和响应都由HTTP Header和HTTP Body构成,HTTP Header和HTTP Body之间会有一个空行。浏览器读取HTTP Body,并根据Header信息中指示的Content-Type、Content-Encoding等解压后显示网页、图像或其他内容。
通常浏览器获取的第一个资源是HTML网页,在网页中,如果嵌入了JavaScript、CSS、图片、视频等其他资源,浏览器会根据资源的URL再次向服务器请求对应的资源(异步请求)。
这里简述这3者的区别,详细的区别还有待深入学习。
(全文完)
参考:
标签:第一个 出错 打开 tran 直接 建立 包含 web浏览器 的区别
原文地址:https://www.cnblogs.com/kkbill/p/13198361.html