标签:span off http 拆分 业务 sel 应该 join mic
参数是子查询时,使用 EXISTS 代替 IN
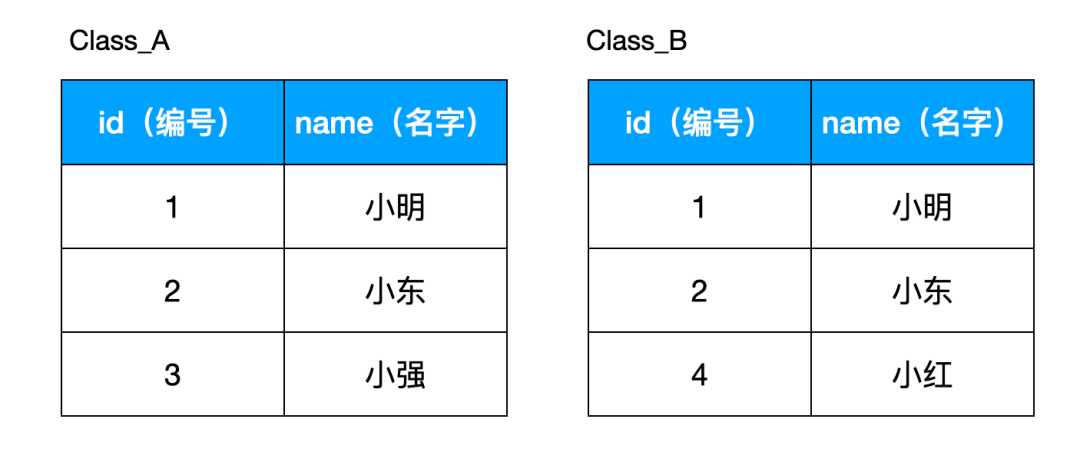
现在我们要查出同时存在于两个表的员工,即田中和铃木,则以下用 IN 和 EXISTS 返回的结果是一样,但是用 EXISTS 的 SQL 会更快:
-- 慢 SELECT * FROM Class_A WHERE id IN (SELECT id FROM CLASS_B); -- 快 SELECT * FROM Class_A A WHERE EXISTS (SELECT * FROM Class_B B WHERE A.id = B.id);
-- 使用连接代替 IN SELECT A.id, A.name FROM Class_A A INNER JOIN Class_B B ON A.id = B.id;
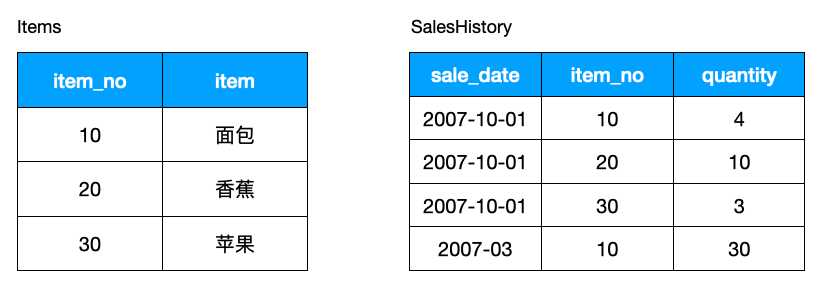
如何找出有销售记录的商品,使用如下 DISTINCT 可以:
SELECT DISTINCT I.item_no FROM Items I INNER JOIN SalesHistory SH ON I. item_no = SH. item_no; 不过更好的方式是使用 EXISTS: SELECT item_no FROM Items I WHERE EXISTS (SELECT * FROM SalesHistory SH WHERE I.item_no = SH.item_no);
-- 这样写需要扫描全表 SELECT MAX(item) FROM Items; -- 这样写能用到索引 SELECT MAX(item_no) FROM Items;
-- 聚合后使用 HAVING 子句过滤 SELECT sale_date, SUM(quantity) FROM SalesHistory GROUP BY sale_date HAVING sale_date = ‘2007-10-01‘; -- 聚合前使用 WHERE 子句过滤 SELECT sale_date, SUM(quantity) FROM SalesHistory WHERE sale_date = ‘2007-10-01‘ GROUP BY sale_date;
SELECT * FROM SomeTable WHERE col * 1.1 > 100; SELECT * FROM SomeTable WHERE SUBSTR(col, 1, 1) = ‘a‘;
SELECT * FROM SomeTable WHERE col_1 > 100 / 1.1;
SELECT * FROM SomeTable WHERE col_1 <> 100;
可以改成以下形式:
SELECT * FROM SomeTable WHERE col_1 > 100 or col_1 < 100;
SELECT * FROM (SELECT sale_date, MAX(quantity) AS max_qty FROM SalesHistory GROUP BY sale_date) TMP WHERE max_qty >= 10;
虽然上面这样的写法能达到目的,但会生成 TMP 这张临时表,所以应该使用下面这样的写法:
SELECT sale_date, MAX(quantity) FROM SalesHistory GROUP BY sale_date HAVING MAX(quantity) >= 10;
SELECT id, state, city FROM Addresses1 A1 WHERE state IN (SELECT state FROM Addresses2 A2 WHERE A1.id = A2.id) AND city IN (SELECT city FROM Addresses2 A2 WHERE A1.id = A2.id);
这段代码用到了两个子查询,也就产生了两个中间表,可以像下面这样写:
SELECT * FROM Addresses1 A1 WHERE id || state || city IN (SELECT id || state|| city FROM Addresses2 A2);
SELECT * FROM film LIMIT 100000, 10
SELECT <cols> FROM profiles inner join (SELECT id form FROM profiles where x.sex=‘M‘ order by rating limit 100000, 10) as x using(id);
SELECT first_name, last_name, homeroom_nbr FROM Students WHERE homeroom_nbr LIKE ‘A-1%‘;
推荐:
SELECT first_name, last_name homeroom_nbr FROM Students WHERE homeroom_nbr LIKE ‘A-1__‘; --模式字符串中包含了两个下划线
SELECT col_1, col_2 FROM SomeTable WHERE col_1 = xxx AND col_2 = xxx
不推荐用:
SELECT * FROM SomeTable WHERE col_1 = xxx AND col_2 = xxx
SELECT * FROM SomeTable WHERE `status` = 0 AND `gmt_create` > 1490025600 AND `gmt_create` < 1490630400 AND `id` > 0 AND `post_id` IN (‘67778‘, ‘67811‘, ‘67833‘, ‘67834‘, ‘67839‘, ‘67852‘, ‘67861‘, ‘67868‘, ‘67870‘, ‘67878‘, ‘67909‘, ‘67948‘, ‘67951‘, ‘67963‘, ‘67977‘, ‘67983‘, ‘67985‘, ‘67991‘, ‘68032‘, ‘68038‘/*... omitted 480 items ...*/) order by id asc limit 200;

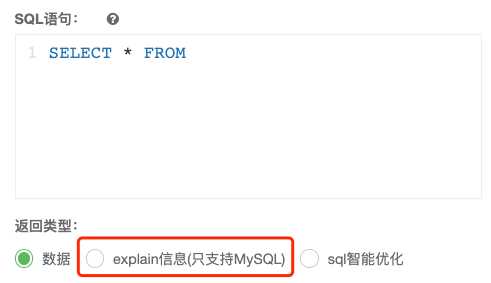
在提供 SQL 查询的同时,也贴心地加了一个 EXPLAIN 功能及 SQL 的优化建议,建议各大公司效仿,如图示:
-- 批量插入 INSERT INTO TABLE (id, user_id, title) VALUES (1, 2, ‘a‘),(2,3,‘b‘);
不推荐用:
INSERT INTO TABLE (id, user_id, title) VALUES (1, 2, ‘a‘); INSERT INTO TABLE (id, user_id, title) VALUES (2,3,‘b‘);
标签:span off http 拆分 业务 sel 应该 join mic
原文地址:https://www.cnblogs.com/garrett7/p/13204073.html