标签:直连 nbsp 并行处理 并发处理 线性 成本高 shard 系统 sql数据库
参考《人人都是架构师》
大型网站几乎时时刻刻都在接收着高并发和海量数据的洗礼,随着用户规模的线性上升,单库的性能瓶颈会逐渐暴露出来,由于数据的检索效率越来越慢,导致生产环境中产生较多的慢速SQL。对于非结构化数据,可以采用将其存储在NoSQL数据中来提升性能,但是重要的业务数据,仍然要落盘在关系型数据中。那么如果提升关系型数据的并发处理能力和检索效率就成为了架构师需要思考和解决的棘手问题,并且单库如果宕机,业务系统也就随之瘫痪了。因此在互联网场景下,架构师务必要确保后端存储系统具备高可用型和高性能,为了解决这些问题,目前互联网场景常用的做法便是对数据实施分库分表,即Sharding改造。
5.1关系型数据库的架构演变
互联网场景下,关系型数据库常见的性能瓶颈主要有两个:
大量的并发/读写操作,导致单数据库出现难以承受的负载压力;
单表存储数据量过大,导致检索效率低下。
5.1.1数据库读写分离
QPS:(Queries Per Second)每秒查询率。是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:(Transactions Per Second)每秒事务处理量。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
根据二八法则,80%的数据库操作都是读操作,只有20%的数据库操作是写操作。
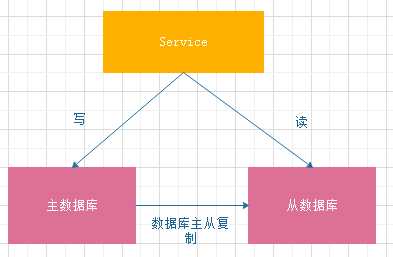
存在问题:从数据同步数据存在延迟(处理方式:在写入主数据后,同时将数据写入缓存)
5.1.2数据库垂直分库
垂直分库:企业根据自身业务垂直划分,将原本冗余的单数据中的数据表拆分到不同的业务库中,实现分而治之的数据管理和读/写操作。
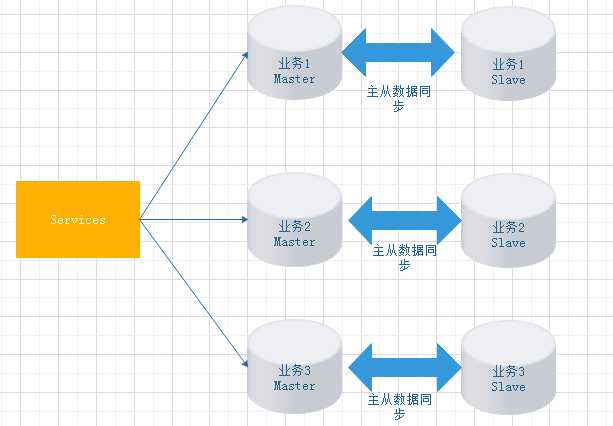
单一业务数据存储在单表上,当MySQL数据库单表超过500万,读操作逐渐成为瓶颈(重建索引也没有效果)。由于数据时顺序写,不会因为数据膨胀产生瓶颈。
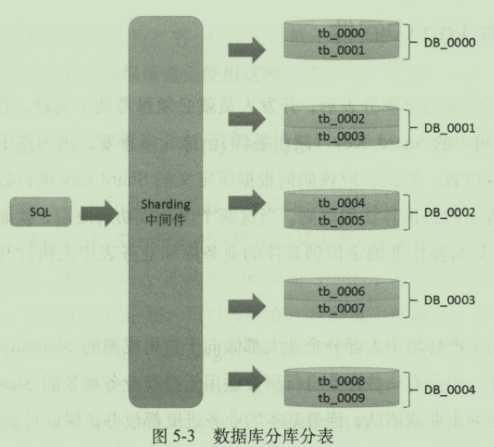
5.1.3数据库水平分库和水平分表
水平分表:将原本冗余在单库中的单个业务表拆分为n个“逻辑相关”的业务子系统(如tab_0000、tab_0001、tab_0002、tab_0003。。。),不同的业务子表各自负责存储不同区间的数据,对外形成一个整体,这就是大家常说Sharding操作。
水平分表后的业务字表可以包含在单库中,如果Master的TPS过高,则还可堆垂直分库后的单一业务数据进行水平化。
水平分库:可以将水平分表后的这些业务子表按照某种特定算法和规则分散到n个“逻辑相关”的业务子库中(如db_0000、db_0001、db_0002。。。)。实施相对复杂,并且还需要专门的Sharding中间件负责数据的路由工作。
5.1.4MySQL Sharding与MySQL Cluster的区别
MySQL Cluster:
优点:势只是扩展了数据库的并发处理能力;
缺点:只是一个数据库集群;优使用成本、维护成本高;实施负责。
MySQL Sharding:成熟且实惠的方案,不仅提升数据库的并行处理能力,还能够解决因为单表数据量过大产生的检索瓶颈。
总结:前者是集群模式,后者是分布式模式。
5.2Sharding中间件
一旦数据库实施分库分表后,开发人员就需要考虑两个问题。
首先,必须明确定义SQL语句中的Shard Key(路由条件),因为路由条件直接决定了数据的存储位置(非常重要)。
其次,应该如何根据所定义的Shard Key进行数据路由,这需要定义一套特定的路由算法和规则。

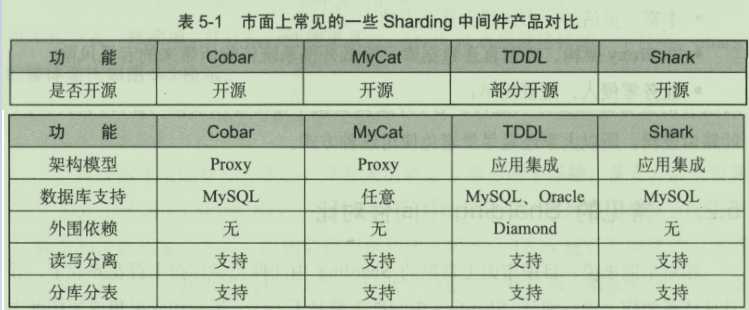
5.2.1常见的Sharding中间件对比
从架构角度划分,Sharding中间件主要有Proxy架构和应用集成架构两大类。
Proxy架构:可以灵活实现任意的关系型数据库协议,满足个性化定制,可以做到在一定程度上的通用,不限于任何数据库。
应用集成架构:尽快不能够实现通用性需求,但是由于应用直连数据库,读/写性能往往比前者高出10%~20%。
5.2.2Shark简介
5.2.3Shark架构模型
5.2.4使用Shark实现分库分表后的数据路由任务
5.2.5分库分表后所带来的影响


5.2.6多机SequenceID解决方案
5.2.7使用Solr满足多维度的迊条件查询
5.2.8关于分布式事务

最终一致性。
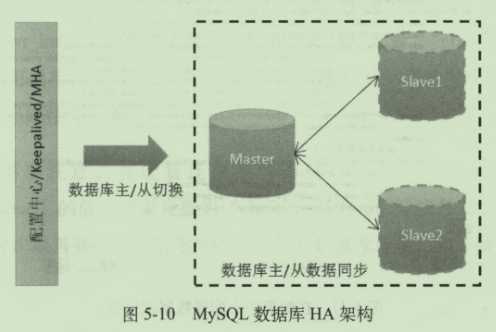
5.3数据库的HA方案

5.4订单业务冗余表需求
标签:直连 nbsp 并行处理 并发处理 线性 成本高 shard 系统 sql数据库
原文地址:https://www.cnblogs.com/wangymd/p/13205162.html