标签:require primary integer algorithm nal extend 作用 close fbo
java.util包下的内容是用得非常多的,而且也是面试必问的,我们先从用得非常多的ArrayList说起。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
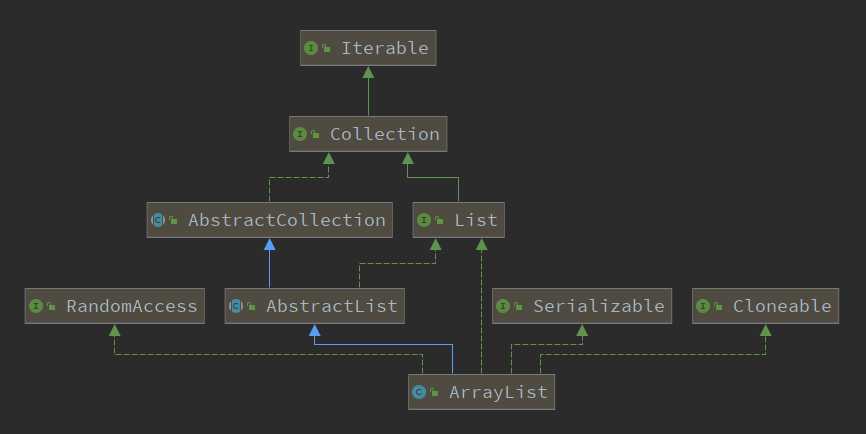
ArrayList是一个用数组实现的集合,元素有序且可重复。实现了RandomAccess接口,支持随机访问,实现了Cloneable,Serializable接口,表明可以拷贝和序列化。实现了List接口,表明支持List里定义的方法
至于RandomAccess接口很多同学可能不太了解,下面引用JDK API文档的描述:
Marker interface used by List implementations to indicate that they support fast (generally constant time) random access. The primary purpose of this interface is to allow generic algorithms to alter their behavior to provide good performance when applied to either random or sequential access lists.
大意就是这是一个标记接口,实现了RandomAccess接口就表明支持随机访问。此接口的主要目的是允许通用算法更改其行为,以便在应用于随机访问列表或顺序访问列表时提供良好的性能。
后一句话意思是我们通过判断是否实现了该接口来选择不同的遍历方式,因为实现了RandomAccess接口的集合,普通for循环比迭代器要快,这点官方文档也有说明:
for (int i=0, n=list.size(); i < n; i++)
list.get(i);
runs faster than this loop:
for (Iterator i=list.iterator(); i.hasNext(); )
i.next();
比如在Collections类里copy方法就实际运用了:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
// 这里判断了是否实现了RandomAccess,从而选择了不同的遍历方式
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
// 默认的初始容量
private static final int DEFAULT_CAPACITY = 10;
// 空的数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 这也是一个空的数组,和EMPTY_ELEMENTDATA的区别下面会讲到
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 这是ArrayList里真正存元素的数组,它的长度就是ArrayList的容量。为什么用transient修饰?下面会讲
transient Object[] elementData;
// ArrayList里元素的数量
private int size;
// 要分配的最大数组大小,一些虚拟机会在数组中保留一些header words。尝试分配更大的数组可能会导致OutOfMemoryError,所以这里-8
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 序列化的UID
private static final long serialVersionUID = 8683452581122892189L;
当使用有参构造函数并且初始容量为0时,将EMPTY_ELEMENTDATA赋值给elementData。当使用无参构造函数时,将DEFAULTCAPACITY_EMPTY_ELEMENTDATA赋值给elementData。
他们在第一次添加元素时扩容逻辑不同,EMPTY_ELEMENTDATA添加第一个元素后容量为1。DEFAULTCAPACITY_EMPTY_ELEMENTDATA添加第一个元素后容量为DEFAULT_CAPACITY = 10。
验证一下:
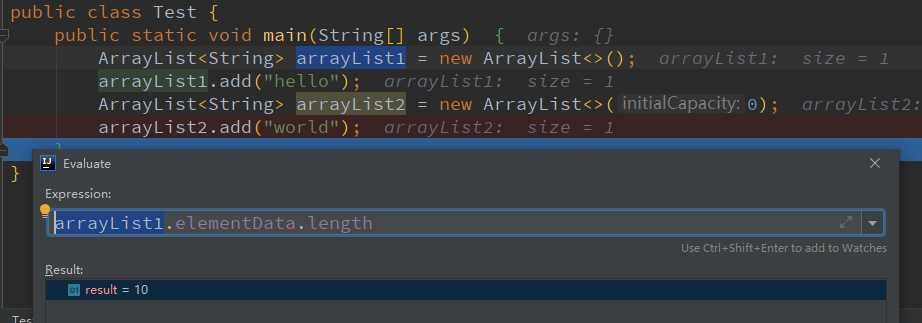
// 由于是无参构造函数,所以使用的是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,此时容量为0
ArrayList<String> arrayList1 = new ArrayList<>();
// 添加第一个元素时扩容为10,此时容量为10。注意此时size=1,不要将size和容量混淆。容量就好比一个水桶能装多少水,size就好比实际上装了多少水
arrayList1.add("hello");
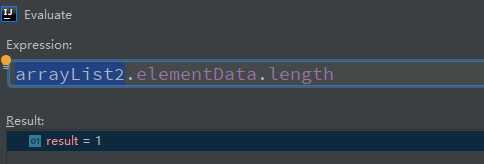
// 此时使用的是EMPTY_ELEMENTDATA,容量为0
ArrayList<String> arrayList2 = new ArrayList<>(0);
// 添加第一个元素时扩容为1,此时容量为1
arrayList2.add("world");
debug一下:
我们看到arrayList1的容量为10
arrayList2的容量为1
使用EMPTY_ELEMENTDATA 和 DEFAULTCAPACITY_EMPTY_ELEMENTDATA还有一个作用就是避免创建多余的空数组
我们知道elementData是真正存储元素的地方,用transient修饰就代表不能被序列化,那ArrayList序列化还有何意义?
支持序列化需要实现writeObject和readObject方法,真理就在这两个方法里:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
我们看到在序列化时将size和elementData里实际存在的元素写出,反序列化也就只需要反序列化实际存在的元素,提高了性能。为什么不直接将elementData序列化呢?
因为elementData的容量一般情况下大于里面实际存储的元素量,直接序列化浪费时间和空间。
/**
* 无参构造函数
*/
public ArrayList() {
// 将DEFAULTCAPACITY_EMPTY_ELEMENTDATA赋值给elementData,当第一次添加元素时,扩容为10
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 指定初始容量的构造函数
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 将EMPTY_ELEMENTDATA赋值给elementData,当第一次添加元素时,扩容为1
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 通过已有的集合创建ArrayList
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
四个添加元素的方法,分两类,一类是直接加,一类是带下标的加,主要逻辑差不多。我们分析下add(E e)方法,理解ArrayList添加元素的逻辑以及扩容的逻辑

/**
* add方法
*/
public boolean add(E e) {
// 确定下集合的大小(在往水桶里装水前得确认容量是否足够吧,不够的话就扩容喽)
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
/**
* 确定集合的大小
*/
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 这里可以证明new ArrayList()出来的集合,第一次添加元素时扩容为10(面试考点哦)
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
// modCount用于快速失败(fail-fast)机制
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
// 如果容量不够就扩容(这里没有hashMap里装载因子的概念哦,又是一个面试考点,哈哈)
grow(minCapacity);
}
/**
* 扩容方法(高频考点)
*/
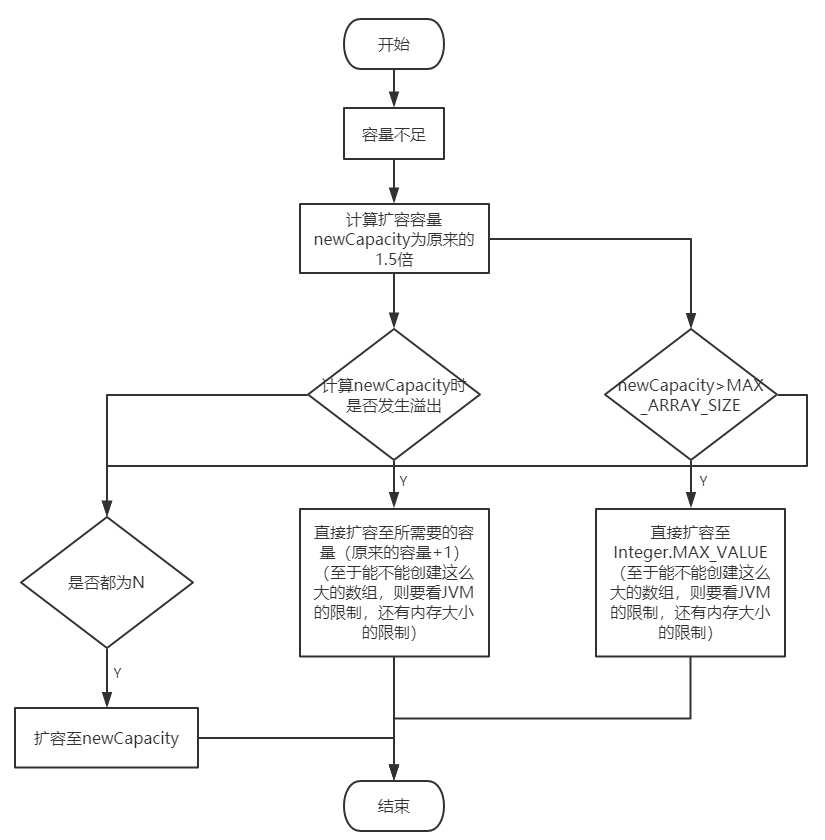
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 容量增加至原来的1.5倍(移位运算比乘除快,大家写代码可以借鉴)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
// 进入到这里,则代表计算newCapacity时发生了溢出,直接扩容为所需要的容量
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
// 当计算的新容量比MAX_ARRAY_SIZE还大时,则调用hugeCapacity处理
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 将原数组拷贝到长度为newCapacity的新数组里
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
// 当所需要的容量大于MAX_ARRAY_SIZE时,扩容为Integer.MAX_VALUE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
是不是有很多同学直接跳过了上面的代码?哈哈,这里总结下ArrayList的扩容机制:
/**
* 删除指定下标的元素
*/
public E remove(int index) {
// 检查下标是否越界
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
// 判断要删除的元素是否为最后一个元素
if (numMoved > 0)
// 将要删掉的元素后的所有元素往前移动一位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将最后一个元素设为null,方便垃圾回收
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
/**
* 删除指定的元素(注意这里只会删除第一次匹配到的该元素)
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/**
* 删除与传入的集合里相同的元素
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
/**
* 删除符合条件的元素
*/
public boolean removeIf(Predicate<? super E> filter) {
// 太多我就不贴了
}
/**
* 删除指定下标之间的元素(protected修饰,我们一般用不到)
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 修改指定下标的元素
*/
public E set(int index, E element) {
// 检查下标是否越界
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
/**
* 根据下标查询元素
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
JDK1.8-java.util.ArrayList类源码阅读
标签:require primary integer algorithm nal extend 作用 close fbo
原文地址:https://www.cnblogs.com/liuwhut/p/13204691.html