标签:通用 功能 url nec code strong turn layer cat
功能:爬取梨视频科技栏最热的几个视频。
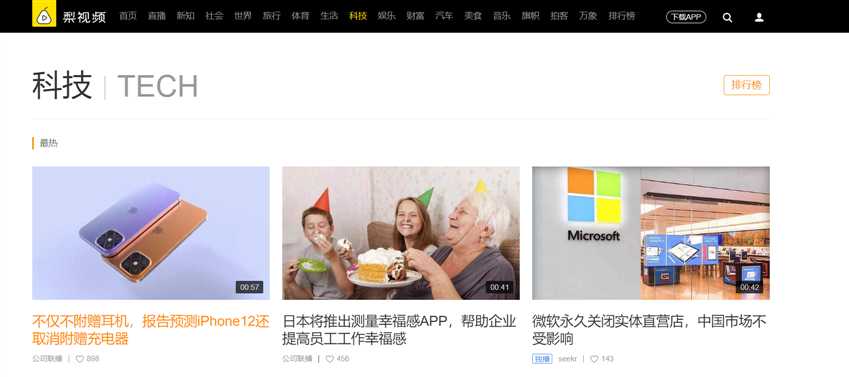
1. 找到视频对应的通用标签
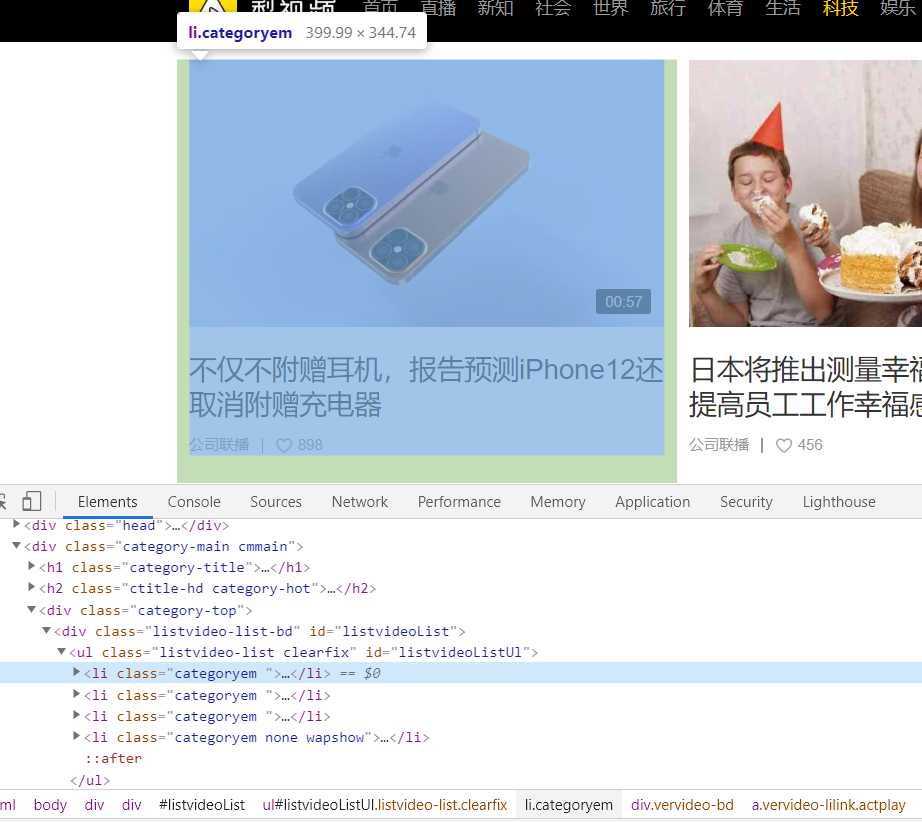
可以看出关于视频的信息都存放在li标签中
2. 拿到视频的名称以及对应的url
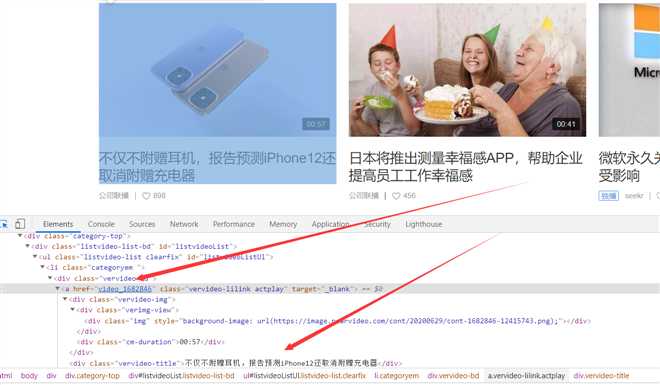
3.进入Video的url,找到视频信息的地址
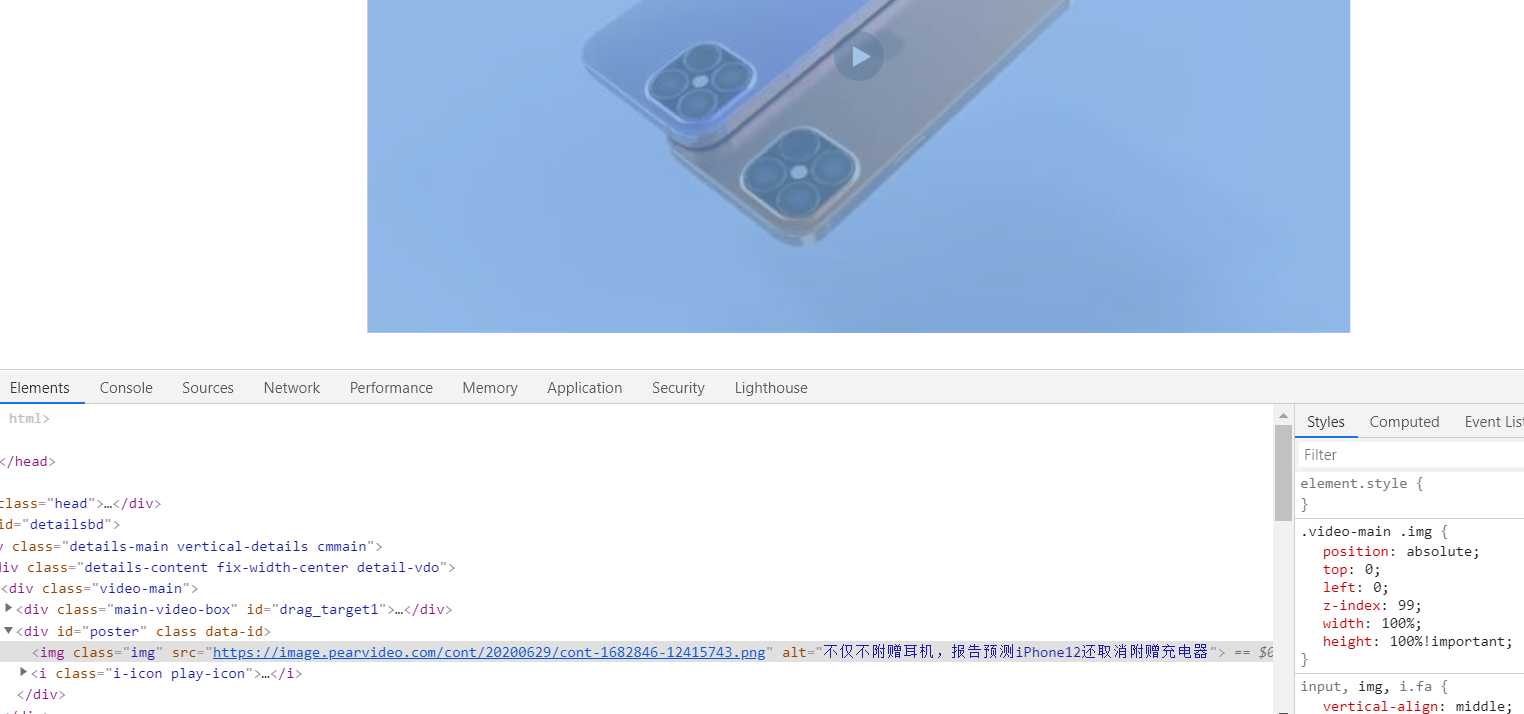
你会发现没有这个视频的url,那么说明这个视频可能是动态加载出来的。
4. 打开抓包工具,找到视频对应的包,对其Response进行搜索。
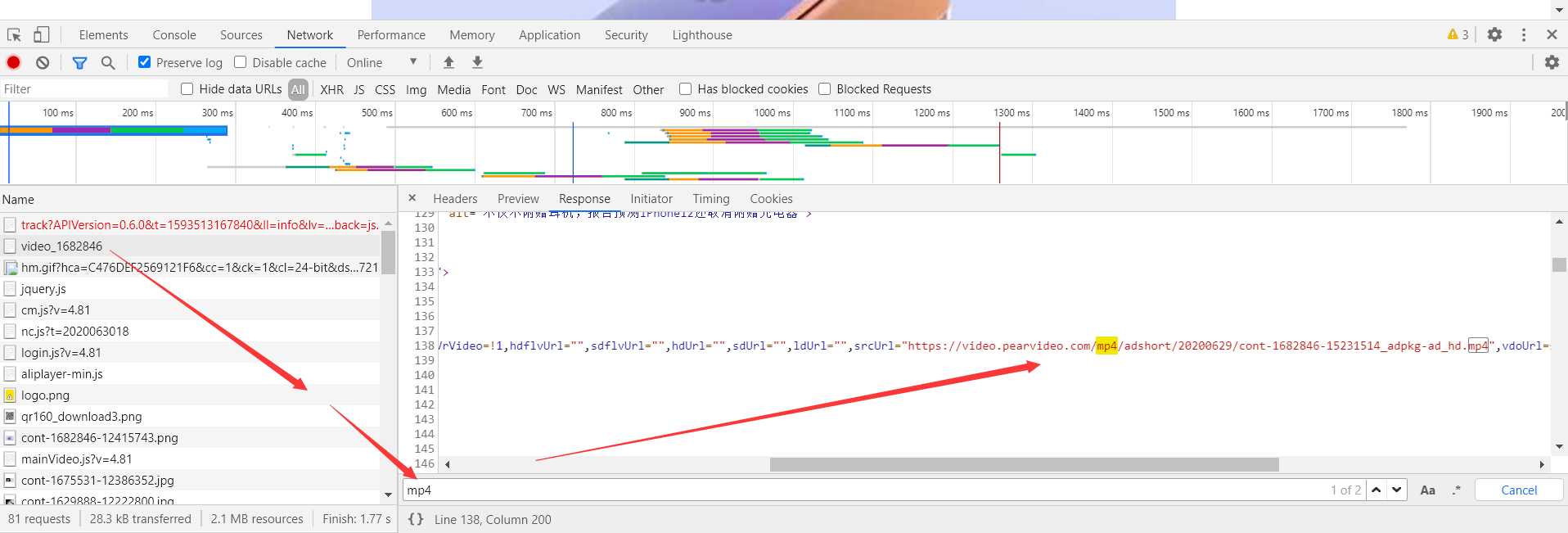
通过搜索,我们发现了视频的url在script标签中,那么我们可以通过正则表达式来获取视频的url
5.思路:找到视频对应的详情页url,在详情页的数据中通过正则获取视频的url.
6.代码编写
import requests from lxml import etree import re from multiprocessing.dummy import Pool def get_video_data(video_data): """获取视频文件""" data = session.get(video_data[‘url‘],headers=headers).content dic = {‘name‘:video_data[‘name‘], ‘data‘:data} return dic def write(data): """持久化存储""" with open(data[‘name‘]+‘.mp4‘,‘wb‘) as f: f.write(data[‘data‘]) url = ‘https://www.pearvideo.com/category_8‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36‘, ‘Connection‘: ‘close‘ } session = requests.session() page_text = session.get(url=url, headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath("//ul[@id=‘listvideoListUl‘]/li") video_urls = [] for li in li_list: src = ‘https://www.pearvideo.com/‘ + li.xpath(‘./div/a/@href‘)[0] name = li.xpath(‘./div/a/div[2]/text()‘)[0] detail_text = session.get(url=src, headers=headers).text # print(tree_2.xpath(‘//*[@id= "JprismPlayer"]/video/@src‘)) 结果为空 说明数据是动态加载 # 在Response中搜索mp4 得到视频对应的链接地址 在script语句中 因为用re # srcUrl="https://video.pearvideo.com/mp4/third/20200617/cont-1680618-10008579-104906-hd.mp4",vdoUrl=srcUrl ex = r‘srcUrl="(.*?)",vdoUrl=srcUrl‘ video_src = re.findall(ex, detail_text)[0]
# 将视频数据存放在字典中 dic = { ‘name‘: name, ‘url‘: video_src } video_urls.append(dic) # 用于获取视频信息 pool = Pool(4) ret = pool.map(get_video_data, video_urls) # 用于持久化存储 pool_2 = Pool(4) pool_2.map(write,ret) # 关闭线程池 pool.close() pool_2.close() # 等待主进程结束 pool.join() pool_2.join()
(四)基于multiprocessing.dummy线程池爬取梨视频的视频信息
标签:通用 功能 url nec code strong turn layer cat
原文地址:https://www.cnblogs.com/sxy-blog/p/13215368.html