标签:优化 内容 commit 支持 size break llb not 反序
MetaQ是一款高性能的消息中间件,经过几年的发展,已经非常成熟稳定,历经多年双11的零点峰值压测,表现堪称完美。
MetaQ当前最新最稳定的稳本是3.x系统,MetaQ 3.x重新设计和实现,比之前的版本更优秀。虽然MetaQ借鉴了linkedin 的消息中间件kafak思想,但已经是青出于蓝而胜于蓝。
本文不对MetaQ做全面的介绍,只选择高性能这点来分析。
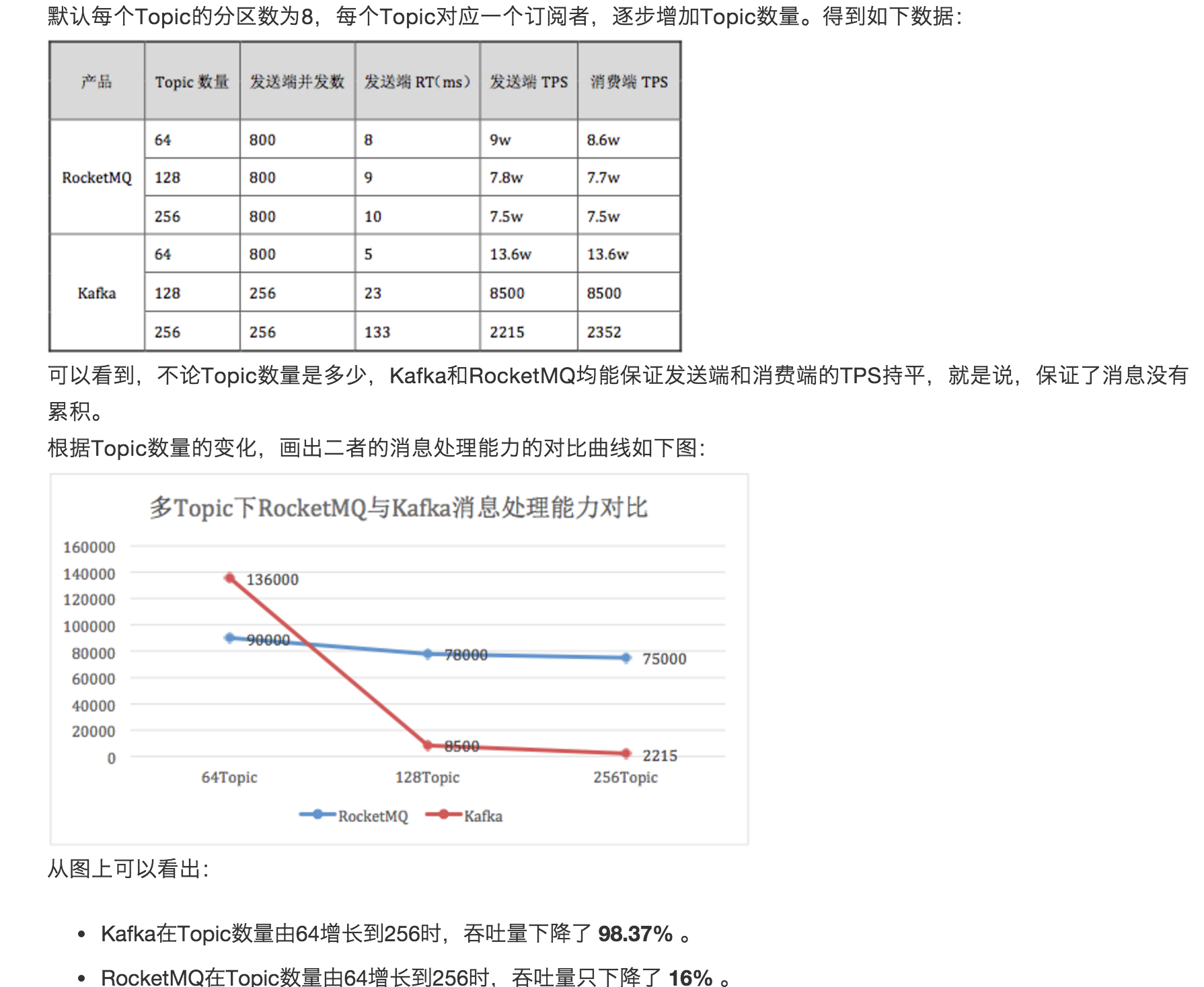
以上测试图片,来自消息测中间件试团队 @以夕 妹子的性能测试结果
MetaQ作为一款消息中间件,消息中间件该有的功能,MetaQ也有。本文并不全面介绍MetaQ方面方面,只是选取性能这一角度,来剖析其高性能的原因。
MetaQ Server
最为核心的组件,它主要可以接收应用程序发送过来的消息并存储,然后再投递。
MetaQ Master
是MetaQ Server逻辑上的角色,和MySQL Master概念类型,对外提供发送消息、订阅消息以及维护着管理信息。
MetaQ Slave
是MetaQ Server逻辑上的角色,和MySQL Slave概念类型,对外提供订阅消息功能。
MetaQ Client
主要是应用程序使用,使用MetaQ Client来发送消息、订阅消息、其它控制信息。
其它无数据管理及控制信息组件
提供订阅关系管理功能,MetaQ Server服务发现功能。
MetaQ Client 发送消息,MetaQ Server收到消息,并存储到文件系统。也就是说MetaQ会有大量write系统调用。
MetaQ Client 订阅消息,因其是Pull的模型。MetaQ Server收到Pull消息的请求,会从磁盘上读取出消息,然后返回给MetaQ Client。这一步有大量的read系统调用。
从上面的功能上看,Metaq Server要支持大量的磁盘IO操作,因为其是构建文件系统之上的消息中间件。既然使用了文件系统来存储数据,但磁盘QPS每秒也就是几百。MetaQ Server又必须高性能(如MetaQ Server性能是10W级别的QPS),才能在可接收的成本范围内,满足业务需求(不丢消息)。如何在QPS只有几百的磁盘上,构建出一个高性能的MetaQ消息间件正是本文的中心。
前面介绍了MetaQ高性能的难点,那么我们如何解决这些难点。要解决这些难点,就必须找出这些难点。那么要写一个高性能的消息中间件,会有哪些会部分会对影响性能。
从MetaQ Cleint要发送消息,必须要先序列化,然后才能通过网络发送出去。 MetaQ Server收到消息后,要进行反序列化,才能解析出消息内容,最后序列化存储到文件系统。
MetaQ Client收到消息,首页MetaQ Server必须从文件中读取消息,然后通过网络发送给MetaQ Client,收到消息,进行反序列化,应用才能识别消息内容。
MetaQ核心功能,都要通过序列化与反序列化,所以其性能,对MetaQ性能有关键性的影响,其实不是对MetaQ,只要使用了序列化与反序列化,其对性能影响都很大。
因为MetaQ Server会有大量的write系统调用 ,所以其性能对MetaQ性能有着重要的影响。
因为MetaQ Server会有大量的read系统调用 ,所以其性能对MetaQ性能有着重要的影响。
因为发送消息,订阅消息都必须经过网络,如果网络组件性能不好,对MetaQ性能有着关键的影响。
要解决序列化与反序列化性能问题,我们就必须寻种各种序列化与反序列化技术性能对比,从而选出一个高性能的序列化与反序列化技术来作为MetaQ。
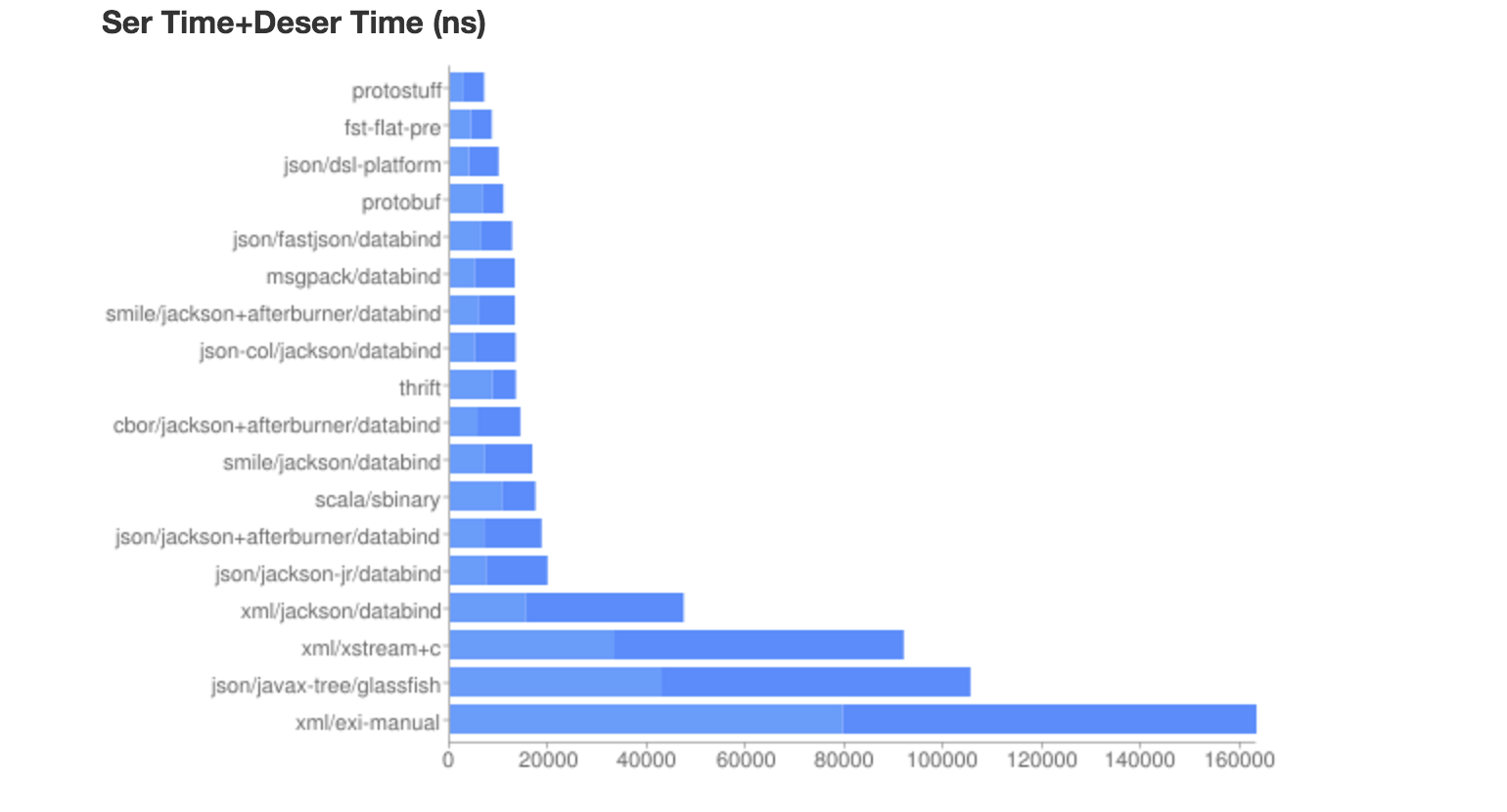
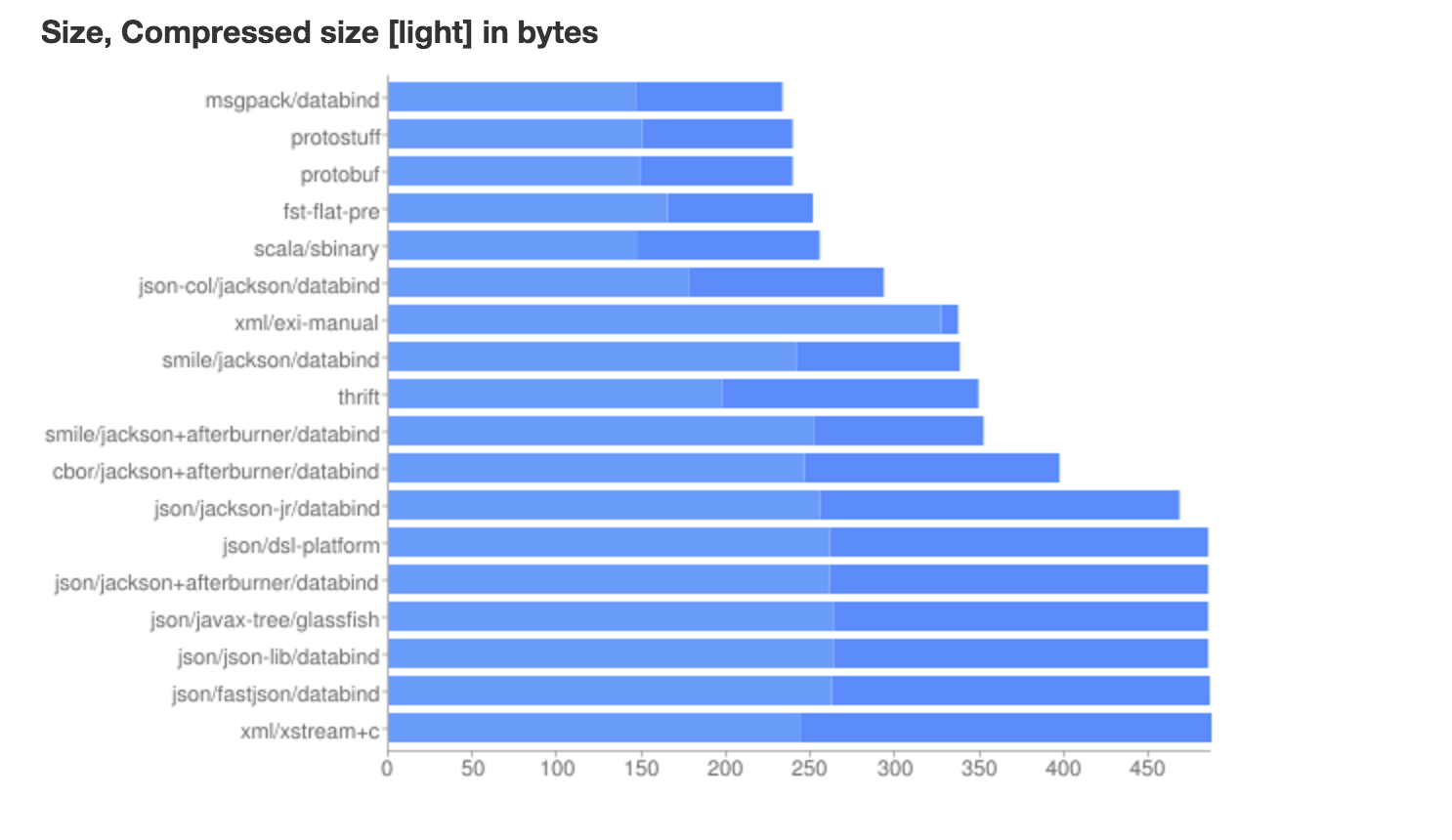
我们来看下Java世界可以选择的序列化与反序列化技术
从图中性能数据,可以看出,个人认为Google出品的Protocol Buffers应该是最佳选择,不管软件的质量、社区活跃、软件的后续发展上来说,都是不错的选择。
但MetaQ并没有选择Protocol Buffers作为其序列化与反序列化的技术,一个原因是Protocol Buffers居然在小版之间本都不兼容,2.3和2.5的版本都不兼容。这会带来一个严重的问题,如果MetaQ选择2.3的版本,应用程序选择了2.5,都会导致冲突,反之亦然。
MetaQ消息元数据是通过JSON来序列化与反序列化,消息Body是交给应用自己序列化与反序列化。
虽然使用Protocol Buffers性能会更好,但带给用户带来麻烦。所以MetaQ选择使用JSON。
前面也已经介绍了,MetaQ Server 存大大量的IO,那么怎么优化呢?
read优化主要是使用了mmap文件映射技术。这样可以减少系统上下文切换和复制数据的开销。。
同时文件系统提供了文件预读的功能,也使的读取文件开销,特别是顺序读时,开销比较低。
前面也介绍了,write可能存在并发问题,那么MetaQ是如何解决的?
MetaQ消息只保留在一个物理文件上,所有的消息都会写一个物理文件,每个物理文件都是固定大小,超过设置的阀值后,自动创建新的一个文件。当磁盘快满时,会自动删除老的文件。
Group Commit也就是组提交,组提交是指可以多次分写请求只要通过一次刷新数据,就可以实现这些请求的数据都已刷新到磁盘上。
MySQL数据库能保证ACID,事务提交也使用了Group Commit来提高性能(为了保证D,数据需要持久化到文件系统)。
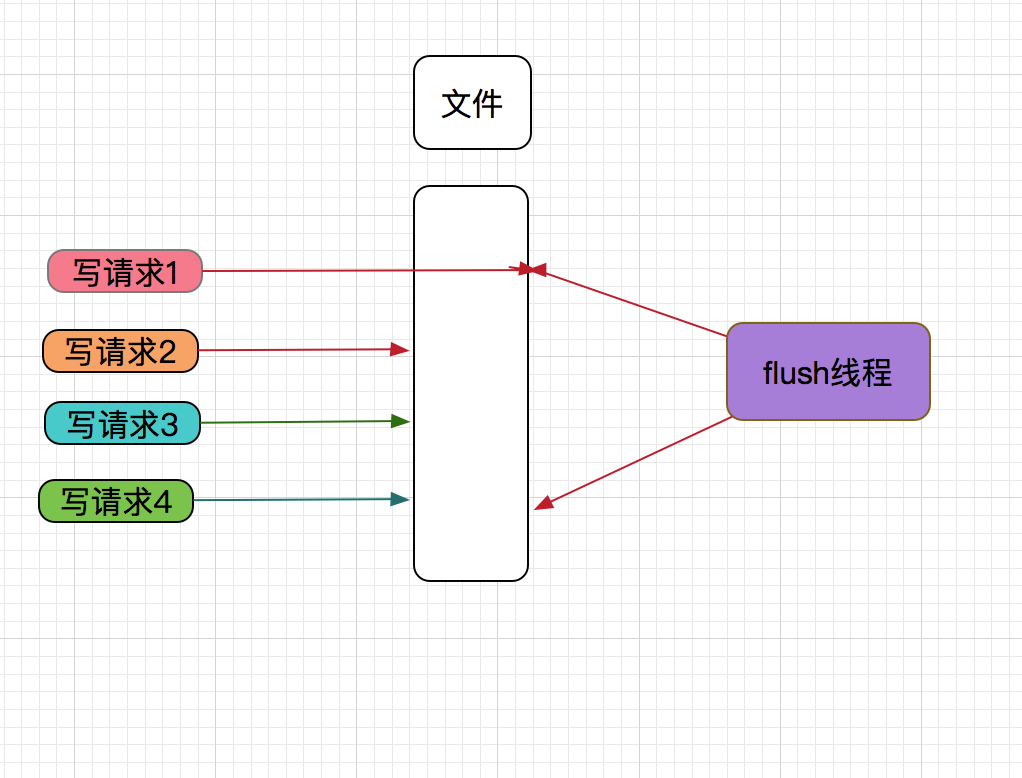
详细见下图
当写请求1到MetaQ Server时,把线程写入内核后,触发flush线程刷新数据到磁盘,以保证数据的可靠性。
然后再向MetaQ Client 响应发送消息成功。这个时间,只要文件系统和磁盘不损坏,数据是不会丢失的。
正在flush线程要准备刷新数据时,写请求2,写请求3,写请求4也到MetaQ Server且写入数据,这样因写请求1写数据,触发的flush顺便也把写请求2,写请求3,写请求4的数据也刷新到磁盘。这样减少了刷新磁盘的次数,性能自然就高了,同时也保证的数据的可靠性。
如何实现Group Commit,请看源码
// Synchronization flush
if (FlushDiskType.SYNC_FLUSH == this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (msg.isWaitStoreMsgOK()) {
request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
service.putRequest(request);
boolean flushOK =
request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig()
.getSyncFlushTimeout());
if (!flushOK) {
log.error("do groupcommit, wait for flush failed, topic: " + msg.getTopic() + " tags: "
+ msg.getTags() + " client address: " + msg.getBornHostString());
putMessageResult.setPutMessageStatus(PutMessageStatus.FLUSH_DISK_TIMEOUT);
}
}
else {
service.wakeup();
}
}
// Asynchronous flush
else {
this.flushCommitLogService.wakeup();
}
并发安全
write如何保证并发安全,在写数据前,需要抢占一个锁,因为这只是把数据写到文件系统缓存中,所以持有锁的时间非常短,对性能友好。请看代码
synchronized (this) {
long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();
// Here settings are stored timestamp, in order to ensure an orderly
// global
msg.setStoreTimestamp(beginLockTimestamp);
MapedFile mapedFile = this.mapedFileQueue.getLastMapedFile();
if (null == mapedFile) {
log.error("create maped file1 error, topic: " + msg.getTopic() + " clientAddr: "
+ msg.getBornHostString());
return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, null);
}
result = mapedFile.appendMessage(msg, this.appendMessageCallback);
switch (result.getStatus()) {
case PUT_OK:
break;
case END_OF_FILE:
// Create a new file, re-write the message
mapedFile = this.mapedFileQueue.getLastMapedFile();
if (null == mapedFile) {
// XXX: warn and notify me
log.error("create maped file2 error, topic: " + msg.getTopic() + " clientAddr: "
+ msg.getBornHostString());
return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, result);
}
result = mapedFile.appendMessage(msg, this.appendMessageCallback);
break;
case MESSAGE_SIZE_EXCEEDED:
return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, result);
case UNKNOWN_ERROR:
return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
default:
return new PutMessageResult(PutMessageStatus.UNKNOWN_ERROR, result);
}
DispatchRequest dispatchRequest = new DispatchRequest(//
topic,// 1
queueId,// 2
result.getWroteOffset(),// 3
result.getWroteBytes(),// 4
tagsCode,// 5
msg.getStoreTimestamp(),// 6
result.getLogicsOffset(),// 7
msg.getKeys(),// 8
/**
* Transaction
*/
msg.getSysFlag(),// 9
msg.getPreparedTransactionOffset());// 10
this.defaultMessageStore.putDispatchRequest(dispatchRequest);
eclipseTimeInLock = this.defaultMessageStore.getSystemClock().now() - beginLockTimestamp;
} // end of synchronized
MetaQ的网络框架,选择了Netty4。Netty4因出色的性能和易用性,成为高性能场景的不二选择。
转自:https://www.cnblogs.com/felixzh/p/6197707.html
标签:优化 内容 commit 支持 size break llb not 反序
原文地址:https://www.cnblogs.com/itplay/p/13218911.html