标签:计算机语言 规则 默认值 index 简历 公司 字符串 缩减 招聘
已经使用python很久了,但是总感觉差了点,具体并不知道是什么问题,所以开个拾遗博客来捡一些在使用python中忽略的细节,并简单的总结归纳,希望能得到提升.
内容涵盖点:
1.主要是我自己一眼看不懂的;
2.我自己感觉新颖的;
3.杂七杂八的概念或方法...
开始:
一.什么是python(这个是本篇博客最重要的)
python:
一门典型的解释型语言,即运行代码时从上到下逐行解释并执行,遇错则GG.
因其具有良好的跨平台性和友好的上手能力(有手就行)而被我国(China)着重推广,个人认为,普及python比普及英语有用的多(学习和工作)balabala...(万字吹B省略)
骚话不多说,回归正题.
我经常问自己,为什么学python.
很多人说把python当做计算机第一语言并不好,学完python就去找工作会相对其它计算机语言学习者来说劣势很大.哼哼,说这些话的人肯定不了解python,在鄙人看
来,学完python之后根本就找不到工作......今天已经不是4\5年前那样会print(‘abc‘)就可以直接拉走的时代了,python因易上手而导致竞争压力加大很正常.python的应用
广泛(上天入地毫不夸张)是事实,python人才缺口很大是事实,但是找不到工作同样是事实.所以是出了什么问题?以下简单描述我所认知的:
1.python语言本身
python自带GIL,python速度慢.python算法不友好等等等等,说python不好的人总会指出python一大堆毛病,通通指向python底层构建,三言两语就把python说成
垃圾乐色,甚至有的话锋一转,说这里有最新极其火爆XX语言学习课程,原价9999,现价9.9,快扫我,快扫我...我承认,使用python以来很少去了解其底层构建,所以这些
垃圾话对我杀伤力相当大,很容易产生自我怀疑,然后有莫名的紧张感,甚至有冲动去搞一搞java(java当第一语言确实很推荐).
其实等冷静下来会发现是庸人自扰,一切的源头不过来自于自身的知识的浅薄和对自己的不肯定.对于很多和我一样曾经怀疑过python的人,我只想说,继续学习
吧,我们的选择其实并没有错!
2.python联动
你简历上只写精通python不一定有公司要,但是你写熟练掌握python+数据库+前端+excel+...这些肯定大把公司要.
你在学习python的过程中,不要忘了,远在国外的前辈们早已为你打开了通往其他各种应用的接口,你只需要import就完事了.
同时,多看看import模块中的代码,不需要完全掌握,开开眼界总是好的.
3.python工作岗位
打开招聘网站,web岗位和爬虫岗位最多,人工智能和数据挖掘给钱最多,数据分析人才需求最大......你是没人要,还是不愿去,还是去不了,只有自己心里明白.
4.python之禅(背下来吧)
open your python,please input: import this.
总结一下: 瞄准方向,严格要求,学习下去,未来可期.
二.代码知识储备开始
1.字符串: find和index的区别: find找不到返回-1,index找不到直接报错.
2.int(" 5 ")输出为整数5,可自动去除左右空格.
3.列表更改元素值:

1 ll = [1, 2, 3, 5, 6, 7, ‘kkkk‘] 2 ll[1:6:2] = ‘abc‘ # 根据步长来更改列表元素,需要一一对应 3 print(ll) # [1, ‘a‘, 3, ‘b‘, 6, ‘c‘, ‘kkkk‘]
4.字典更新:
dict.update(new_dict)
或
dict.update(key=value)
5.字典推导式: dict = {key value for key, value in items}
6.小数据池:(左:python自带解释器,右:pycharm)
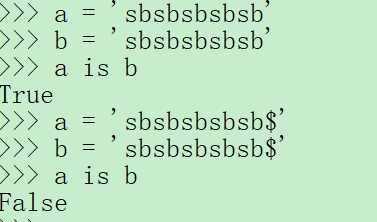
在python自带解释器中每一行命令为一个代码块,而在pycharm中一整个文件为一个代码块.
而python内存中自带小数据池: 数字-5~256,一定规则字符串和布尔值.
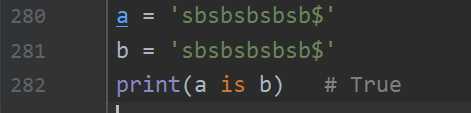
所以当a和b为相同字符串时,即使a,b属于不同代码块,仍然属于同一小数据池,id值是一样的,所以用is进行判断时,返回值仍为True.而加了"$"后,超出小数据池范围,返回False.
在pycharm中a,b同属于一个代码块,其将变量名和值的对应关系存放于字典中,类似: dict = {‘name‘: ‘value‘的内存地址},当碰到同样对象初始化命令时,直接到字典中取.
7.集合: 集合中元素必须为不可变的元素.(集合用的少,这个规则竟然忘了...)
字典和集合的背后都是散列表,上面说的不可变的元素必然为可散列的. (摘自‘流畅的python‘)
可散列对象:
a.支持hash,通过__hash__()得到散列值不变;
b.支持通过__eq__()来检测相等性;
c.若a==b为真,则hash(a)==hash(b)也为真;
字典和集合都十分消耗内存.(散列表又叫稀疏数组: 总有空白元素的数组,空间使用效率低下)
8.函数传参: *args和**kwargs的集合作用
def func(*args, **kwargs):
print(args, kwargs)
func(*(1,2,3),*(4,5,6),**{‘1‘:2}, **{‘3‘:4}) # (2, 3, 4, 5, 6) {‘1‘: 2, ‘3‘: 4} 这样使用字典键必须为字符串
9.匿名函数lambda:
lambda x: x # 传入x,返回x def func(x): return x
lambda : x # 不传人,直接返回x def func(): return x(这种用法蛮脑残的...)
10.高阶函数: filter, map, reduce... 传入函数,返回函数(装B利器,忽悠小白专用)
高阶函数对人类不友好!可以在代码优化时使用,但是请务必保存优化前代码,看不懂自己写的高阶函数代码很正常...
简单各写一个例子:
filter:
list(filter(lambda x: x>2, [1,2,3,4,5])) # [3, 4, 5] 筛选列表中大于2的元素,并组成列表
map:
list(map(lambda x: x>2, [1,2,3,4,5])) # [False, False, True, True, True] 上下对比一下应该能看出区别
reduce:(from functools import reduce)
这玩意在python3中用的较少,着重介绍一下吧,以免别人装B时我们一脸懵B.
描述: reduce(function, sequence[, initial]) -> value
用法机翻:
将包含两个参数的函数累计应用于序列的项,
从左到右,从而将序列缩减为单个值。
例如,reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) 运算为((((1 + 2)+ (3)+ 4)+ 5)。
如果存在initial,则在计算中将其放在序列的项之前,并在序列为空时作为默认值。
reduce(lambda x, y: x+y, [1, 2, 3, 4, 5], 6) # 21,initial值为6
标签:计算机语言 规则 默认值 index 简历 公司 字符串 缩减 招聘
原文地址:https://www.cnblogs.com/gexiaotian/p/13227037.html
