标签:篡改 osal 描述 编号 任务 相同 重复 技术 初始
Paxos算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致。 面试的时候:不要把这个Paxos算法达到的目的和分布式事务联系起来,而是针对Zookeeper这样的master-slave集群对某个决议达成一致,也就是副本之间写或者leader选举达成一致。我觉得这个算法和狭义的分布式事务不是一样的。
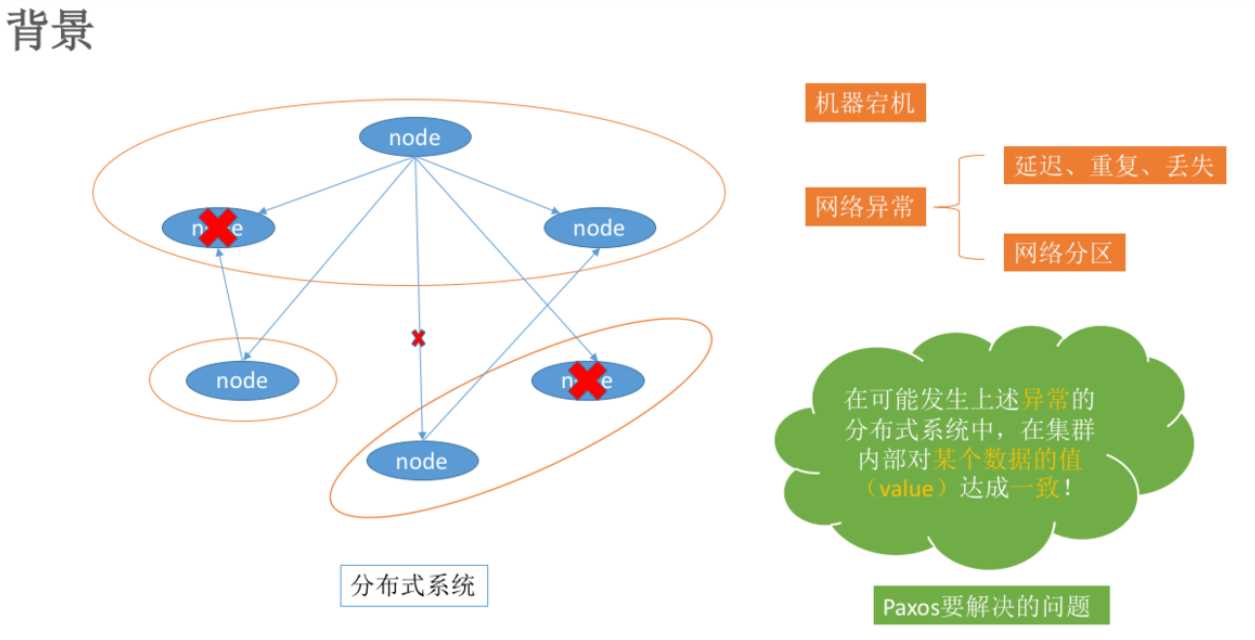
在常见的分布式系统中,总会发生诸如机器宕机或网络异常(包括消息的延迟、丢失、重复、乱序,还有网络分区)(也就是会发生异常的分布式系统)等情况。Paxos算法需要解决的问题就是如何在一个可能发生上述异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致。也可以理解成分布式系统中达成状态的一致性。
这里某个数据的值并不只是狭义上的某个数,它可以是一条日志,也可以是一条命令(command)。根据应用场景不同,某个数据的值有不同的含义。
Paxos 算法是分布式一致性算法用来解决一个分布式系统如何就某个值(决议)达成一致的问题。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个”一致性算法”以保证每个节点看到的指令一致。
分布式系统中一般是通过多副本来保证可靠性,而多个副本之间会存在数据不一致的情况。所以必须有一个一致性算法来保证数据的一致,描述如下:
假如在分布式系统中初始是各个节点的数据是一致的,每个节点都顺序执行系列操作,然后每个节点最终的数据还是一致的。
Paxos算法就是解决这种分布式场景中的一致性问题。对于一般的开发人员来说,只需要知道paxos是一个分布式选举算法即可。多个节点之间存在两种通讯模型:共享内存(Shared memory)、消息传递(Messages passing),Paxos是基于消息传递的通讯模型的。
拜占庭将军问题:是指拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,只能依靠通讯员进行传递命令,但是通讯员中存在叛徒,它们可以篡改消息,叛徒可以欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。
Paxos算法的前提假设是不存在拜占庭将军问题,即:信道是安全的(信道可靠),发出的信号不会被篡改,因为Paxos算法是基于消息传递的。此问题由Lamport提出,它也是 Paxos算法的提出者。 从理论上来说,在分布式计算领域,试图在异步系统和不可靠信道上来达到一致性状态是不可能的。因此在对一致性的研究过程中,都往往假设信道是可靠的,而事实上,大多数系统都是部署在一个局域网中,因此消息被篡改的情况很罕见;另一方面,由于硬件和网络原因而造成的消息不完整问题,只需要一套简单的校验算法即可。因此,在实际工程中,可以假设所有的消息都是完整的,也就是没有被篡改。
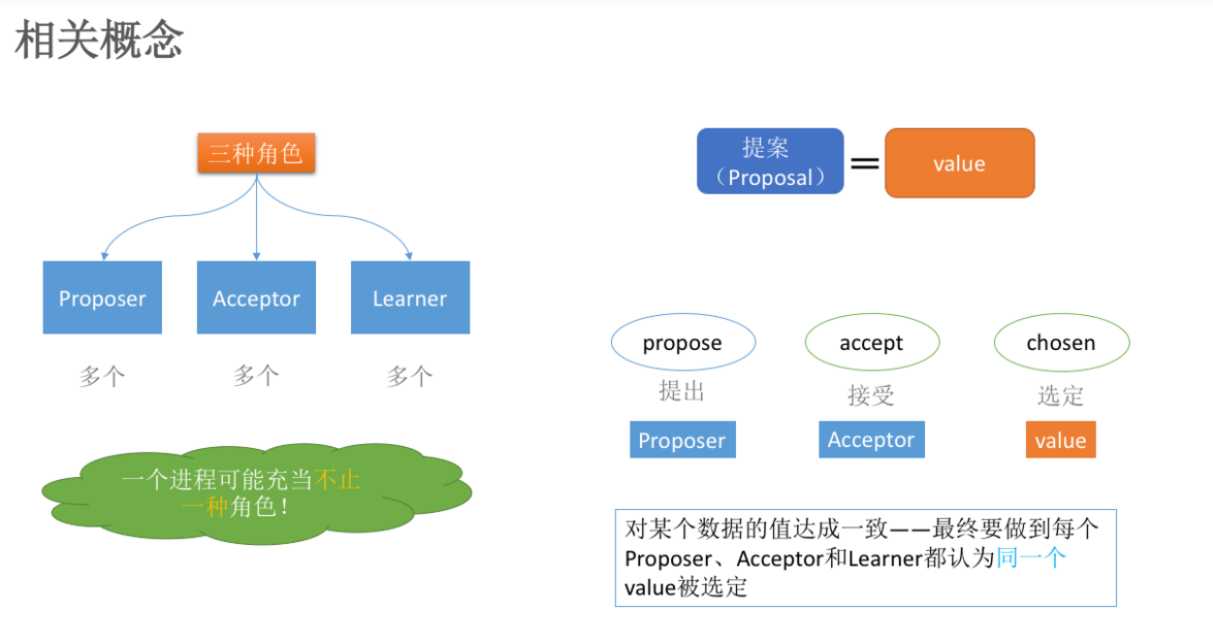
在Paxos算法中,有三种角色:
Proposer
Acceptor
Learners
在具体的实现中,一个进程可能同时充当多种角色。比如一个进程可能既是Proposer又是Acceptor又是Learner。Proposer负责提出提案,Acceptor负责对提案作出裁决(accept与否),learner负责学习提案结果。
还有一个很重要的概念叫提案(Proposal)。最终要达成一致的value就在提案里。只要Proposer发的提案被Acceptor接受(半数以上的Acceptor同意才行),Proposer就认为该提案里的value被选定了。Acceptor告诉Learner哪个value被选定,Learner就认为那个value被选定。只要Acceptor接受了某个提案,Acceptor就任务该提案里的value被选定了。
为了避免单点故障,会有一个Acceptor集合,Proposer想Acceptor集合发送提案,Acceptor集合中的每个成员都有可能同意该提案且每个Acceptor只能批准一个提案,只有当一半以上的成员同意了一个提案,就认为该提案被选定了。
假设有一组可以提出(propose)value(value在提案Proposal里)的进程集合。一个一致性算法需要保证提出的这么多value中,只有一个value被选定(chosen)。如果没有value被提出,就不应该有value被选定。如果一个value被选定,那么所有进程都应该能学习(learn)到这个被选定的value。对于一致性算法,安全性(safaty)要求如下:
只有被提出的value才能被选定。
只有一个value被选定,并且如果某个进程认为某个value被选定了,那么这个value必须是真的被选定的那个。 Paxos的目标:保证最终有一个value会被选定,当value被选定后,进程最终也能获取到被选定的value
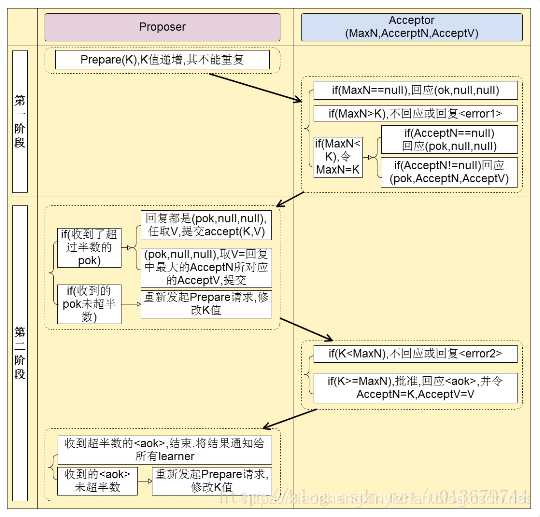
Paxos算法类似于两阶段提提交,其算法执行过程分为两个阶段。具体如下:
阶段一(prepare阶段):
(a) Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。Pareper(N)
(b) 如果一个Acceptor收到一个编号为N的Prepare请求,如果小于它已经响应过的请求,则拒绝,不回应或回复error。若N大于该Acceptor已经响应过的所有Prepare请求的编号(maxN),那么它就会将它已经接受过(已经经过第二阶段accept的提案)的编号最大的提案(如果有的话,如果还没有的accept提案的话返回{pok,null,null})作为响应反馈给Proposer,同时该Acceptor承诺不再接受任何编号小于N的提案。
阶段二(accept阶段):
(a) 如果一个Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对[N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value(某个acceptor响应的它已经通过的{acceptN,acceptV}),如果响应中不包含任何提案,那么V就由Proposer自己决定。
(b) 如果Acceptor收到一个针对编号为N的提案的Accept请求,只要该Acceptor没有对编号大于N的Prepare请求做出过响应,它就接受该提案。如果N小于Acceptor以及响应的prepare请求,则拒绝,不回应或回复error(当proposer没有收到过半的回应,那么他会重新进入第一阶段,递增提案号,重新提出prepare请求)。 在上面的运行过程中,每一个Proposer都有可能会产生多个提案。但只要每个Proposer都遵循如上述算法运行,就一定能保证算法执行的正确性。
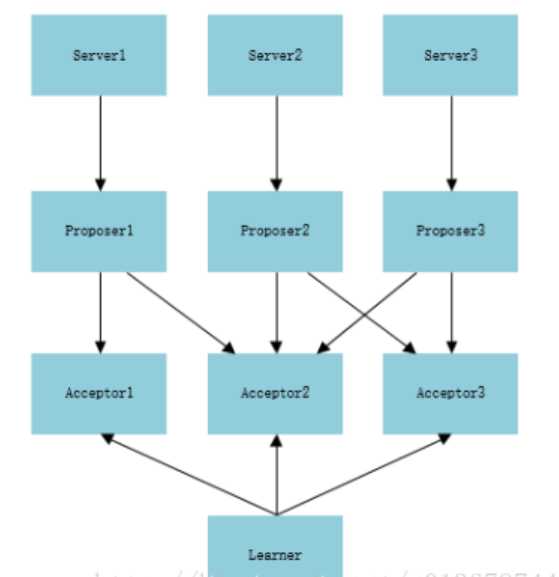
问题背景:假设我们有下图的系统,想要在server1,server2,server3选一个master。
prepare阶段
1. 每个server向proposer发送消息,表示自己要当leader,假设proposer收到消息的时间不一样,顺序是: proposer2 -> proposer1 -> proposer3,消息编号依次为1、2、3。紧接着,proposer将消息发给acceptor中超过半数的子成员(这里选择两个),如图所示,proposer2向acceptor2和acceptor3发送编号为1的消息,proposer1向acceptor1和accepto2发送编号为2的消息,proposer3向acceptor2和acceptor3发送编号为3的消息。
2. 假设这时proposer1发送的消息先到达acceptor1和acceptor2,它们都没有接收过请求,所以接收该请求并返回【pok,null,null】给proposer1,同时acceptor1和acceptor2承诺不再接受编号小于2的请求; 紧接着,proposer2的消息到达acceptor2和acceptor3,acceptor3没有接受过请求,所以返回proposer2 【pok,null,null】,acceptor3并承诺不再接受编号小于1的消息。而acceptor2已经接受proposer1的请求并承诺不再接收编号小于2的请求,所以acceptor2拒绝proposer2的请求;最后,proposer3的消息到达acceptor2和acceptor3,它们都接受过提议,但编号3的消息大于acceptor2已接受的2和acceptor3已接受的1,所以他们都接受该提议,并返回proposer3 【pok,null,null】;此时,proposer2没有收到过半的回复,所以重新取得编号4,并发送给acceptor2和acceptor3,此时编号4大于它们已接受的提案编号3,所以接受该提案,并返回proposer2 【pok,null,null】。
accept阶段
1、Proposer3收到半数以上(两个)的回复,并且返回的value为null,所以,proposer3提交了【3,server3】的提案。Proposer1也收到过半回复,返回的value为null,所以proposer1提交了【2,server1】的提案。Proposer2也收到过半回复,返回的value为null,所以proposer2提交了【4,server2】的提案。 (这里要注意,并不是所有的proposer都达到过半了才进行第二阶段,这里只是一种特殊情况)
2、Acceptor1和acceptor2接收到proposer1的提案【2,server1】,acceptor1通过该请求,acceptor2承诺不再接受编号小于4的提案,所以拒绝;Acceptor2和acceptor3接收到proposer2的提案【4,server2】,都通过该提案;Acceptor2和acceptor3接收到proposer3的提案【3,server3】,它们都承诺不再接受编号小于4的提案,所以都拒绝。 所以proposer1和proposer3会再次进入第一阶段,但这时候 Acceptor2和acceptor3已经通过了提案(AcceptN = 4,AcceptV=server2),并达成了多数,所以proposer会递增提案编号,并最终改变其值为server2。最后所有的proposer都肯定会达成一致,这就迅速的达成了一致。此时,过半的acceptor(acceptor2和acceptor3)都接受了提案【4,server2】,learner感知到提案的通过,learner开始学习提案,所以server2成为最终的leader。
有三种方案:
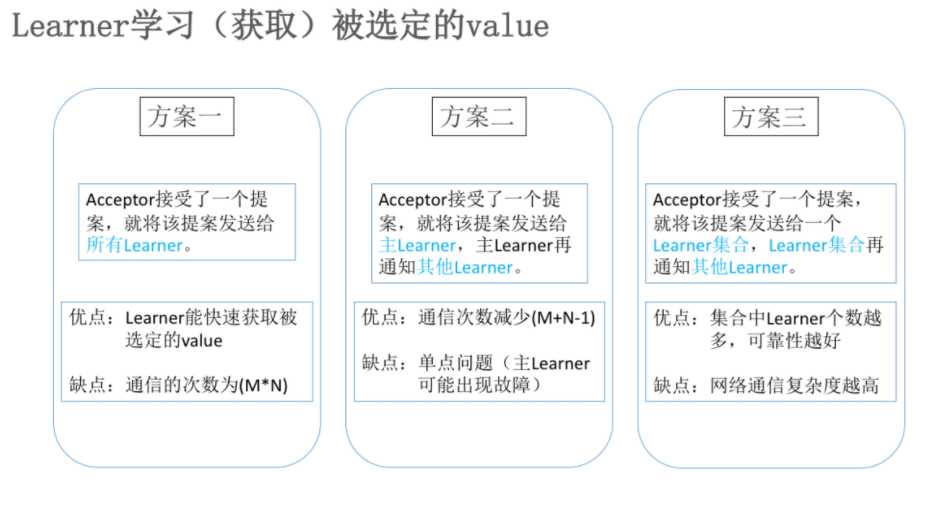
上边我们介绍了Paxos的算法逻辑,但在算法运行过程中,可能还会存在一种极端情况,当有两个proposer依次提出一系列编号递增的议案,那么会陷入死循环,无法完成第二阶段,也就是无法选定一个提案。如下图:

通过选取主Proposer,就可以保证Paxos算法的活性。选择一个主Proposer,并规定只有主Proposer才能提出议案。这样一来,只要主Proposer和过半的Acceptor能够正常进行网络通信,那么肯定会有一个提案被批准(第二阶段的accept),则可以解决死循环导致的活锁问题。 Paxos算法的过半依据 在Paxos算法中,采用了“过半”理念,也就是少数服从多数,这使Paxos算法具有很好的容错性。那么为什么采用过半就可以呢?
Paxos基于的过半数学原理: 我们称大多数(过半)进程组成的集合为法定集合,两个法定(过半)集合必然存在非空交集,即至少有一个公共进程,称为法定集合性质。 例如A,B,C,D,F进程组成的全集,法定集合Q1包括进程A,B,C,Q2包括进程B,C,D,那么Q1和Q2的交集必然不在空,C就是Q1,Q2的公共进程。如果要说Paxos最根本的原理是什么,那么就是这个简单性质。也就是说:两个过半的集合必然存在交集,也就是肯定是相等的,也就是肯定达成了一致。
Paxos是基于消息传递的具有高度容错性的分布式一致性算法。Paxos算法引入了过半的概念,解决了2PC,3PC的太过保守的缺点,且使算法具有了很好的容错性,另外Paxos算法支持分布式节点角色之间的轮换,这极大避免了分布式单点的出现,因此Paxos算法既解决了无限等待问题,也解决了脑裂问题,是目前来说最优秀的分布式一致性算法。其中,Zookeeper的ZAB算法和Raft一致性算法都是基于Paxos的。在后边的文章中,我会逐步介绍优秀的分布式协调服务框架,也是极优秀的工业一致性算法的实现Zookeeper使用和实现。
标签:篡改 osal 描述 编号 任务 相同 重复 技术 初始
原文地址:https://www.cnblogs.com/baichunyu/p/13232555.html