标签:需要 weight 说明 字段 扫描 运用 font 表数据 重复数据
1. MySQL索引引擎有两种:Innodb:聚集索引;Myisam:非聚集索引
2. MySQL 为什么不使用hash、二叉树、红黑树等作为索引的数据结构,而采用 B+ 树?
因为hash、二叉树、红黑树的高度不可控,B+ 树的高度可控,mysql 一般是3~5层。
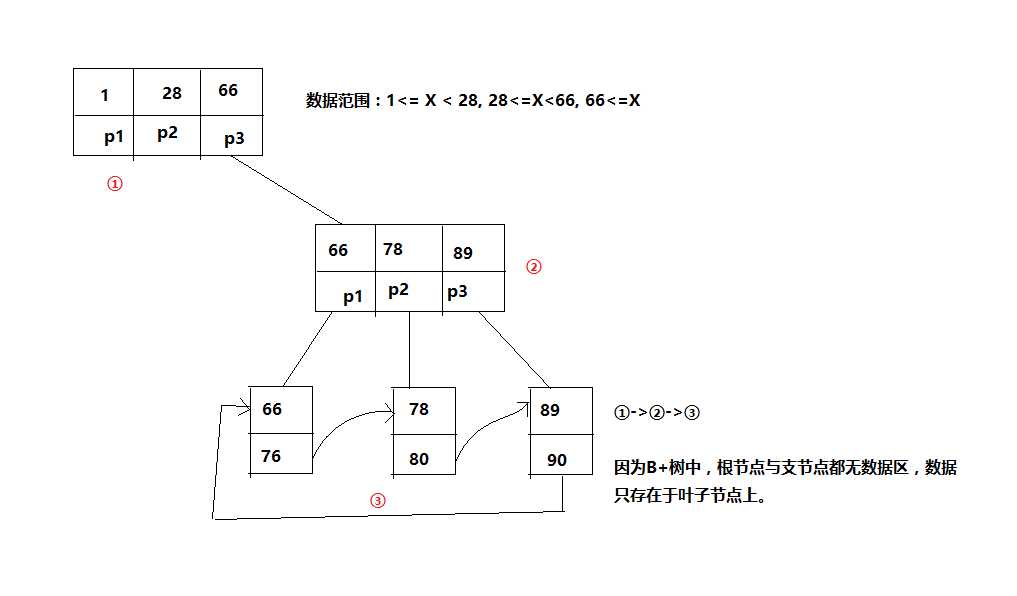
3. 多路平衡二叉树(B+树):
B+树只在最末端叶子节点存数据,叶子节点是以链表的形式互相指向的。
4. 通用sql语句:
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;
执行全流程:https://blog.csdn.net/sinat_32176267/article/details/83280206
5. B+树的IO能力强于B树,扫库扫表能力强于B树,范围查询,天然有序,查询性能稳定;
通过索引项的信息可直接返回所需的查询列,则该索引称之为查询sql的覆盖索引(推荐使用覆盖索引)。
所以将name作为索引列,如果要对name进行排序,最好是查询结果中也有name,因为数据节点区已经对name进行排序,可以减少order by的排序操作;此时name也叫做覆盖索引,不需要再进行回表操作。
6. 针对数据库表如何选则合适的列作为索引列?
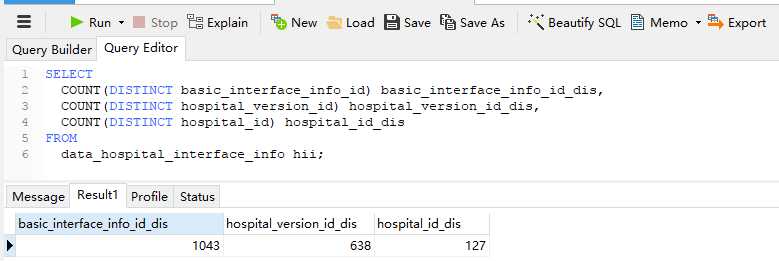
除了高频查询条件,还需要看所在列的数据的散列性,如下表:

通过COUNT(DISTINCT(COL))可以查询某列数据的散列度,比值越高,则列的散列性越好,选择散列性好的列作为索引更合适。
散列性越差,说明重复数据越多,如果作为索引,占据的叶子节点量庞大,此时索引扫描跟全表扫描区别不大。(从离散型的角度分析name like ‘123%‘,不一定可以用name索引,比如数据量100W,但是90W是以123开头)
仅从散列性角度来看,以下三列,basic_interface_info_id最适合作为索引列:
7. MySQL执行计划
针对上表进行简单的sql查询,查看执行计划,关注执行计划的 type、extra 字段:
type=ALL 表示全表扫描,sql处于最原生的状态,有很大优化空间;
-- 没走索引,type = ALL, Extra = Null EXPLAIN SELECT COUNT(DISTINCT basic_interface_info_id) basic_interface_info_id_dis FROM data_hospital_interface_info hii;
type=index 表示按照索引顺序进行全表扫描,根据索引然后回表取数据,取同一个表数据不可能比all快,但是按照索引全表扫描的数据是有序的,与all扫描的结果不同。(一定要比较优劣,可以将all之后的数据进行排序,再与index的结果进行对比);如果Extra = Null则需要进行回表,Extra = Using index则不需要回表,不需要回表的情况叫索引覆盖。
-- hospital_interface_info_id 是主键,即是唯一索引,type = index, Extra = Null EXPLAIN SELECT * FROM data_hospital_interface_info ORDER BY hospital_interface_info_id; -- hospital_interface_info_id 是主键,即是唯一索引,type = index, Extra = Using index EXPLAIN SELECT hospital_interface_info_id FROM data_hospital_interface_info; -- hospital_interface_info_id 是唯一索引,hospital_version_id 是普通索引, type = index_merge, Extra = Using sort_union(hospital_version_id_idx,PRIMARY); Using where EXPLAIN SELECT hospital_interface_info_id FROM data_hospital_interface_info WHERE hospital_interface_info_id = 467 or hospital_version_id = 500;
type=range 表示有范围的索引扫描,基于索引但是有范围限制,因此优于index,between、and、>、<、in、or都属于索引范围扫描。
-- hospital_interface_info_id 是主键,即是唯一索引,type = range, Extra = Using where EXPLAIN SELECT * FROM data_hospital_interface_info WHERE hospital_interface_info_id BETWEEN 467 AND 500;
type=ref 表示查询条件使用了索引而且不为主键和unique,即索引列的值不唯一,有重复,这样即使使用索引快速找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描,但不需要进行全表扫描,因为索引是有序的,即便有重复值也是在一个很小的访问内扫描。
-- hospital_version_id 是普通索引, type = ref, Extra = Null EXPLAIN SELECT * FROM data_hospital_interface_info WHERE hospital_version_id = 342;
type=ref_eq 没重现到这种情况
type=const 将主键放到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量,取决于优化器。
-- hospital_interface_info_id 是主键,即是唯一索引,type = const, Extra = Using index EXPLAIN SELECT hospital_interface_info_id FROM data_hospital_interface_info WHERE hospital_interface_info_id = 560;
8. 索引优化原则:
1. where后条件匹配的索引关键字列越多扫描的数据将越少;
2. 避免再次排序;
3. 尽可能运用到覆盖索引进行数据的扫描,减少回表IO操作;
标签:需要 weight 说明 字段 扫描 运用 font 表数据 重复数据
原文地址:https://www.cnblogs.com/miaoying/p/12983758.html