标签:zhang state 通过 对比 复杂 完成 针对性 key ima
目录
1.序言
此篇文章所讨论的是 React 16 以前的 Diff 算法。而 React 16 启用了全新的架构 Fiber,相应的 Diff 算法也有所改变,不在这篇文章的讨论范围内。研究 React 的 Diff 算法重在理解其思想,具体实现其次。
2.React 的核心思想
React 最为核心的就是 Virtual DOM 和 Diff 算法。React 在内存中维护一颗虚拟 DOM 树,当数据发生改变时(state & props),会自动的更新虚拟 DOM,获得一个新的虚拟 DOM 树,然后通过 Diff 算法,比较新旧虚拟 DOM 树,找出最小的有变化的部分,将这个变化的部分(Patch)加入队列,最终批量的更新这些 Patch 到实际的 DOM 中。
3.传统 diff 算法
将一颗 Tree 通过最小操作步数映射为另一颗 Tree,这种算法称之为 Tree Edit Distance(树编辑距离)。如图:
上图中,最小操作步数(编辑距离)为 3:
而 Tree Edit Distance 算法从 1979 年到 2011年,经过了30多年的发展演变,其时间复杂度最终被优化到 O(n^3),其发展历程大致如下(n 是树中节点的总数):
- 1979年,Tai 提出了次个非幂级复杂度算法,时间复杂度为 O(m3*n3)
- 1989年,Zhang and Shasha 将 Tai 的算法进行优化,时间复杂度为 O(m2*n2)
- 1998年,Klein 将 Zhang and Shasha 的算法再次优化,时间复杂度为 O(n^2*m*log(m))
- 2009年,Demiane 提出最坏情况下的计算公式,将时间复杂度控制在 O(n^2*m*(1+log(m/n)))
- 2011年,Pawlik and N.Augsten 提出适用于所有形状的树的算法,并将时间复杂度控制在 O(n^3)
这里不会展开讨论 Tree Edit Distance 算法的具体实现和原理,有兴趣可以直接看这篇论文 A Robust Algorithm for the Tree Edit Distance
4.React diff
传统 diff 算法其时间复杂度最优解是 O(n^3),那么如果有 1000 个节点,则一次 diff 就将进行 10 亿次比较,这显然无法达到高性能的要求。而 React 通过大胆的假设,并基于假设提出相关策略,成功的将 O(n^3) 复杂度的问题转化为 O(n) 复杂度的问题。
(1)两个假设
为了优化 diff 算法,React 提出了两个假设:
key prop 来暗示哪些子元素在不同的渲染下能保持稳定(2)三个策略
基于这上述两个假设,React 针对性的提出了三个策略以对 diff 算法进行优化:
(3)diff 具体优化
基于上述三个策略,React 分别对以下三个部分进行了 diff 算法优化
tree diff
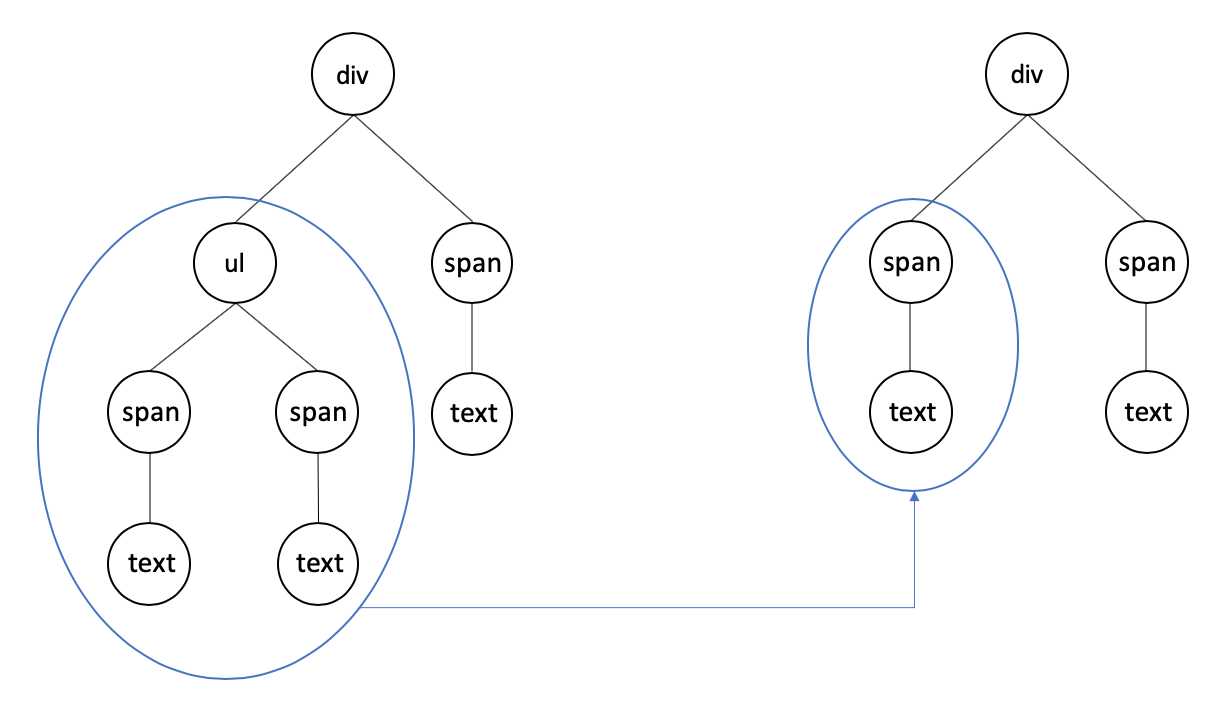
React 只对虚拟 DOM 树进行分层比较,不考虑节点的跨层级比较。如下图:
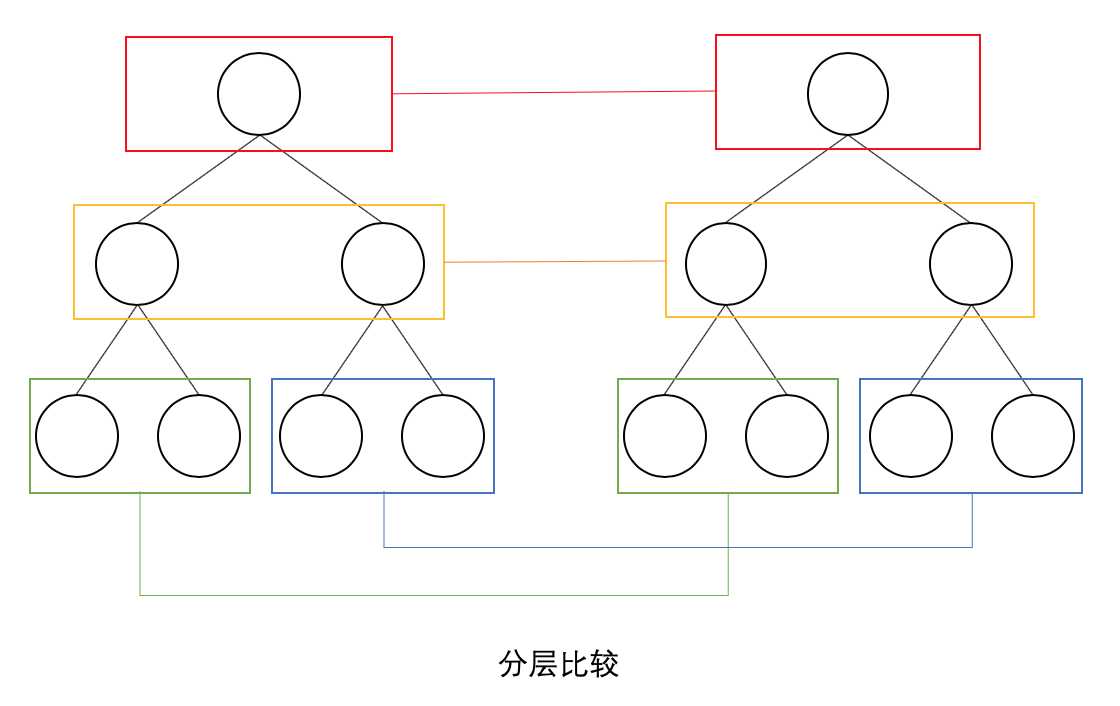
如上图,React 通过 updateDepth 对虚拟 Dom 树进行层级控制,只会对相同颜色框内的节点进行比较,根据对比结果,进行节点的新增和删除。如此只需要遍历一次虚拟 Dom 树,就可以完成整个的对比。
如果发生了跨层级的移动操作,如下图:
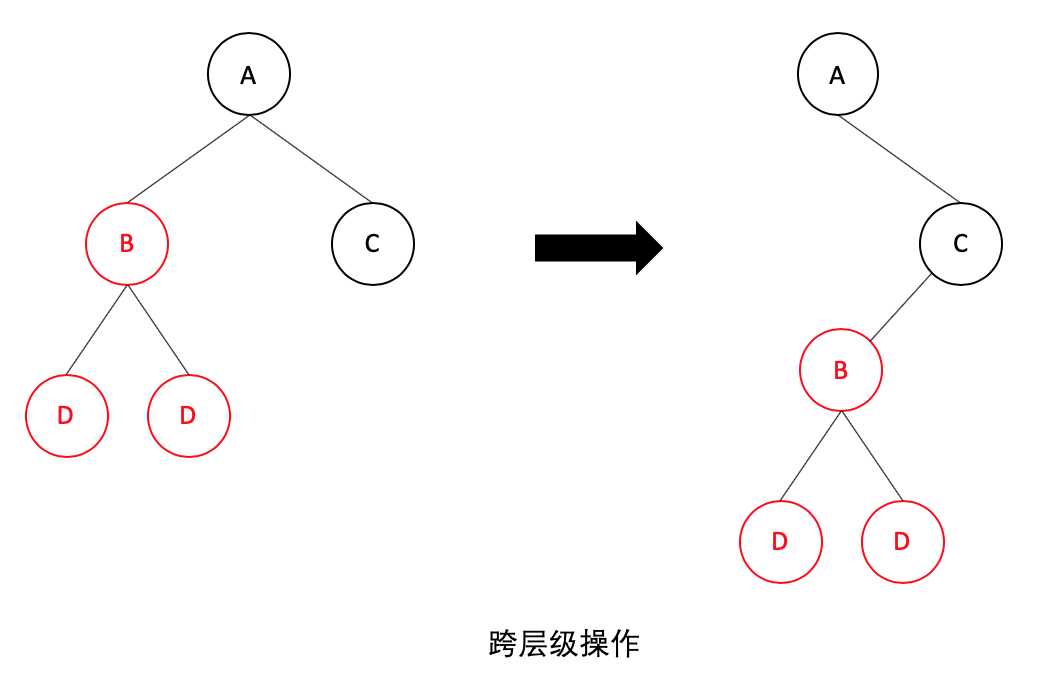
通过分层比较可知,React 并不会复用 B 节点及其子节点,而是会直接删除 A 节点下的 B 节点,然后再在 C 节点下创建新的 B 节点及其子节点。因此,如果发生跨级操作,React 是不能复用已有节点,可能会导致 React 进行大量重新创建操作,这会影响性能。所以 React 官方推荐尽量避免跨层级的操作。
component diff
React 是基于组件构建的,对于组件间的比较所采用的策略如下:
shouldComponentUpdate()方法判断是否需要进行比较,如果返回true,才比较对应的虚拟 DOM 节点,否则不需要比较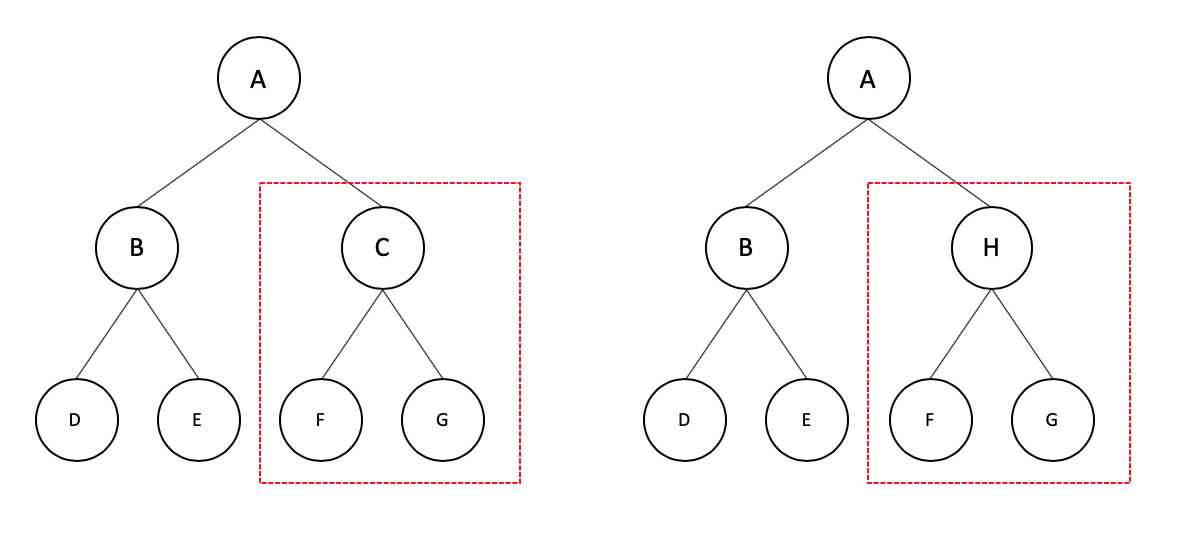
如上图,虽然组件 C 和组件 H 结构相似,但类型不同,React 不会进行比较,会直接删除组件 C,创建组件 H。
从上述 component diff 策略可以知道:
shouldComponentUpdate()方法来进行比较优化,减少组件不必要的比较。如果没有自定义,shouldComponentUpdate()方法默认返回true,默认每次组件发生数据(state & props)变化时,都会进行比较。element diff
element diff 涉及三种操作:移动、创建、删除。对于同一层级的子节点,对于是否使用 key 分别进行讨论。
对于不使用 key 的情况,如下图:
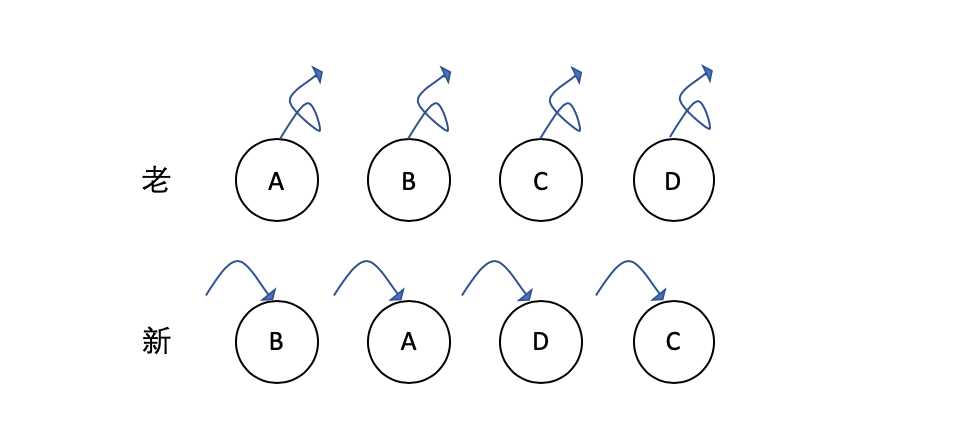
React 对新老同一层级的子节点对比,发现新集合中的 B 不等于老集合中的 A,于是删除 A,创建 B,依此类推,直到删除 D,创建 C。这会使得相同的节点不能复用,出现频繁的删除和创建操作,从而影响性能。
对于使用 key 的情况,如下图:
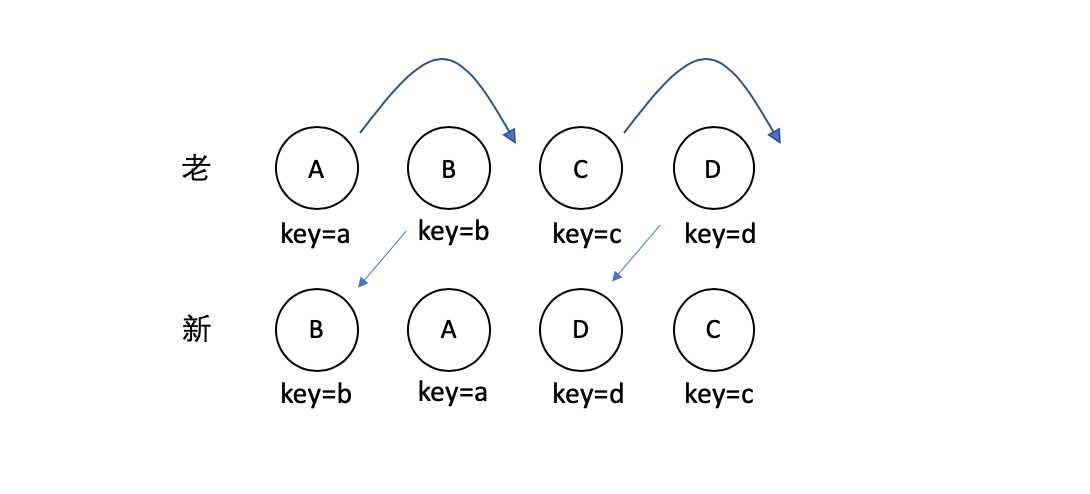
React 首先会对新集合进行遍历,通过唯一 key 来判断老集合中是否存在相同的节点,如果没有则创建,如果有的,则判断是否需要进行移动操作。并且 React 对于移动操作也采用了比较高效的算法,使用了一种顺序优化手段,这里不做详细讨论。
从上述可知,element diff 就是通过唯一 key 来进行 diff 优化,通过复用已有的节点,减少节点的删除和创建操作。
5.小结
React 通过大胆的假设,制定对应的 diff 策略,将 O(n3) 复杂度的问题转换成 O(n) 复杂度的问题
shouldComponentUpdate策略,对 component diff 进行算法优化6.参考
Deep In React之浅谈 React Fiber 架构(一)
react16的diff算法相比于react15有什么改动?
React 源码剖析系列 - 不可思议的 react diff
标签:zhang state 通过 对比 复杂 完成 针对性 key ima
原文地址:https://www.cnblogs.com/forcheng/p/13246874.html