标签:rom deadlock sele 地址 adl default mode 支持 现象
PXC简介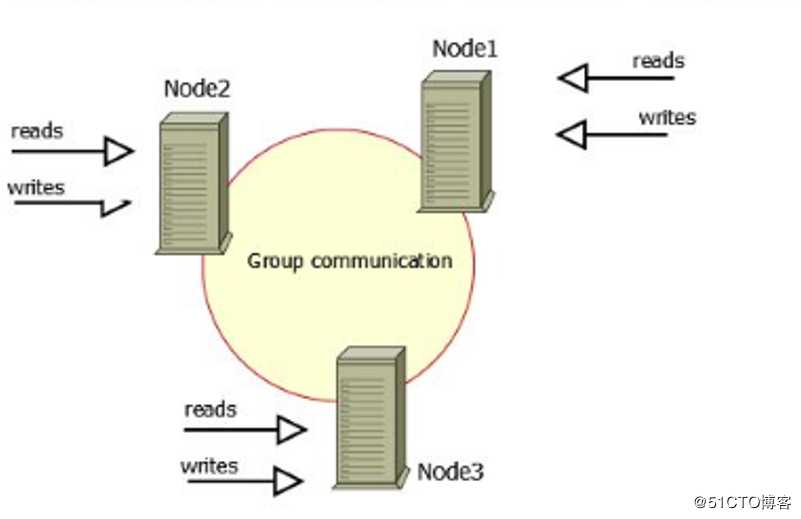
优点:
- 实现了MySQL集群的高可用性和数据的强一致性;
- 完成了真正的多节点读写的集群方案;
- 改善了主从复制延迟问题,基本上达到了实时同步;
- 新加入的节点可以自动部署,无需提交手动备份,维护方便;
- 由于是多节点写入,所以DB故障切换很容易。
.
缺点:
- 加入新节点时开销大。添加新节点时,必须从现有节点之一复制完整数据集。如果是100GB,则复制100GB。
- 任何更新的事务都需要全局验证通过,才会在其他节点上执行,集群性能受限于性能最差的节点,也就说常说的木桶定律。
- 因为需要保证数据的一致性,PXC采用的实时基于存储引擎层来实现同步复制,所以在多节点并发写入时,锁冲突问题比较严重。
- 存在写扩大的问题。所以节点上都会发生写操作,对于写负载过大的场景,不推荐使用PXC。
- 只支持InnoDB存储引擎。
PXC原理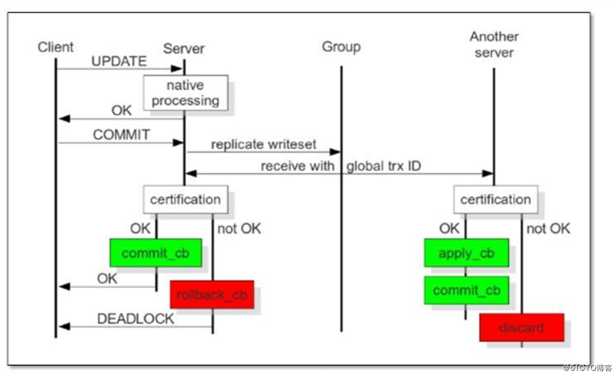
PXC的操作流程:
首先客户端向请求连接的写入节点提交事务之前,由该节点将需要产生的relication writeset广播出去,然后获取全局事务ID,一并传送到其他节点上去。其他节点通过certification合并数据之后,发现没有冲突数据,便执行apply_cb和commit_cb操作,否则就discard此次事务。而当前节点(客户端请求的写入节点)通过验证后,执行commit_cb操作,并返回OK给客户端。如果验证没有通过,则rollback_cb。
在生产线上的PXC集群中,至少要有三台节点。如果其中一个节点没有验证通过,出现了数据冲突,那么此时采取的方式就是将出现数据不一致的节点踢出集群,而且他会自动执行shutdown命令来关机。
PXC中的重要概念
首先要规范集群中节点的数量,整个集群节点数控制在最少3个、最多8个的范围内。最少3个是为了防止脑裂现象,因为只有在两个节点的情况下才会出现脑裂。脑裂的表现就是输出任何命令,返回结果都是unkown command。
当一个新节点要加入PXC集群的时候,需要从集群中各节点里选举出一个doner节点作为全量数据的贡献者。
PXC有两种节点的数据传输方式,一种叫SST全呈传输,另一种叫IST增是传输。SST传输有XtraBackup、mysqldump、rsync三种方式, 而增量传输只有XtraBackup。一般数据量不大的时候可以使用SST作为全量传输,但也只使用XtraBackup方式。
节点在集群中,会因新节点的加入或故障,同步失效等而发生状态的切换,下面列举出这些状态的含义:
open:节点启动成功,尝试连接到集群。
primary:节点已在集群中,在新节点加入集群时,选取donor进行数据同步时会产生式的状态。
joiner:节点处于等待接收同步数据文件的状态。
joined:节点已完成了数据同步,尝试保持和集群中其它节点进度- -致。
synced:节点正常提供服务的状态,表示已经同步完成并和集群进度保持一致。
doner:节点处于为新加入节点提供全星数据时的状态。
PXC中的重要配置参数
搭建PXC过程中,需要在my.cnf中设置以下参数:
- wsrep cluster _name:指定集群的逻辑名称,对于集群中的所有节点,集群名称必须相同。
- wsrep_ cluster _address: 指定集群中各节点的地址
- wsrep node name:指定当前节点在集群中的逻辑名称
- wsrep node address: 指定当前节点的IP地址
- wsrep_ provider: 指定Galera库的路径
- wsrep sst _method: 模式情况下,PXC使用XtraBackup进行SST传输。 强烈建议该参数指为xtrabackup-v2
- wsrep sst auth: 指定认证凭证SST作为<sst user>:<sst _pwd>。 必须在引导第一个节点后创建此用户并赋予
- 必要的权限。
- pxc_ _strict mode:严格模式,官方建议该参数值为ENFORCING。
在PXC中还有一个特别重要的模块就是Gcache。它的核心功能就是每个节点缓存当前最新的写集。如果有新节点加入集群,就可以把新数据等待增星传递给新节点,而不需要再使用SST方式了。这样可以让节点更快地加入
集群中。
GCache模块涉及了如下参数:
- gcache.size代表用来缓存写集增量信息的大小。它的默认大小是128MB,通过wsrep provider options变量参数设置。建议调整为2G 4G范围,足够的空间便于缓存更多的增量信息。
- gcache.mem_ size代表Gcache中内存缓存的大小,适度调大可以提高整个集群的性能。
- gcache. page_ size可以理解为如果内存不够用(Gcache不足),就直接将写集写入到磁盘文件中。
PXC集群状态监控
在集群搭建好之后,可以通过如下状态变量‘%wsrep%‘来查看集群中各节点的状态,下面例举出几个重要的参数,便于发现问题。
- wsrep local state uid: 集群中所有节点的该状态值应该是相同的,如果有不同值的节点,说明其没有加入集群。
- wsrep_ last _committed:最后提交的事务数目。
- wsrep cluster _size: 当前集群中的节点数量。
- wsrep_ cluster _status: 集群组成的状态。如果不是"Primary", 说明出现脑裂现象。
- wsrep local state:当前节点状态,值为4表示正常。该状态有四个值:
- joining:表示节点正在加入集群
- doner:节点处于为新加入节点提供全量数据时的状态。
- joined:当前节点已成功加入集群。
- synced:当前节点与集群中各节点是同步状态。
- wsrep_ ready: 为ON表示当前节点可以正常提供服务。为OFF, 则该节点可能发生脑裂或网络问题导致。
部署PXC
| 主机名 | IP | Column 3 |
|---|---|---|
| pxc-node1 | 192.168.171.150 | Text |
| pxc-node2 | 192.168.171.151 | Text |
| pxc-node3 | 192.168.171.152 | Text |
#OS版本
[root@pxc-node1 ~]# cat /etc/centos-release
CentOS Linux release 7.8.2003 (Core)#在三台数据库安装依赖包
[root@pxc-node1 ~]# yum install -y libev lsof perl-Compress-Raw-Bzip2 perl-Compress-Raw-Zlib perl-DBD-MySQL perl-DBI perl-Digest perl-Digest-MD5 perl-IO-Compress perl-Net-Daemon perl-PIRPC qpress socat openssl openssl-devel
#下载软件
[root@pxc-node1 ~]# wget https://www.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.18/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.18-1.el7.x86_64.rpm
[root@pxc-node1 ~]# wget https://www.percona.com/downloads/Percona-XtraDB-Cluster-57/Percona-XtraDB-Cluster-5.7.28-31.41/binary/tarball/Percona-XtraDB-Cluster-5.7.28-rel31-31.41.1.Linux.x86_64.ssl101.tar.gz
#安装xtrabackup
[root@pxc-node1 ~]# rpm -ivh percona-xtrabackup-24-2.4.18-1.el7.x86_64.rpm
#卸载掉原有mariadb
[root@pxc-node1 ~]# rpm -e mariadb-libs --nodeps
#创建MySQL的组和用户
[root@pxc-node1 ~]# groupadd -r mysql
[root@pxc-node1 ~]# useradd -M -s /bin/felse -r -g mysql mysql
#解包为mysql
[root@pxc-node1 ~]# tar zxf Percona-XtraDB-Cluster-5.7.28-rel31-31.41.1.Linux.x86_64.ssl101.tar.gz
mv Percona-XtraDB-Cluster-5.7.28-rel31-31.41.1.Linux.x86_64.ssl101/ /usr/local/mysql
#创建数据目录并赋予权限
[root@pxc-node1 ~]# mkdir /usr/local/mysql/data
[root@pxc-node1 ~]# chown -R mysql:mysql /usr/local/mysql/
#配置环境变量
[root@pxc-node1 ~]# vim /etc/profile
export PATH=/usr/local/mysql/bin:$PATH
[root@pxc-node2 ~]# . /etc/profile#编辑配置文件
[root@pxc-node1 ~]# vim /etc/my.cnf
[client]
port = 3306
socket = /tmp/mysql.sock
[mysql]
prompt = "\u@\h \R:\m:\s[\d]>"
no-auto-rehash
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = db.pid
character-set-server = utf8mb4
skip_name_resolve = 1
open_files_limit = 65535
back_log = 1024
max_connections = 512
max_connect_errors =1000000
table_open_cache = 1024
table_definition_cache = 1024
table_open_cache_instances = 64
thread_stack = 512K
external-locking =FALSE
max_allowed_packet = 32M
sort_buffer_size = 4M
join_buffer_size = 4M
thread_cache_size = 768
#query_cache_size = 0
#query_cache_type = 0
interactive_timeout = 600
wait_timeout = 600
tmp_table_size = 32M
max_heap_table_size = 32M
slow_query_log = 1
slow_query_log_file = /usr/local/mysql/data/slow.log
log-error = /usr/local/mysql/data/error.log
long_query_time = 0.1
server-id = 1813306
log-bin = /usr/local/mysql/data/mysql-bin
sync_binlog = 1
binlog_cache_size = 4M
max_binlog_cache_size = 1G
max_binlog_size = 1G
expire_logs_days = 7
master_info_repository = TABLE
relay_log_info_repository = TABLE
gtid_mode = on
enforce_gtid_consistency = 1
log_slave_updates
binlog_format = row
relay_log_recovery = 1
relay-log-purge = 1
key_buffer_size = 32M
read_buffer_size = 8M
read_rnd_buffer_size = 4M
bulk_insert_buffer_size = 64M
lock_wait_timeout = 3600
explicit_defaults_for_timestamp = 1
innodb_thread_concurrency = 0
innodb_sync_spin_loops = 100
innodb_spin_wait_delay = 30
transaction_isolation = REPEATABLE-READ
innodb_buffer_pool_size = 1024M
innodb_buffer_pool_instances = 8
innodb_buffer_pool_load_at_startup = 1
innodb_buffer_pool_dump_at_shutdown = 1
innodb_data_file_path = ibdata1:1G:autoextend
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 32M
innodb_log_file_size = 2G
innodb_log_files_in_group = 2
#innodb_nax_undo_log_size = 4G
innodb_io_capacity = 2000
innodb_io_capacity_max = 4000
innodb_flush_neighbors = 0
innodb_write_io_threads = 4
innodb_read_io_threads = 4
innodb_purge_threads = 4
innodb_page_cleaners = 4
innodb_open_files = 65535
innodb_max_dirty_pages_pct = 50
innodb_flush_method = O_DIRECT
innodb_lru_scan_depth = 4000
innodb_checksum_algorithm = crc32
#innodb_file_format = Barracuda
#innodb_file_format_max = Barracuda
innodb_lock_wait_timeout = 10
innodb_rollback_on_timeout = 1
innodb_print_all_deadlocks = 1
innodb_file_per_table = 1
innodb_online_alter_log_max_size = 4G
internal_tmp_disk_storage_engine = InnoDB
innodb_stats_on_metadata = 0
#PXC
wsrep_provider=/usr/local/mysql/lib/libgalera_smm.so
wsrep_provider_options="gcache.size=1G"
wsrep_cluster_name=pxc-test
wsrep_cluster_address=gcomm://192.168.171.150,192.168.171.151,192.168.171.152
wsrep_node_name=pxc-node1
wsrep_node_address=192.168.171.150
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth=sst:pwd@123
pxc_strict_mode=ENFORCING
default_storage_engine=InnoDB
innodb_autoinc_lock_mode = 2
[mysqldump]
quick
max_allowed_packet = 32M
#pxc-node2上修改
server-id = 1813307
wsrep_node_name=pxc-node2
wsrep_node_address=192.168.171.151
#pxc-node3上修改
server-id = 1813308
wsrep_node_name=pxc-node3
wsrep_node_address=192.168.171.152各节点完成MySQL初始化
[root@pxc-node1 ~]# mysqld --defaults-file=/etc/my.cnf --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --initialize引导第一个节点以初始化集群
#pxc-node1上启动MySQL
[root@pxc-node1 ~]# mysqld --defaults-file=/etc/my.cnf --wsrep_new_cluster &
[root@pxc-node1 ~]# ss -anput | grep mysql # 确认启动
tcp LISTEN 0 128 *:4567 *:* users:(("mysqld",pid=45268,fd=11))
tcp LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=45268,fd=35))
[root@pxc-node1 ~]# grep password /usr/local/mysql/data/error.log # 在错误日志中获取临时密码
2020-07-05T08:23:24.636538Z 1 [Note] A temporary password is generated for root@localhost: 1&U))a?(ulOj
#第一次登陆修改密码
root@localhost 16:32: [(none)]>alter user root@localhost identified by ‘123‘;
#创建PXC中的SST传输账号
root@localhost 16:32: [(none)]>grant all privileges on *.* to ‘sst‘@‘localhost‘ identified by ‘pwd@123‘;
root@localhost 16:36: [(none)]>flush privileges;将其他节点添加到集群
#在pxc-node2和pxc-node3上启动MySQL(可能需要点时间)
[root@pxc-node2 ~]# mysqld --defaults-file=/etc/my.cnf &
[root@pxc-node3~]# mysqld --defaults-file=/etc/my.cnf &
[root@pxc-node2 ~]# ss -anput | grep mysql # 刚启动时只会有4567这个端口,过一会加入集群后就会启动3306
tcp LISTEN 0 128 *:4567 *:* users:(("mysqld",pid=45248,fd=11))
#当node2和node3将node1的数据同步到本地后,可以直接使用node1的密码登陆数据库
#查看集群状态,可以看到集群中有3个节点
root@localhost 16:43: [(none)]>show global status like ‘wsrep_cluster_%‘;
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_weight | 3 |
| wsrep_cluster_conf_id | 3 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | b30f83dd-be99-11ea-b21c-b61232d3c9ee |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
5 rows in set (0.00 sec)
root@localhost 16:49: [(none)]>show global status like ‘%wsrep_ready%‘;
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_ready | ON |
+---------------+-------+
1 row in set (0.00 sec)验证复制
#在任意节点创建库表,往表中插入一些数据,在另外两个节点上查看是否同步
root@localhost 16:50: [(none)]>create database test1;
root@localhost 16:52: [(none)]>use test1;
root@localhost 16:52: [test1]>create table tb1(id int primary key auto_increment,name varchar(22));
root@localhost 16:54: [test1]>insert into tb1(name) values(‘zhangsan‘),(‘lisi‘),(‘liubin‘);
#在其他节点上查看数据是否同步
#node2上
root@localhost 16:55: [(none)]>select * from test1.tb1;
+----+----------+
| id | name |
+----+----------+
| 2 | zhangsan |
| 5 | lisi |
| 8 | liubin |
+----+----------+
3 rows in set (0.00 sec)
#node3上
root@localhost 16:56: [(none)]>select * from test1.tb1;
+----+----------+
| id | name |
+----+----------+
| 2 | zhangsan |
| 5 | lisi |
| 8 | liubin |
+----+----------+
3 rows in set (0.00 sec)标签:rom deadlock sele 地址 adl default mode 支持 现象
原文地址:https://blog.51cto.com/14227204/2508805