标签:pos eva 因此 提升 nec 需要 条件 结构 之一
首先说一下我对这个方案的看法,相比第一名与第二名的方案,这个方案的分割方法确实复杂的多,原论文是发表在MICCAI,后来砖投到IEEE image processing(SCI 1区),总体感觉给人一种花里胡哨的感觉,但是看分割结果,却着实让人满意。以下将解析此论文。
摘要
肿瘤分割的一个主要难点就是类别不平衡,肿瘤部分占整个脑的比例太小以至于难以精准的分割。传统解决类别不平衡的方法是采用级联的网络,一步一步的从粗到精的分割。先不考虑此网络的性能如何,就网络结构而言级联网络结构复杂,而且忽略了模型的相关性。针对此缺陷,本文提出了一种轻量级(模型参数是MC的三分之一)一步多任务分割模型(One-pass Multi-task Networks,OM-Net)。此模型有以下特点:首先,OM-Net将单独的分割任务集成到一个深度模型中,该模型由学习联合特征的共享参数以及学习区分性的特定任务参数组成 特征。 其次,为了更有效地优化OM-Net,我们利用任务之间的相关性来设计在线训练集传输策略(training data strategy)和基于课程学习的训练战略。 第三,我们进一步提出任务之间的共享预测结果,使我们能够设计一个跨任务引导注意力(CGA attention)模块。最后提出了一种有效的后处理方法:K-means
1
传统的级联模型(MC)往往是由多个单独的网络组成,大多数的分割步骤是:首先分割出感兴趣的区域(ROI),然后在感兴趣的区域进行精准分割,虽然此方法能够缓解肿瘤的类别不平衡因素,但是还是有很多缺陷:首先是MC需要训练多个网络,增加了复杂性;其次,训练集是相互独立的,忽略了多个模型之间的相关性。最后,缺少多个任务之间的相互作用,并且计算成本高。所以,提出了OM-Net(多任务集成,多任务相互作用,training data strategy,课程学习,单步预测,CGA)
将三个任务整合到一个模型当中,加强了训练阶段任务之间的相互作用,并且在预测阶段只需要一步的计算即可预测,不需要多步预测。并且采用training data strategy共享加强数据集之间的相互作用,采用课程学习的方式,根据任务的那一程度逐步将任务将如到网络中。采用CGA attention机制,加强了对重要信息的提取,抑制了不重要的信息。并且采用k-means的后处理的方式,对分割结果又一定的提升。
2
A.综述
介绍数据集与前人的工作。
B proposed attention
目前主流有三种attention机制,分别可以参考https://blog.csdn.net/qq_41639077/article/details/105161157?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase。相比SE attention而言,SE块基于每个通道中所有体素的平均响应,并使用单个权重重新校准每个通道,而不管这些体素属于哪个类别
3 方法
A.
采样获得数据集:(1)随机的在脑部区域进行采样,此时有5个类别:三个肿瘤类别,一个正常脑组织,一个背景。在预测时,把三个肿瘤的预测图进行相加获得粗分割图。(2)对coarse tumor mask 扩展5个体素以减少假阴性, 训练数据在扩张的真实的完整的肿瘤区域内随机取样(3)训练数据在扩张的真实的肿瘤核心区域内随机采样。
由于缺乏上下文信息,补丁中边界体素的分割结果可能不准确,采用重叠切片策略:https://blog.csdn.net/qq_34759239/article/details/79209148?tdsourcetag=s_pcqq_aiomsg,在本文中,仅仅预测中心区域的20*20*5的区域,抛弃对边界体素的预测。
B.
OM-Net:
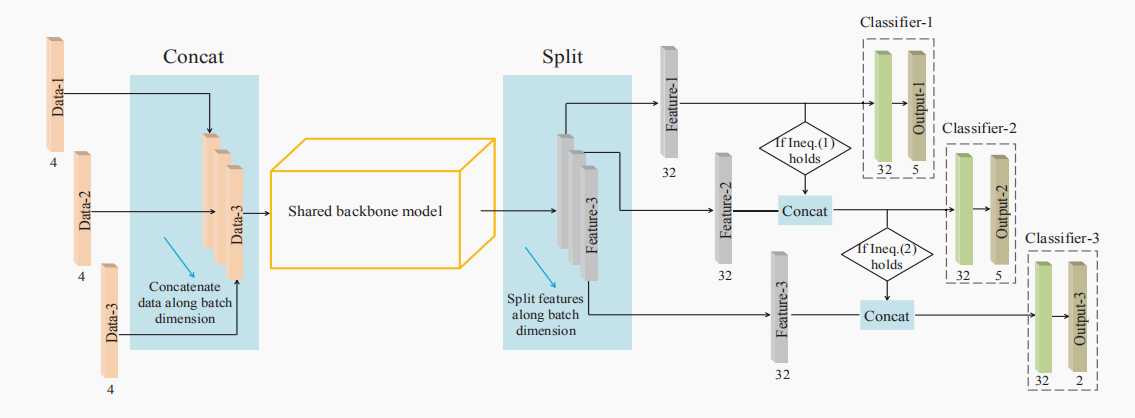
特点(多任务集成,多任务相互作用,training data strategy,课程学习,单步预测,CGA),满足一下条件,启动training data strategy(但是在inference阶段,数据融合,数据迁移都去掉)
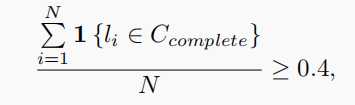
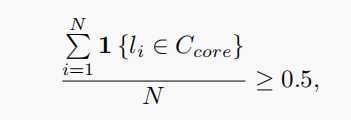
C.Cross-task Guided Attention
OM-net网络的由粗-精的分割可以看做是spatial attention,本文为了提高OM-Net的性能,提出了;另一种channel attention机制-----CGA。
在SE块中的全局平均池(GAP)操作忽略了输入补丁中每个类的体积的巨大变化。 我们通过计算特定类别区域而不是整个补丁中的统计数据来解决这个问题。 然而,在我们到达最终分类层之前,普通CNN的特定类别区域是未知的;因此,这是一个鸡和蛋的问题 。 幸运的是,OM-Net允许我们通过在任务之间共享预测结果来预先估计特定类别的区域(前面任务的分割结果会作用于后面的任务)
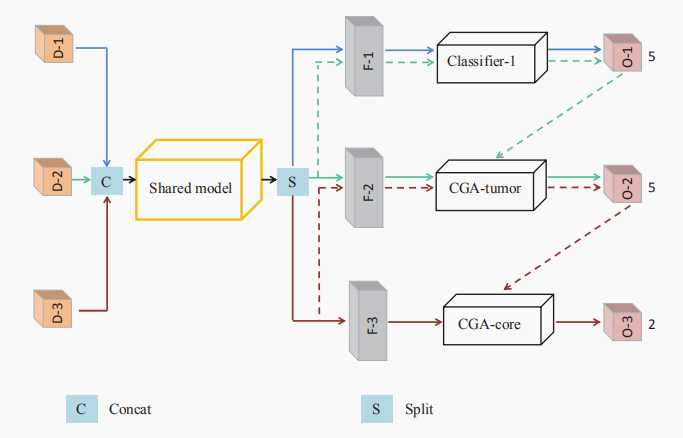
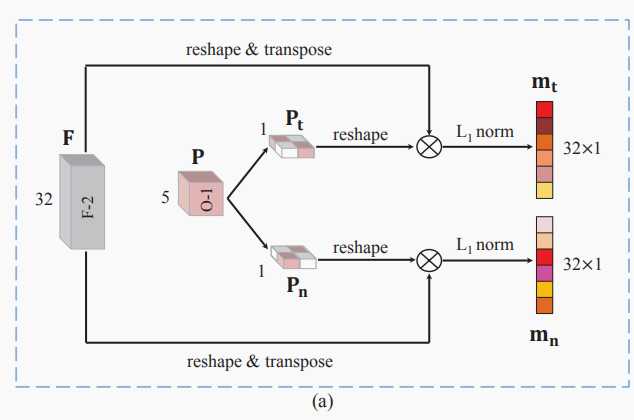
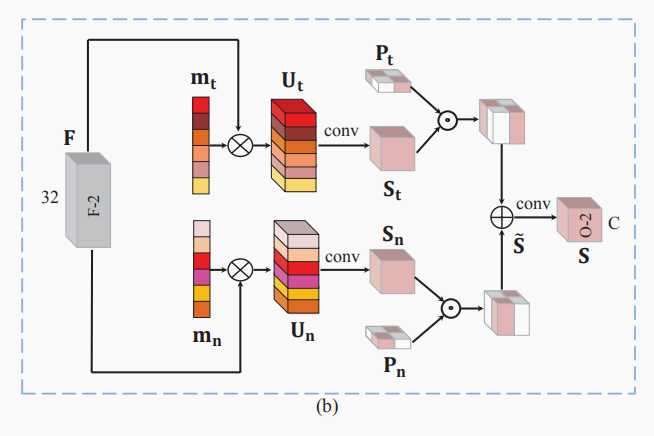
pt用了两次,第一次是为了利用特定类别的概率,第二次是为了减小St,Sn对tumor与non-tumor的敏感性。
D.后处理
1)移除满足下式的鼓励的集群,
标签:pos eva 因此 提升 nec 需要 条件 结构 之一
原文地址:https://www.cnblogs.com/hujinzhou/p/jiazhou2019_7_8.html