标签:style blog http io color ar 使用 sp for
1. 分区表简介
分区表在逻辑上是一个表,而物理上是多个表。从用户角度来看,分区表和普通表是一样的。使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性。
分区表是把数据按设定的标准划分成区域存储在不同的文件组中,使用分区可以快速而有效管理和访问数据子集。
1.1> 适合做分区表的情况
◊ 数据库中某个表的数据很多,在查询数据时会明显感觉到速度很慢,这个时候需要考虑分区表;
◊ 数据是分段的,如以年份为分隔的数据,对于当年的数据经常进行增删改查操作,而对于往年的数据几乎不做操作或只做查询操作,这种情况可以使用分区表。对数据的操作如果只涉及一部分数据而不是全部数据的情况可以考虑分区表,如果一张表的数据经常使用且不管年份之类的因素经常对其增删改查操作则最好不要分区。
1.2> 分区表的优点
◊ 分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看还是一个大表。
◊ 对于具有多个CPU的系统,分区可以对表的操作通过并行的方式进行,可以提升访问性能。
2. 创建分区表步骤
创建分区表的步骤分为5步:
(1)创建数据库文件组
(2)创建数据库文件
(3)创建分区函数
(4)创建分区方案
(5)创建分区表
2.1> 创建数据库文件组
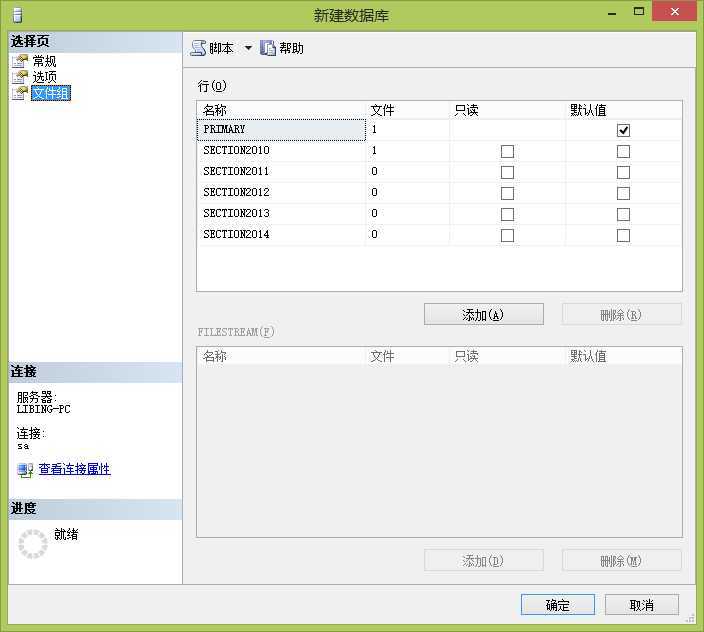
新建示例数据库Northwind,创建数据库文件组和文件,添加文件组。
2.2> 创建数据库文件
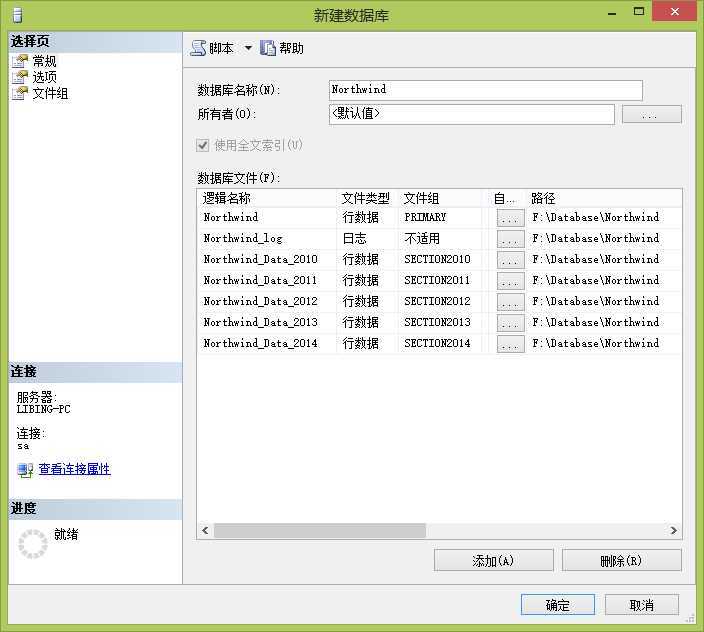
创建数据文件,并为数据文件分配文件组。
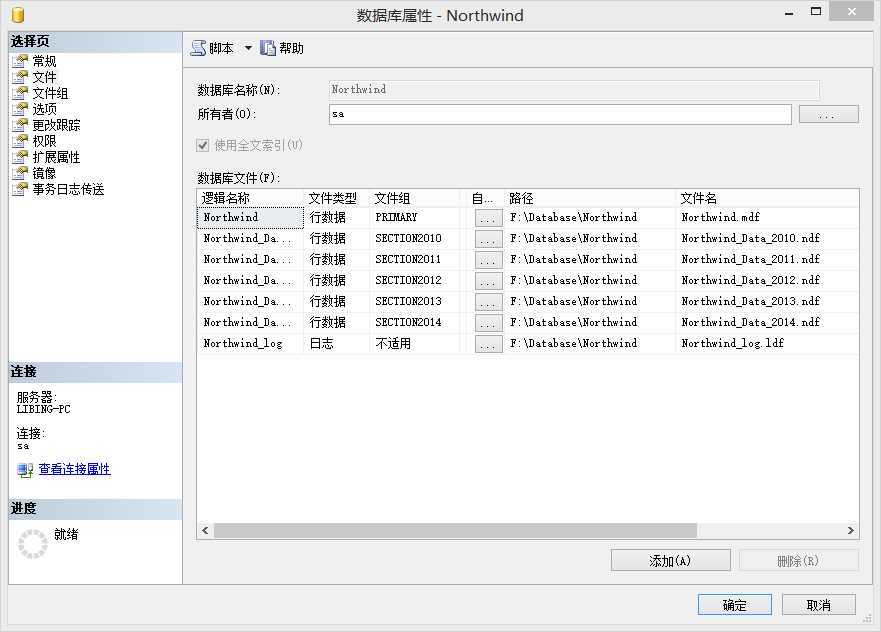
完成创建后的数据库文件信息
2.3> 创建分区函数
创建分区函数Transact-SQL语法:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
参数:
partition_function_name:分区函数的名称。 分区函数名称在数据库内必须唯一,并且符合标识符的规则。
input_parameter_type:用于分区的列的数据类型。 当用作分区列时,除 text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名数据类型或 CLR 用户定义数据类型外,所有数据类型均有效。
boundary_value:为使用 partition_function_name 的已分区表或索引的每个分区指定边界值。 如果 boundary_value 为空,则分区函数使 partition_function_name 将整个表或索引映射到单个分区。 只能使用 CREATE TABLE 或 CREATE INDEX 语句中指定的一个分区列。
LEFT | RIGHT 指定当间隔值由 数据库引擎 按升序从左到右排序时,boundary_value [ ,...n ] 属于每个边界值间隔的哪一侧(左侧还是右侧)。 如果未指定,则默认值为 LEFT。
示例:创建将用于Order表的分区函数
CREATE PARTITION FUNCTION Function_Order ( DATETIME ) AS RANGE RIGHT FOR VALUES(‘2011-01-01‘, ‘2012-01-01‘, ‘2013-01-01‘, ‘2014-01-01‘)
2.4> 创建分区方案
分区方案的作用是将分区函数生成的分区映射到文件组中去,分区方案是让SQL Server将已分区的数据放在哪个文件组中。
在当前数据库中创建一个将已分区表或已分区索引的分区映射到文件组的方案。 已分区表或已分区索引的分区的个数和域在分区函数中确定。 必须首先在 CREATE PARTITION FUNCTION 语句中创建分区函数,然后才能创建分区方案。
创建分区方案的Transact-SQL语法:
CREATE PARTITION SCHEME partition_scheme_name AS PARTITION partition_function_name [ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] ) [ ; ]
参数:
partition_scheme_name:分区方案的名称。 分区方案名称在数据库中必须是唯一的,并且符合标识符规则。
partition_function_name:使用分区方案的分区函数的名称。 分区函数所创建的分区将映射到在分区方案中指定的文件组。 partition_function_name 必须已经存在于数据库中。 单个分区不能同时包含 FILESTREAM 和非 FILESTREAM 文件组。
ALL:指定所有分区都映射到在 file_group_name 中提供的文件组,或映射到主文件组(如果指定了 [PRIMARY]。 如果指定了 ALL,则只能指定一个 file_group_name。
file_group_name | [ PRIMARY ] [ ,...n]:指定用来持有由 partition_function_name 指定的分区的文件组的名称。 file_group_name 必须已经存在于数据库中。
如果指定了 [PRIMARY],则分区将存储于主文件组中。 如果指定了 ALL,则只能指定一个 file_group_name。 分区分配到文件组的顺序是从分区 1 开始,按文件组在 [,...n] 中列出的顺序进行分配。 在 [,...n] 中,可以多次指定同一个 file_group_name。 如果 n 不足以拥有在 partition_function_name 中指定的分区数,则 CREATE PARTITION SCHEME 将失败,并返回错误。
如果 partition_function_name 生成的分区数少于文件组数,则第一个未分配的文件组将标记为 NEXT USED,并且出现显示命名 NEXT USED 文件组的信息。 如果指定了 ALL,则单独的 file_group_name 将为该 partition_function_name 保持它的 NEXT USED 属性。 如果在 ALTER PARTITION FUNCTION 语句中创建了一个分区,则 NEXT USED 文件组将再接收一个分区。 若要再创建一个未分配的文件组来拥有新的分区,请使用 ALTER PARTITION SCHEME。
在 file_group_name[ 1,...n] 中指定主文件组时,必须像在 [PRIMARY] 中那样分隔 PRIMARY,因为它是关键字。
示例:创建将用于Order表的分区方案
CREATE PARTITION SCHEME Scheme_Order AS PARTITION Function_Order TO ( SECTION2010, SECTION2011, SECTION2012, SECTION2013, SECTION2014 )
标签:style blog http io color ar 使用 sp for
原文地址:http://www.cnblogs.com/libingql/p/4087598.html