标签:hdfs 缓存 安装包 ann 启动命令 ati 方式 name mil
1、flume日志收集架构如下
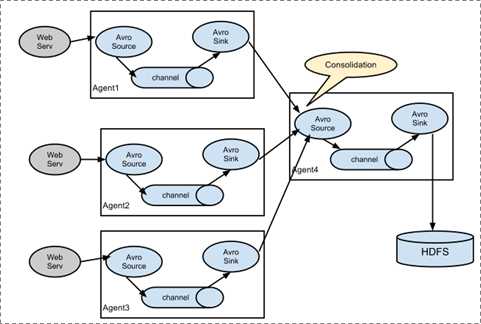
2、解压安装包,修改文件夹名称,配置环境变量
tar -zxvf apache-flume-1.6.0-bin.tar.gz
export FLUME_HOME=/soft/flume
export PATH=$PATH:$FLUME_HOME/bin
修改conf下的flume-env.sh,在里面配置JAVA_HOME
3、从netcat收集日志
1、先在flume的conf目录下新建一个文件 vi netcat-logger.conf # 定义这个agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source组件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 描述和配置sink组件:k1 a1.sinks.k1.type = logger # 描述和配置channel组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 内存里面存放1000个事件 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之间的连接关系 a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动命令如下,请注意路径是否正确,a1是配置文件里面的
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1an -Dflume.root.logger=INFO,console
测试效果,安装
sudo yum install nmap-ncat.x86_64 nc localhost 44444 hello word
4、从文件夹收集日志到hdfs
建立配置文件如下
agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1 # 配置source组件 agent1.sources.source1.type = spooldir agent1.sources.source1.spoolDir = /home/hadoop/logs/ agent1.sources.source1.fileHeader = false #配置拦截器 agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = host agent1.sources.source1.interceptors.i1.hostHeader = hostname # 配置sink组件 agent1.sinks.sink1.type = hdfs agent1.sinks.sink1.hdfs.path =hdfs://hadoop1/weblog/flume-collection/%y-%m-%d/ agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat =Text agent1.sinks.sink1.hdfs.rollSize = 102400 agent1.sinks.sink1.hdfs.rollCount = 1000000 agent1.sinks.sink1.hdfs.rollInterval = 60 #agent1.sinks.sink1.hdfs.round = true #agent1.sinks.sink1.hdfs.roundValue = 10 #agent1.sinks.sink1.hdfs.roundUnit = minute agent1.sinks.sink1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600 # Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1
启动脚本如下
../bin/flume-ng agent -c conf -f spooldir.conf -n agent1 -Dflume.root.logger=INFO,console
测试自己建立文件夹自己测试
5、从文件收集日志到hdfs,自己测试
agent1.sources = source1 agent1.sinks = sink1 agent1.channels = channel1 # Describe/configure tail -F source1 agent1.sources.source1.type = exec agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log agent1.sources.source1.channels = channel1 #configure host for source agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = host agent1.sources.source1.interceptors.i1.hostHeader = hostname # Describe sink1 agent1.sinks.sink1.type = hdfs #a1.sinks.k1.channel = c1 agent1.sinks.sink1.hdfs.path =hdfs://hadoop1/weblog22/flume/%y-%m-%d/ agent1.sinks.sink1.hdfs.filePrefix = access_log agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 agent1.sinks.sink1.hdfs.batchSize= 100 agent1.sinks.sink1.hdfs.fileType = DataStream agent1.sinks.sink1.hdfs.writeFormat =Text agent1.sinks.sink1.hdfs.rollSize = 102400 agent1.sinks.sink1.hdfs.rollCount = 1000000 agent1.sinks.sink1.hdfs.rollInterval = 60 #agent1.sinks.sink1.hdfs.round = true #agent1.sinks.sink1.hdfs.roundValue = 10 #agent1.sinks.sink1.hdfs.roundUnit = minute agent1.sinks.sink1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in memory agent1.channels.channel1.type = memory agent1.channels.channel1.keep-alive = 120 agent1.channels.channel1.capacity = 500000 agent1.channels.channel1.transactionCapacity = 600 # Bind the source and sink to the channel agent1.sources.source1.channels = channel1 agent1.sinks.sink1.channel = channel1
sudo yum install nmap-ncat.x86_64
标签:hdfs 缓存 安装包 ann 启动命令 ati 方式 name mil
原文地址:https://www.cnblogs.com/xiaofeiyang/p/13280725.html