标签:miss 提交 数据 tp服务器 epo 主机 下载 完整 第三方
我们想要进行数据通讯分几步?
TCP(Transmission Control Protocol,传输控制协议)提供的是面向连接,可靠的字节流服务。即客户和服务器交换数据前,必须现在双方之间建立一个TCP连接,之后才能传输数据。并且提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP(User Data Protocol,用户数据报协议)是一个简单的面向数据报的运输层协议。它不提供可靠性,只是把应用程序传给IP层的数据报发送出去,但是不能保证它们能到达目的地。由于UDP在传输数据报前不用再客户和服务器之间建立一个连接,且没有超时重发等机制,所以传输速度很快。
主机A通过向主机B 发送一个含有同步序列号标志位的数据段(SYN)给主机B ,向主机B 请求建立连接,通过这个数据段,主机A告诉主机B 两件事:我想要和你通信;你可以用哪个序列号作为起始数据段来回应我。
主机B 收到主机A的请求后,用一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A,也告诉主机A两件事:我已经收到你的请求了,你可以传输数据了;你要用哪个序列号作为起始数据段来回应我。
主机A收到这个数据段后,再发送一个确认应答,确认已收到主机B 的数据段:“我已收到回复,我现在要开始传输实际数据了”。
这样3次握手就完成了,主机A和主机B 就可以传输数据了。
当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求。
主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1。
由B 端再提出反方向的关闭请求,将FIN置1。
主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束。
进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别.
机器重启: 和进程终止的情况相同
机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行 reset. 即使没有写入操作, TCP自己也内置了一个保活定时器, 会定期询问对方方是否还在. 如果对方不在, 也会把连接释放
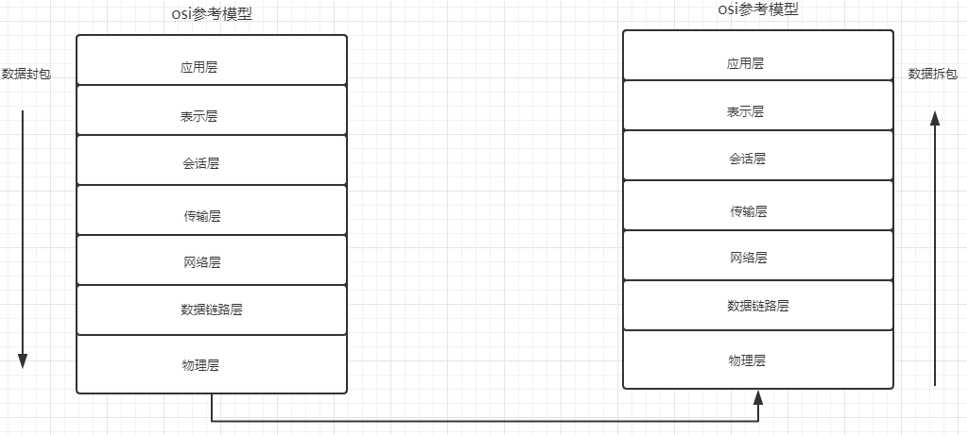
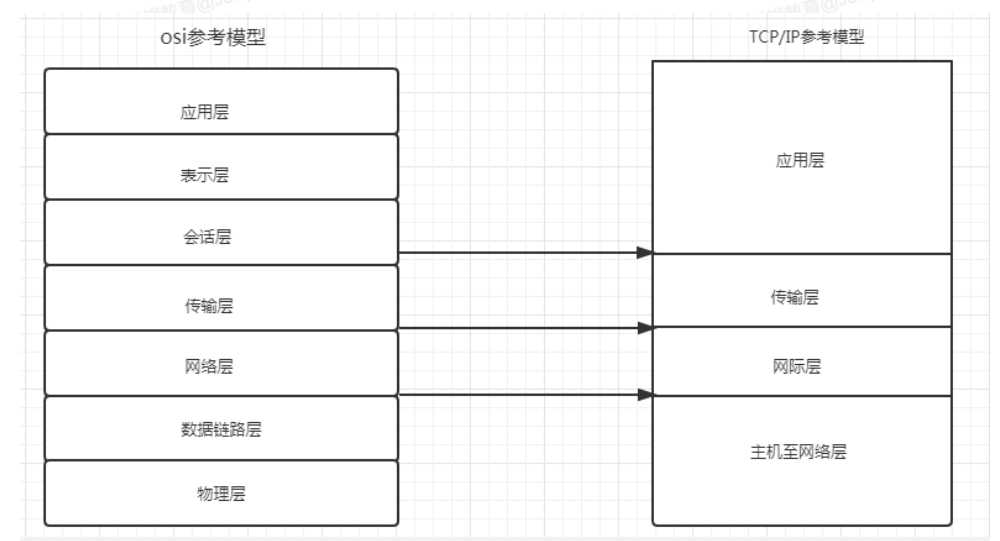
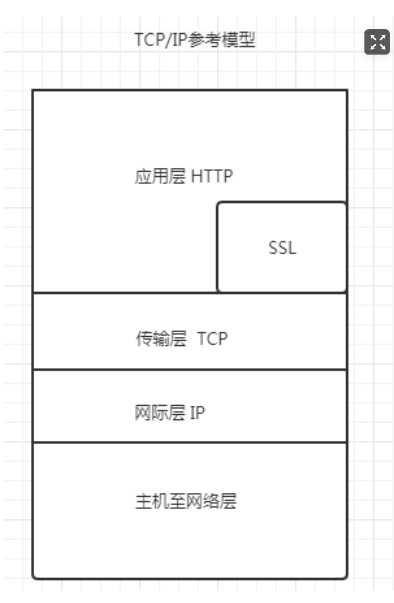
后期更新了新的参考模型 TCP/IP参考模型
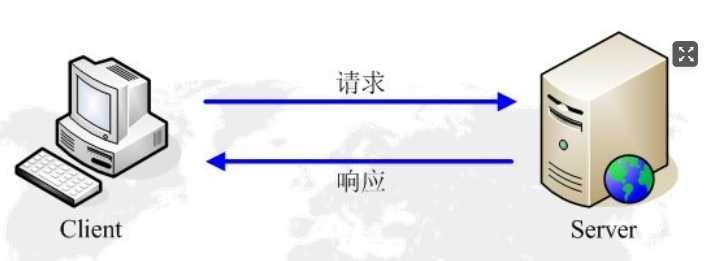
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
四个部分组成,下图给出了请求报文的一般格式。
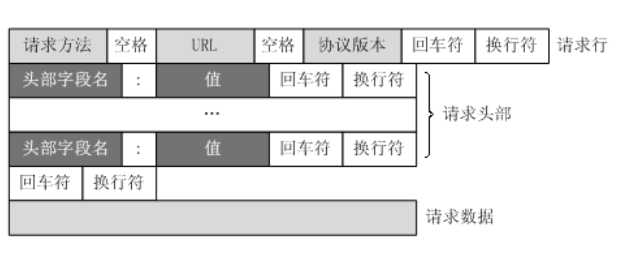
1 GET / HTTP/1.1 2 Host: www.baidu.com 3 Connection: keep-alive 4 Cache-Control: max-age=0 5 Upgrade-Insecure-Requests: 1 6 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36 7 Sec-Fetch-Mode: navigate 8 Sec-Fetch-User: ?1 9 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 10 Sec-Fetch-Site: same-origin 11 Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Python%20%20%E6%89%8B%E5%8A%A8%E5%9B%9E%E6%94%B6%E5%9E%83%E5%9C%BE&oq=Python%2520%25E6%2594%25B6%25E5%2588%25B0%25E5%259B%259E%25E6%2594%25B6%25E5%259E%2583%25E5%259C%25BE&rsv_pq=f5baabda0010c033&rsv_t=1323wLC5312ORKIcfWo4JroXu16WSW5HqZ183yRWRnjWHaeeseiUUPIDun4&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=2315&rsv_sug3=48&rsv_sug2=0&rsv_sug4=2736 12 Accept-Encoding: gzip, deflate, br 13 Accept-Language: zh-CN,zh;q=0.9 14 Cookie: BIDUPSID=4049831E3DB8DE890DFFCA6103FF02C1;
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP 0.9:只有基本的文本 GET 功能。
HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP 1.1:在 1.0 基础上进行更新,新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host、:path这些键值对。
| 序号 | 方法 | 描述 |
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
User-Agent:
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
(这里是Chrome)
移动端如Charles
标签:miss 提交 数据 tp服务器 epo 主机 下载 完整 第三方
原文地址:https://www.cnblogs.com/sdosun/p/13280885.html