标签:根据 主板 mic pen drag 编程 strong 本地变量 二级缓存
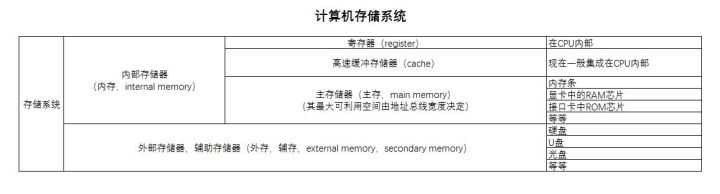
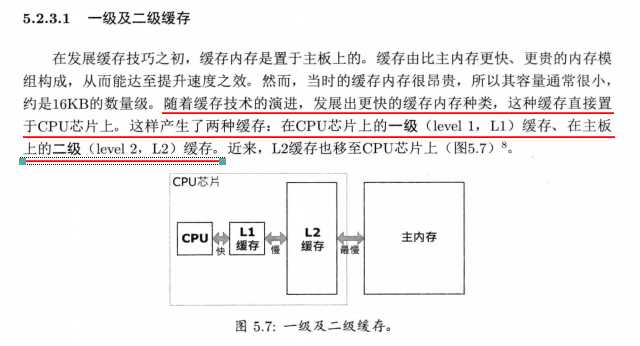
一级缓存和二级缓存:一级缓存在CPU,二级在主板或CPU,一些高端CPU还有三级缓存
主内存比L2缓存慢,L2缓存比L1缓存慢,因此,L2缓存命中失败通常比L1缓存命中失败的成本高。
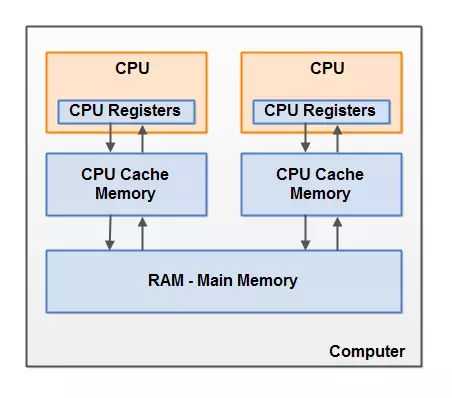
每个 CPU 在某一时刻运行一个线程是没有问题的。这意味着,如果你的 Java 程序是多线程的,在你的 Java 程序中每个 CPU 上一个线程可能同时(并发)执行。
每个 CPU 都包含一系列的寄存器,它们是 CPU 内内存的基础。CPU 在寄存器上执行操作的速度远大于在主存上执行的速度。这是因为 CPU 访问寄存器的速度远大于主存。所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写了。CPU访问缓存层的速度快于访问主存的速度,但通常比访问内部寄存器的速度还要慢一点。
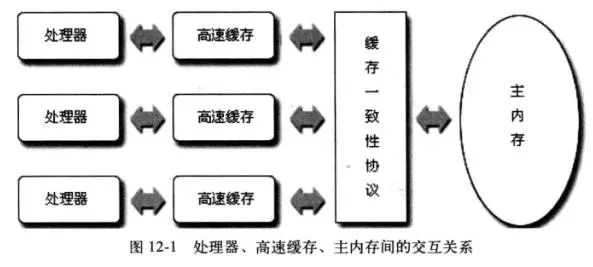
硬件存在缓存一致性问题:
当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致的情况,如果真的发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?
解决办法——为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、MESI(IllinoisProtocol)、MOSI、Synapse、Firefly及DragonProtocol,等等:
指令重排序问题:
为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致。
与处理器的乱序执行优化类似,Java虚拟机的即时编译器中也有类似的指令重排序(Instruction Reorder)优化
volatile关键字本身就包含了禁止指令重排序的语义,synchronized规则也保证了串行
JMM 的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量与 Java 编程中的变量有所区别,它包括了实例字段、静态字段和构成数组对象的元素,但不包括局部变量与方法参数,因为后者是线程私有的,不会被共享,自然就不会存在竞争问题。
JMM 是围绕着在并发过程中如何处理原子性、可见性和有序性这 3 个特征来建立的。
存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
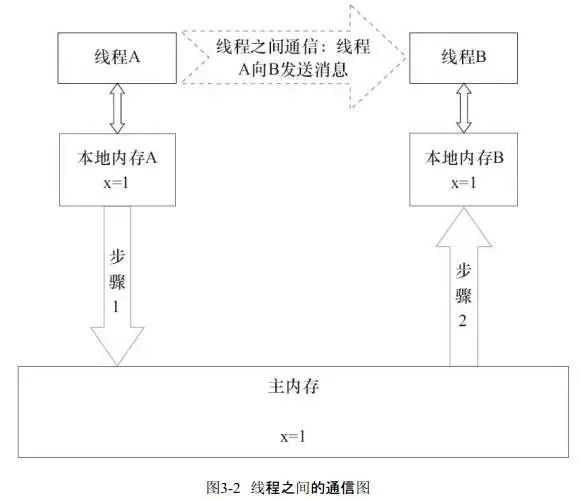
如下,如果线程A与线程B之间要通信的话,必须要经历下面2个步骤:
1)线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2)线程B到主内存中去读取线程A之前已更新过的共享变量。
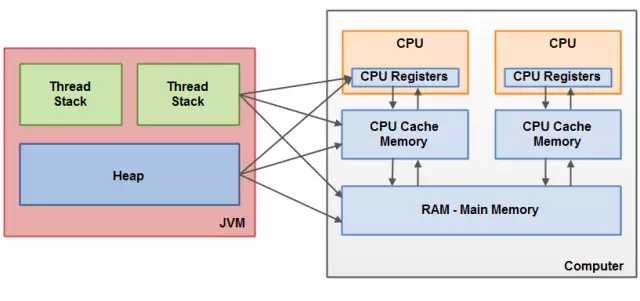
对于硬件,所有的线程栈和堆都分布在主内中。部分线程栈和堆可能有时候【正在执行时】会出现在 CPU 缓存中和 CPU 内部的寄存器中。
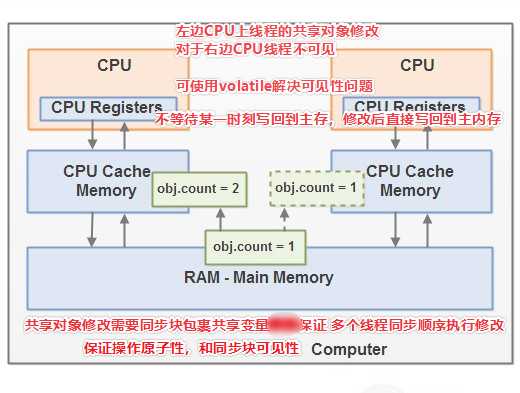
当对象和变量被存放在计算机中各种不同的内存区域中时,就可能会出现一些具体的问题。主要包括如下两个方面:
竞态条件指:当一个对象或者一个不同步的共享状态,被两个或者两个以上的线程修改时,对访问顺序敏感,则会产生竞态条件。
JMM 为程序中所有的操作定义了一个偏序关系,称之为 Happens-Before。也就是保证线程可见性的操作规则。
▲锁的内存语义:
参考链接:https://zhuanlan.zhihu.com/p/29881777
标签:根据 主板 mic pen drag 编程 strong 本地变量 二级缓存
原文地址:https://www.cnblogs.com/erlongxizhu-03/p/13291839.html