标签:with open random save mozilla sleep apt head mod webkit

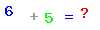
验证码如上所示
100*30
下面咱们开始神奇的旅程
下载批量验证码图片数据集用来训练
此验证码比较简单就下载了500
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: zhibo.wang # E-mail: gm.zhibo.wang@gmail.com # Date : 20/06/29 10:06:45 # Desc : import random import requests import uuid import time import os def is_exists(path_): if not os.path.exists(path_): os.makedirs(path_) is_exists("source/") for i in range(0, 500): print(i) url = ‘https://www.okcis.cn/php/checkUser/code.php‘ resp = requests.get(url, headers={ "user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/75.0.3770.90 Chrome/75.0.3770.90 Safari/537.36"}) with open(‘source/‘ + str(uuid.uuid4()) + ‘.png‘, ‘wb‘) as f: f.write(resp.content) time.sleep(0.1)
二值化并切割验证码
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: zhibo.wang # E-mail: gm.zhibo.wang@gmail.com # Date : 20/06/29 10:06:45 # Desc :
import os import uuid import numpy as np from PIL import Image import time def is_exists(path_): if not os.path.exists(path_): os.makedirs(path_) is_exists("letters/") def splitAndSave(path): path = ‘./source/‘ + path pix = np.array(Image.open(path).convert(‘L‘)) pix = (pix > 200) * 255 split_parts = [ [3, 23], [23, 43], [43, 63] ] for part in split_parts: letter = pix[0:, part[0]: part[1]] im = Image.fromarray(np.uint8(letter)) save_path = ‘./letters/‘ + str(uuid.uuid4()) + ‘.png‘ print(‘\t‘, save_path) im.save(save_path) if __name__ == ‘__main__‘: im_paths = filter(lambda fn: os.path.splitext(fn)[1].lower() == ‘.png‘, os.listdir(‘./source‘)) for im_path in im_paths: print(im_path) splitAndSave(im_path)
给切割好的数据打标签
每次选中一个类型的数据放入复制粘贴到train 文件夹下 然后 修改 n 字段进行每个类别的自动修改
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: zhibo.wang # E-mail: gm.zhibo.wang@gmail.com # Date : 20/06/29 11:36:11 # Desc : import os def list_all_files(rootdir): _files = [] try: list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isdir(path): _files.extend(list_all_files(path)) if os.path.isfile(path): _files.append(path) except Exception: pass return _files def rename_filename(filename, newfilename): os.rename(filename, newfilename) def run(): n = "10" path_ = ‘train‘ all_files = [i for i in list_all_files(path_) if len(i.split("/")[-1]) == 40] for i in range(0, len(all_files)): file_name = all_files[i] new_file_name = "{0}/{1}:{2}.png".format(path_, n, i) # win文件名不能有:请自行修改 print(new_file_name) rename_filename(file_name, new_file_name) if __name__ == "__main__": run()
数据打标签完成开始训练模型
训练数据 knn
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: zhibo.wang # E-mail: gm.zhibo.wang@gmail.com # Date : 20/06/29 10:06:45 # Desc :
import os from PIL import Image import numpy as np import joblib from sklearn.neighbors import KNeighborsClassifier from utils import list_all_files def list_all_files(rootdir): _files = [] try: list = os.listdir(rootdir) for i in range(0, len(list)): path = os.path.join(rootdir, list[i]) if os.path.isdir(path): _files.extend(list_all_files(path)) if os.path.isfile(path): _files.append(path) except Exception: pass return _files def load_dataset(): X = [] y = [] path_ = "train" all_flies = list_all_files(path_) keys = [str(i) for i in range(1, 11)] + ["+", "-"] for k in keys: for file_ in all_flies: if file_.split("/")[-1].split(":")[0] == str(k): path = file_ pix = np.asarray(Image.open(path).convert("L")) X.append(pix.reshape(20*30)) y.append(k) return np.asarray(X), np.asarray(y) if __name__ == "__main__": X, y = load_dataset() knn = KNeighborsClassifier() knn.fit(X, y) joblib.dump(knn, ‘knn.pkl‘)
训练完成下来测试下效果
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: zhibo.wang # E-mail: gm.zhibo.wang@gmail.com # Date : 20/06/29 10:06:45 # Desc :
import os import numpy as np from PIL import Image import joblib def split_letters(path): pix = np.array(Image.open(path).convert(‘L‘)) pix = (pix > 200) * 255 split_parts = [ [3, 23], [23, 43], [43, 63] ] letters = [] for part in split_parts: letter = pix[0:, part[0]: part[1]] letters.append(letter.reshape(20*30)) return letters def get_captcha_result(model_path, filename): sipo_knn = joblib.load(model_path) letters = split_letters(filename) return "".join([str(i) for i in sipo_knn.predict(letters)]) if __name__ == "__main__": for test in os.listdir(‘./test‘): datas = test, get_captcha_result(‘knn.pkl‘, ‘./test/‘ + test) print(datas)
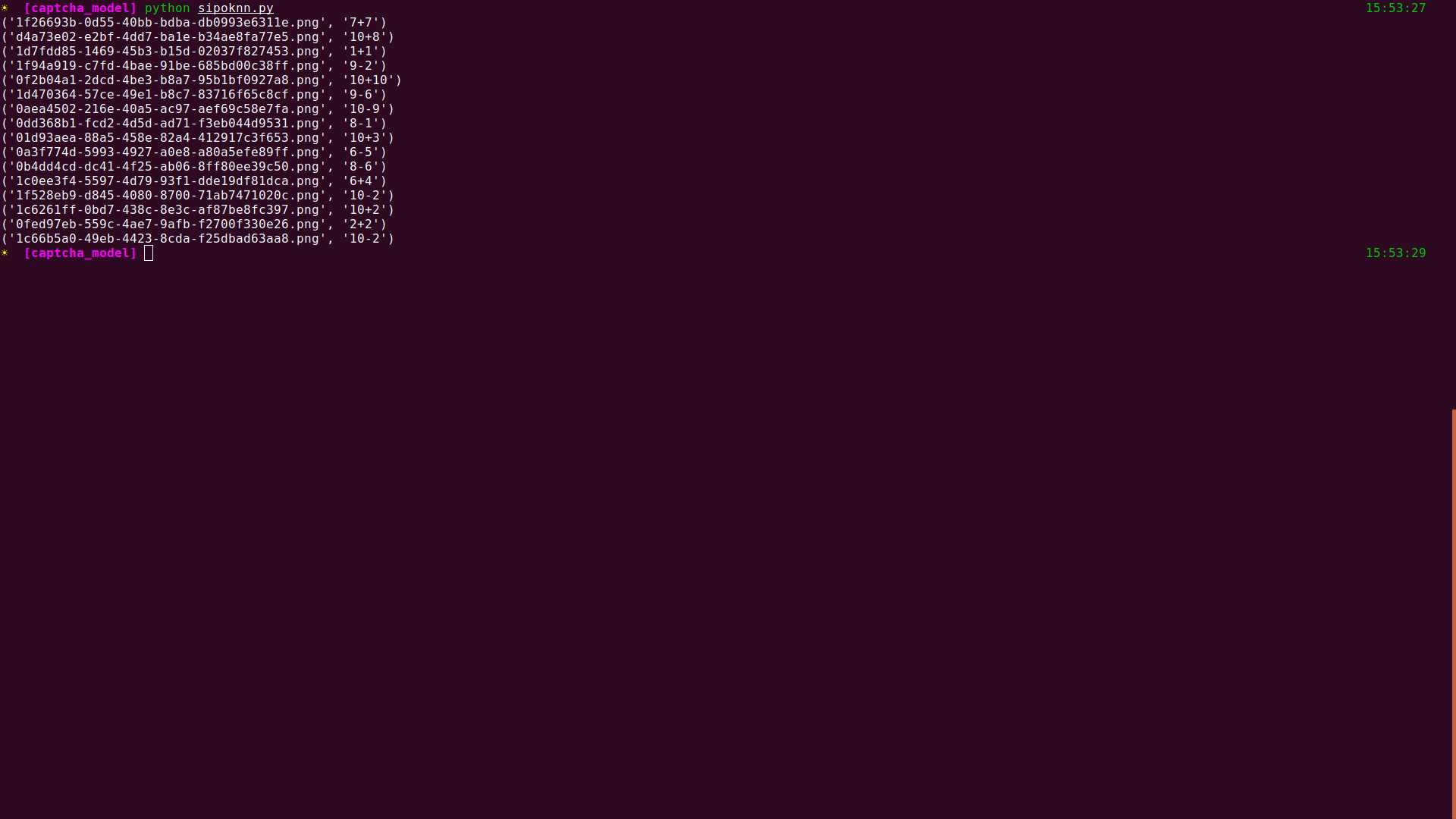
结果挺满意的百分百识别正确
下来就是进行简单的计算了 此处略。。。。。。。。。
标签:with open random save mozilla sleep apt head mod webkit
原文地址:https://www.cnblogs.com/dockers/p/13299311.html