标签:pcs requests 字符 点击 解析 order 直接 利用 content
这两天我一时兴起想学习 PS ,于是去我的软件宝库中翻出陈年已久的 PhotoshopCS6 安装,结果发现很真流畅诶!
然后去搜索学习视频,网上的视频大多浮躁,收费,突然想到了我入门编程时学习的网站, 我要自学网 ,寻找当时非常喜欢的易语言编程视频,很可惜,没有了。而且发现网站似乎不那么好用了QAQ。
找啊找,找啊找,找到了一个同类型,界面很古老的学习网站, 51视频学院(禁不住好奇,似乎很多那个时候的网站都喜欢51开头,比如吾爱论坛,51巅峰阁...) ,发现上面的ps视频还可以,但是我家的网速是不是老卡,所以想一下子都下载完,然后就慢慢本地看啦!不再受网络的影响。 想到这种事情,就立马想到了Python。

Python搞起!
寻找视频地址
右键网页点击检查,先刷新一下网页,然后点击网络选项卡。
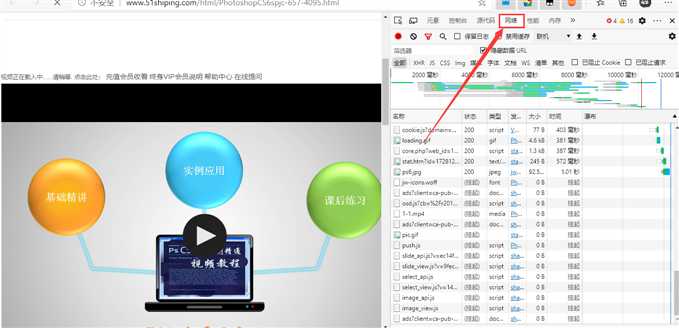 这个网站属于比较老啦,哈哈,我这样的爬虫小白白都能爬,直接点击媒体,我们就能发现视频的请求地址啦,也就是下载地址。
这个网站属于比较老啦,哈哈,我这样的爬虫小白白都能爬,直接点击媒体,我们就能发现视频的请求地址啦,也就是下载地址。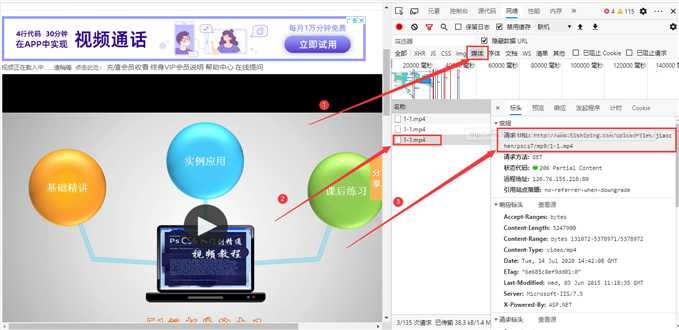 啊哈,果不其然,复制链接后打开就可以下载视频了!
啊哈,果不其然,复制链接后打开就可以下载视频了!
获取视频地址
这就是我们寻找到的视频地址啦,但是怎么知道其他视频的地址呢?注意看红色方框的内容
这个时候,让我们回到这个课程的目录页看看
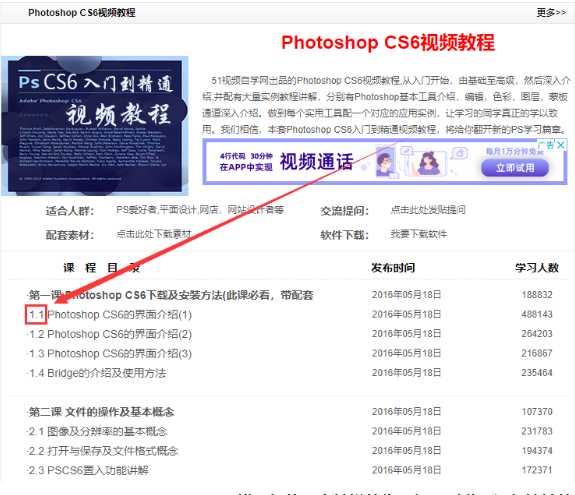 欸欸欸?是不是看到了点东西?没错,相信眼光敏锐的你已经看到啦,视频地址的后面的1-1就是课程的章节序号啦!
欸欸欸?是不是看到了点东西?没错,相信眼光敏锐的你已经看到啦,视频地址的后面的1-1就是课程的章节序号啦!
那我们去试几个,发现也是可行的!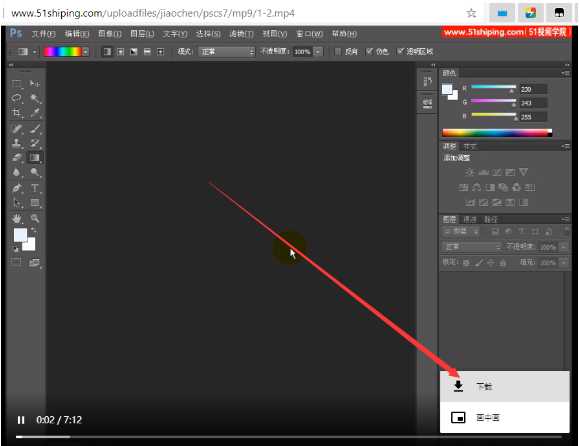 所以我们从目录网页上获取那个章节序号就好啦,顺便把后面的文字也获取了,当成文件名。不然都不知道视频的内容是什么。
所以我们从目录网页上获取那个章节序号就好啦,顺便把后面的文字也获取了,当成文件名。不然都不知道视频的内容是什么。
总而言之,流程大致为从目录获取章节序号->下载视频->保存到本地。
获取章节序号及内容
这里用到了XPath,不会的 点我看看, 很简单的。
代码:
import requests
from lxml import etree
list_url = "http://www.51shiping.com/list-657-1.html"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align=‘left‘]/a/text()")
for title in titles:
print(title)
结果:
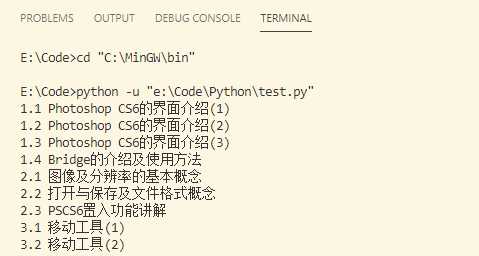
完美!第一步大功告成
但是,在编写下面是发现一个隐藏的坑点,那就是 空格是‘\ax0‘,你输出titles就知道我说的什么意思了 ,下图是titles数组实际存的内容:

所以下面分割字符串时候要以\ax0分割。
试下载一页的视频
import requests
from lxml import etree
list_url = "http://www.51shiping.com/list-657-1.html"
v_url = "http://www.51shiping.com/uploadfiles/jiaochen/pscs7/mp9/" # 视频地址,用于拼接
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align=‘left‘]/a/text()")
# 下载
for title in titles:
#unicodedata.normalize(‘NFKC‘, titles[i]) # 去掉\xa0这样的空白字符
file_dir = ‘E:/PSVideo/{}.mp4‘.format(title) # 保存的路径和文件名
order = title.split(‘\xa0‘)[0] # 每节的编号
video_url = v_url+order.split(‘.‘)[0]+‘-‘+order.split(‘.‘)[1]+‘.mp4‘ # 拼接视频下载地址
print(title+‘正在下载中...请耐心等待‘);
# 下载视频
with open(file_dir,‘wb‘) as f:
f.write(requests.get(video_url,headers=headers).content)
f.flush()
print(video_url)
print(file_dir+‘ 已经下载成功!‘);
结果:
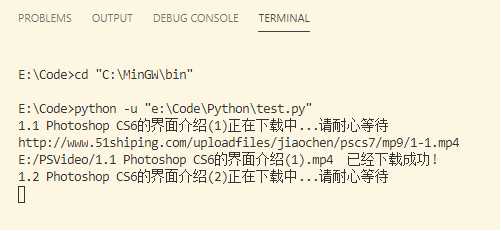
我这里网速可能还是有点慢,(同时我也怀疑是它的服务器太老啊哈哈)。
下载所有页的视频
import requests
from lxml import etree
def getVideo(n):
# 访问目录网页,n为目录的页数
list_url = "http://www.51shiping.com/list-657-{}.html".format(n)
v_url = "http://www.51shiping.com/uploadfiles/jiaochen/pscs7/mp9/" # 视频地址,用于拼接
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align=‘left‘]/a/text()")
# 下载
for title in titles:
#unicodedata.normalize(‘NFKC‘, titles[i]) # 去掉\xa0这样的空白字符
file_dir = ‘E:/PSVideo/{}.mp4‘.format(title) # 保存的路径和文件名
order = title.split(‘\xa0‘)[0] # 每节的编号
video_url = v_url+order.split(‘.‘)[0]+‘-‘+order.split(‘.‘)[1]+‘.mp4‘ # 拼接视频下载地址
print(title+‘正在下载中...请耐心等待‘);
# 下载视频
with open(file_dir,‘wb‘) as f:
f.write(requests.get(video_url,headers=headers).content)
f.flush()
print(video_url)
print(file_dir+‘ 已经下载成功!‘);
if __name__ == "__main__":
for n in range(1,7):
getVideo(1)
这个结果我就不再演示啦,(网速慢的我)
该项目利用了requests+XPath知识实现,不是很难,我是一个初学爬虫的小白,都能实现,更何况你呢~
如果能给你正在写的项目一点启发,那更是好啦!哈哈,如果觉得还可以,记得给我点个赞哦~你的赞就是对我最大的鼓励!

标签:pcs requests 字符 点击 解析 order 直接 利用 content
原文地址:https://www.cnblogs.com/AllenMi/p/13303105.html