标签:模式 sum info cas 意思 无法 加一列 date 数据
这篇文章主要梳理了 SQL 的基础用法,会涉及到以下方面内容:
SQL 是我们用来最长和数据打交道的方式之一,如果按照功能划分可分为如下 4 个部分:
平时在编写 SQL 时,可能发现许多 SQL 大小写不统一,虽然不会影响 SQL 的执行结果,但保持统一的书写规范,是提高效率的关键,通常遵循如下的原则:
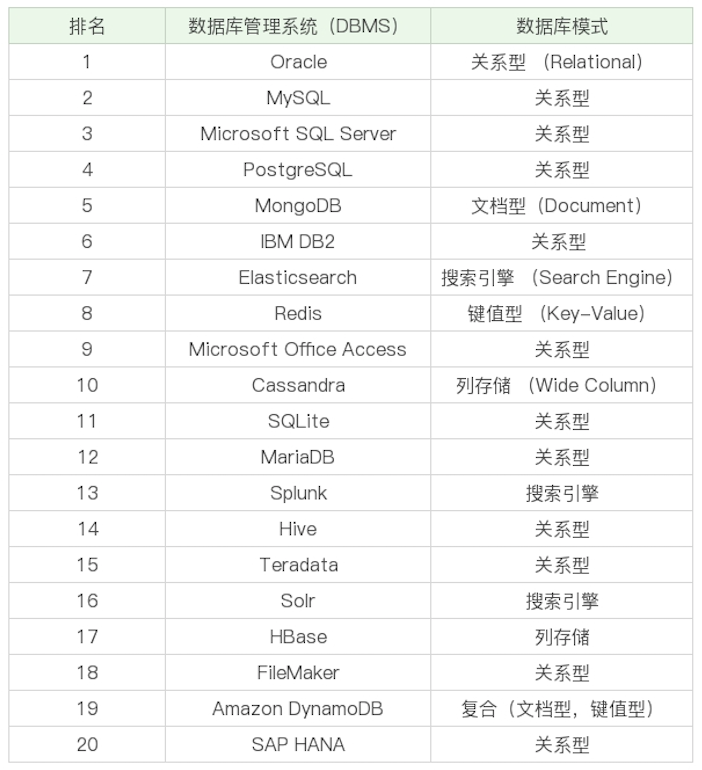
目前排名较前的 DBMS:
SELECT 一般是在学习 SQL 接触的第一个关键字,基础的内容就是不提了,这里整理常用的规范:
SELECT name AS n FROM student
SELECT ‘学生信息‘ as student_info, name FROM student
SELECT DISTINCT age FROM student
需要注意的是 DISTINCT 是对后面的所有列进行去重, 下面这种情况就会对 age 和 name 的组合进行去重。
SELECT DISTINCT age,name FROM student
如先按照 name 排序,name 相等的情况下按照 age 排序。
SELECT DISTINCT age FROM student ORDERY BY name,age DESC
SELECT DISTINCT age FROM student ORDERY BY name DESC LIMIT 5
了解了 SELECT 的执行顺序,才能更好地写出更有效率的 SQL。
对于 SELECT 顺序有两个原则:
关键字的顺序不能颠倒:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
SELECT 会按照如下顺序执行:
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
SELECT DISTINCT student_id, name, count(*) as num #顺序5
FROM student JOIN class ON student.class_id = class.class_id #顺序1
WHERE age > 18 #顺序2
GROUP BY student.class_id #顺序3
HAVING num > 2 #顺序4
ORDER BY num DESC #顺序6
LIMIT 2 #顺序7
在逐一分析下这个过程前,我们需要知道在上面的每一个步骤中都会产生一个虚拟表,然后将这个虚拟表作为下一个步骤中作为输入,但这一过程对我们来说是不可见的:
如果涉及到函数的计算比如 sum() 等,会在 GROUP BY分组后,HAVING 分组前,进行聚集函数的计算。
涉及到表达式计算,如 age * 10 等,会在 HAVING 阶段后,SELECT 阶段前进行计算。
通过这里,就可以总结出提高 SQL 效率的第一个方法:
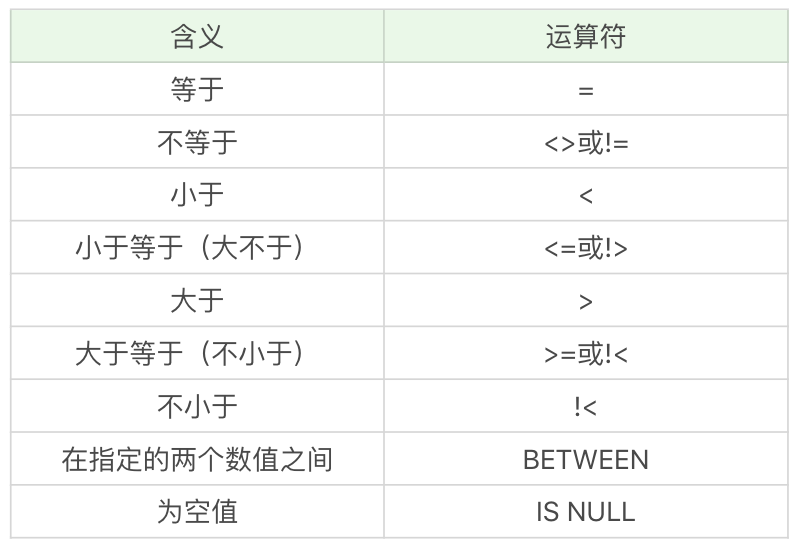
使用 WHERE 筛选时,常有通过比较运算符,逻辑运算符,通配符三种方式。
对于比较运算符,常用的运算符如下表。
对于逻辑运算符来说,可以将多个比较运行符连接起来,进行多条件的筛选,常用的运算符如下:
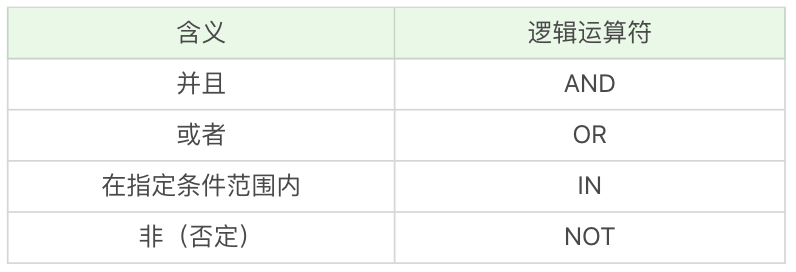
需要注意的是,当 AND 和 OR 同时出现时,AND 的优先级更高会先被执行。当如果存在 () 的话,则括号的优先级最高。
使用通配符过滤:
like:(%)代表零个或多个字符,(_)只代表一个字符
和编程语言中的定义的函数一样,SQL 同样定义了一些函数方便使用,比如求和,平均值,长度等。
常见的函数主要分为如下四类,分类的原则是根据定义列时的数据类型:
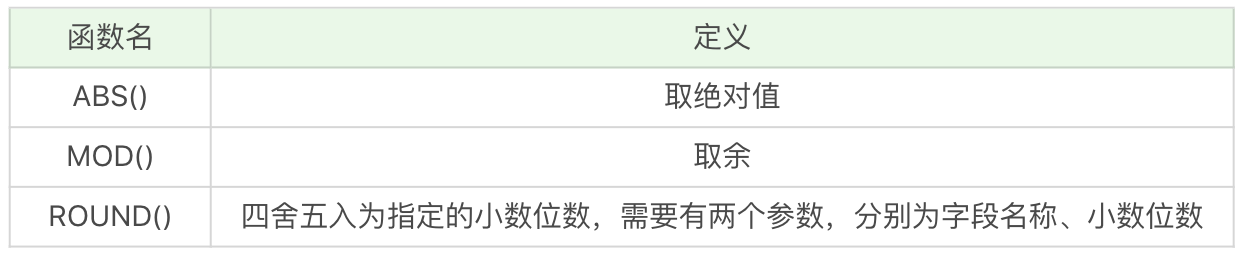
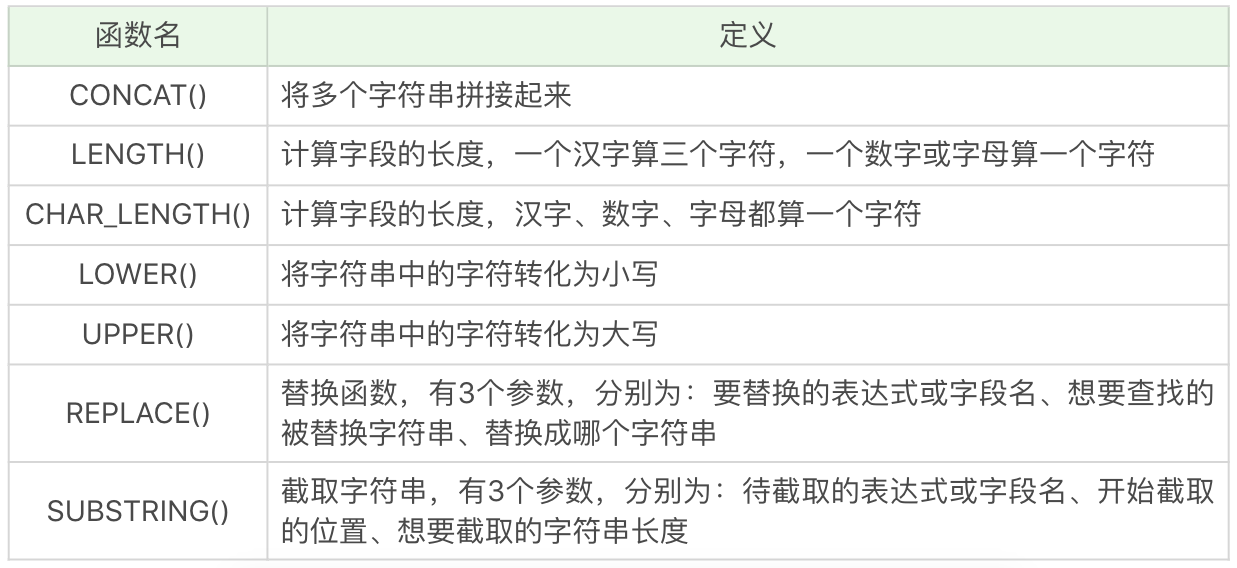
需要注意的是,在使用字符串比较日期时,要使用 DATE 函数比较。
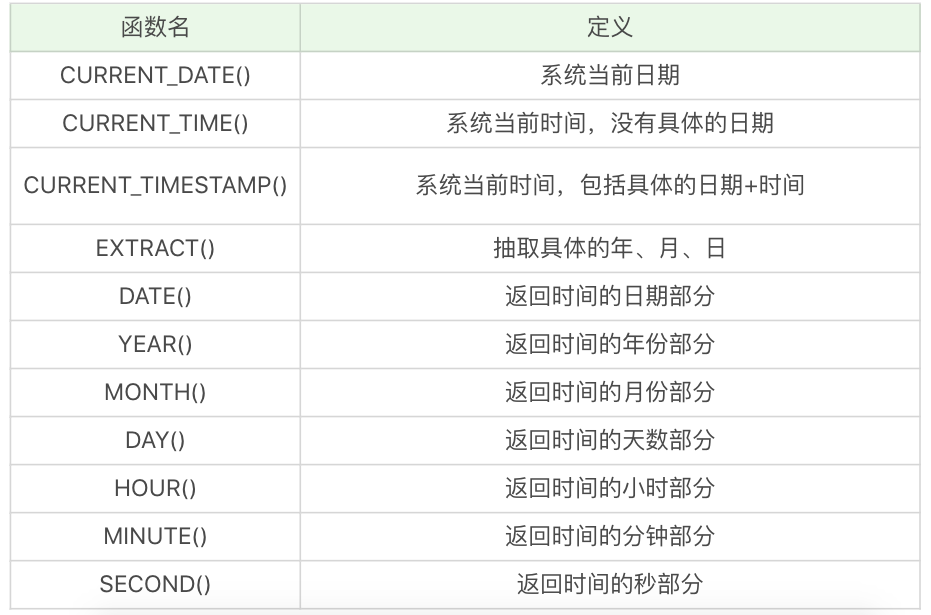

CAST 函数在转换数据类型时,不会四舍五入,如果原数值是小数,在转换到整数时会报错。
在转换时可以使用 DECIMAL(a,b) 函数来规定小数的精度,比如 DECIMAL(8,2) 表示精度为 8 位 - 小数加整数最多 8 位。小数后面最多为 2 位。
然后通过 SELECT CAST(123.123 AS DECIMAL(8,2)) 来转换。
通常情况下,我们会使用聚集函数来汇总表的数据,输入为一组数据,输出为单个值。
常用的聚集函数有 5 个:
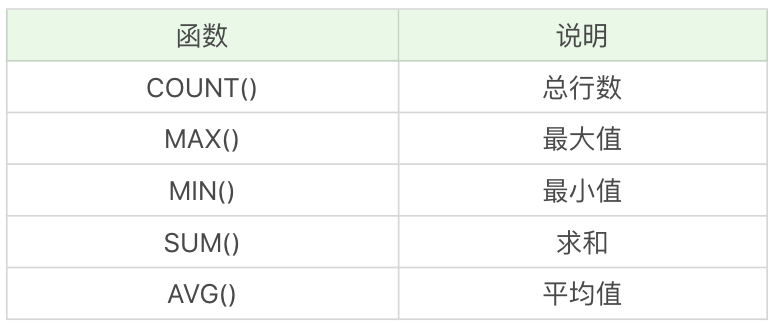
其中 COUNT 函数需要额外注意,具体的内容可以参考这篇。
在统计结果时,往往需要对数据按照一定条件进行分组,对应就是 GROUP BY 语句。
比如统计每个班级的学生人数:
SELECT class_id, COUNT(*) as student_count FROM student GROUP BY class_id;
GROUP BY 后也可接多个列名,进行分组,比如按照班级和性别分组:
SELECT class_id, sex, COUNT(*) as student_count FROM student GROUP BY class_id, sex;
和 WHERE 一样,可以对分组后的数据进行筛选。区别在于 WHERE 适用于数据行,HAVING 用于分组。
而且 WHERE 支持的操作,HAVING 也同样支持。
比如可以筛选大于2人的班级:
SELECT class_id, COUNT(*) as student_count FROM student \
GROUP BY class_id \
HAVING student_count > 20;
在一些更为复杂的情况中,往往会进行嵌套的查询,比如在获取结果后,该结果作为输入,去获取另外一组结果。
在 SQL 中,查询可以分为关联子查询和非关联子查询。
假设有如下的表结构:
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT ‘‘,
`age` int(3) NOT NULL,
`sex` varchar(10) NOT NULL DEFAULT ‘‘,
`class_id` int(11) NOT NULL COMMENT ‘班级ID‘,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of Student
-- ----------------------------
INSERT INTO `student` VALUES (‘1‘, ‘胡一‘, 13, ‘男‘, ‘1‘);
INSERT INTO `student` VALUES (‘3‘, ‘王阿‘, 11, ‘女‘, ‘1‘);
INSERT INTO `student` VALUES (‘5‘, ‘王琦‘, 12, ‘男‘, ‘1‘);
INSERT INTO `student` VALUES (‘7‘, ‘刘伟‘, 11, ‘女‘, ‘1‘);
INSERT INTO `student` VALUES (‘7‘, ‘王意识‘, 11, ‘女‘, ‘2‘);
-- ----------------------------
DROP TABLE IF EXISTS `student_activities`;
CREATE TABLE `student_activities` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT ‘‘,
`stu_id` int(11) NOT NULL COMMENT ‘班级ID‘,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
INSERT INTO `student_activities` VALUES (‘1‘, ‘博物馆‘, 1);
INSERT INTO `student_activities` VALUES (‘3, ‘春游‘, 3);
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件接着执行。
这里想要查询和胡一相同班级的同学名称:
SELECT name FROM student WHERE class_id = (SELECT class_id FROM student WHERE name=‘胡一‘)
这里先查到胡一的班级,只有一次查询,再根据该班级查找学生就是非关联子查询。
如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部
再举个例子, 比如查询比每个班级中比平均年龄大的学生姓名信息:
SELECT name FROM student as s1 WHERE age >
(SELECT AVG(age) FROM student as s2 where s1.class_id = s2.class_id)
这里根据每名同学的班级信息,查找出对应班级的平均年龄,然后做判断。子查询每次执行时,都需要根据外部的查询然后进行计算。这样的子查询就是关联子查询。
在关联子查询中,常会和 EXISTS 一起使用。用来判断条件是否满足,满足的话为 True,不满足为 False。
比如查询参加过学校活动的学生名称:
SELECT NAME FROM student as s where EXISTS(SELECT stu_id FROM student_activities as sa where sa.stu_id=s.id)
同样 NOT EXISTS 就是不存在的意思,满足为 FALSE , 不满足为 True.
比如查询没有参加过学校活动的学生名称:
SELECT NAME FROM student as s where NOT EXISTS(SELECT stu_id FROM student_activities as sa where sa.stu_id=s.id)
可以在子查询中,使用集合操作符,来比较结果。
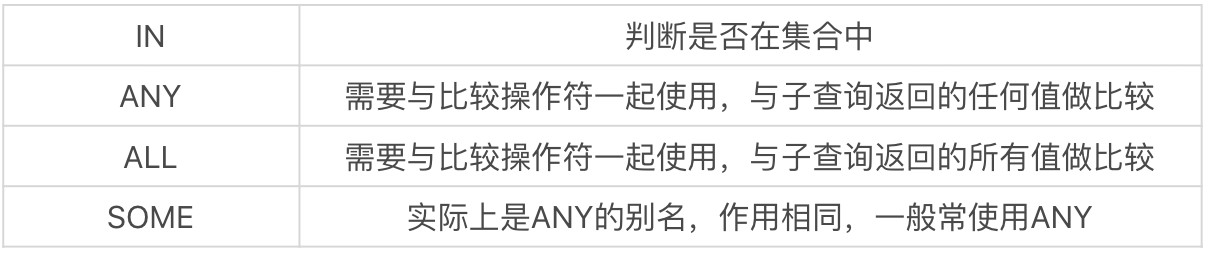
还是上面查询参加学校活动的学生名字的子查询, 同样可以使用 IN:
SELECT name FROM student WHERE id IN (SELECT stu_id FROM student_activities)
既然 EXISTS 和 IN 都能实现相同的功能,那么他们之间的区别是什么?
现在假设我们有表 A 和 表 B,其中 A,B 都有字段 cc,并对 cc 建立了 b+ 索引,其中 A 表 n 条记录,B 表 m 条索引。
将其模式抽象为:
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXIST (SELECT cc FROM B WHERE B.cc=A.cc)
对于 EXISTS 来说,会先对外表进行逐条循环,每次拿到外表的结果后,带入子查询的内表中,去判断该值是否存在。
伪代码类似于下面:
for i in A
for j in B
if j.cc == i.cc:
return result
首先先看外表 A,每一条都需要遍历到,所以需要 n 次。内表 B,在查询时由于使用索引进而查询效率变成 log(m) B+ 的树高,而不是 m。
进而总效率:n * log(m)
所以对于 A 表的数量明显小于 B 时,推荐使用 EXISTS 查询。
再看 IN ,会先对内表 B 进行查询,然后用外表 A 进行判断,伪代码如下:
for i in B
for j in A
if j.cc == i.cc:
return result
由于需要首先将内表所有数据查出,所以需要的次数就是 m. 再看外表 A ,由于使用了 cc 索引,可将 n 简化至 log(n), 也就是 m * log(n).
所以对于 A 表的数据明显大于 B 表时,推荐使用 IN 查询。
总结一下对于 IN 和 EXISTS时,采用小表驱动大表的原则。
这里再扩展下 NOT EXISTS 和 NOT IN 的区别:
SELECT * FROM A WHERE cc NOT IN (SELECT cc FROM B)
SELECT * FROM A WHERE NOT EXIST (SELECT cc FROM B WHERE B.cc=A.cc)
对于 NOT EXITS 来说,和 EXISTS 一样,对于内表可以使用 cc 的索引。适用于 A 表小于 B 表的情况。
但对于 NOT IN 来说,和 IN 就有区别了,由于 cc 设置了索引 cc IN (1, 2, 3) 可以转换成 WHERE cc=1 OR cc=2 OR cc=3 , 是可以正常走 cc 索引的。但对于 NOT IN 也就是转化为 cc!=1 OR cc!=2 OR cc!=3 这时由于是不等号查询,是无法走索引的,进而全表扫描。
也就是说,在设置索引的情况下 NOT EXISTS 比 NOT IN 的效率高。
但对于没有索引的情况,IN 和 OR 是不同的:
一、操作不同
1、in:in是把父查询表和子查询表作hash连接。
2、or:or是对父查询表作loop循环,每次loop循环再对子查询表进行查询。
二、适用场景不同
1、in:in适合用于子查询表数据比父查询表数据多的情况。
2、or:or适合用于子查询表数据比父查询表数据少的情况。
三、效率不同
1、in:在没有索引的情况下,随着in后面的数据量越多,in的执行效率不会有太大的下降。
2、or:在没有索引的情况下,随着or后面的数据量越多,or的执行效率会有明显的下降。
这篇文章中主要归纳了一些 SQL 的基础知识:
在使用 SELECT 查询时,通过显式指定列名,来减少 IO 的传输,从而提高效率。
并且需要注意 SELECT 的查询过程会从 FROM 后开始到 LIMIT 结束,理解了整体的流程,可以让我们更好的组织 SQL.
之后详细介绍了 WHERE 进行过滤的操作符和常用的函数,这里要注意在比较时间时要使用 DATE 函数,以及如何对数据进行分组和过滤。
最后着重介绍了子查询,IN 和 EXISTS 的适用场景。
标签:模式 sum info cas 意思 无法 加一列 date 数据
原文地址:https://www.cnblogs.com/michael9/p/13305154.html