标签:UNC 处理 逻辑 又能 大于 miss 流程 图形化界面 first
数据库的相关概念
**DBMS、DB、SQL**DB:database数据库,存储一系列有组织数据的容器
DBMS:Database Management System数据库管理系统,使用DBMS管理和维护DB
SQL:StructureQueryLanguage结构化查询语言,程序员用于和DBMS通信的语言
MySQL服务的登录和退出 ★
**方式一:通过dos命令**
mysql -h主机名 -P端口号 -u用户名 -p密码
**注意:**
如果是本机,则-h主机名 可以省略
如果端口号是3306,则-P端口号可以省略
**方式二:通过图形化界面客户端**
通过sqlyog,直接输入用户名、密码等连接进去即可
MySQL的常见命令和语法规范
**①常见命令**
show databases 显示当前连接下所有数据库
show tables 显示当前库中所有表
show tables from 库名 显示指定库中所有表
show columns from 表名 显示指定表中所有列
use 库名 打开/使用指定库
**②语法规范**
不区分大小写
每条命令结尾建议用分号
注释:
#单行注释
-- 单行注释
/*多行注释*/
补充函数
select version();
select database();
select user();
select ifnull(字段名,表达式);
select concat(字符1,字符2,字符3);
select length(字符/字段);获取字节长度
逻辑运算符:and or not
模糊查询
like:一般和通配符搭配使用
? _ 任意单个字符
? % 任意多个字符
between and:一般用于判断某字段是否在指定的区间
a between 10 and 100
in:一般用于判断某字段是否在指定的列表
a in(10,30,50)
升序,通过asc
降序,通过desc

基础查询:
SELECT 查询列表 FROM 表名;
特点:
1、查询的结果集 是一个虚拟表
2、SELECT后面跟的查询列表,可以有多个部分组成,中间用逗号隔开
例如:SELECT 字段1,字段2,表达式 FROM 表;
3、执行顺序
① FROM子句
② SELECT子句
4、查询列表可以是:字段、表达式、常量、函数等
一、查询常量
SELECT 100 ;
二、查询表达式
SELECT 100%3;
三、查询单个字段
SELECT `last_name` FROM `employees`;
四、查询多个字段
SELECT `last_name`,`email`,`employee_id` FROM employees;
五、查询所有字段
SELECT * FROM `employees`;
F12:对齐格式
SELECT
`last_name`,
`first_name`,
`last_name`,
`commission_pct`,
`hiredate`,
`salary`
FROM
employees ;
六、查询函数(调用函数,获取返回值)
SELECT DATABASE();
SELECT VERSION();
SELECT USER();
七、起别名
方式一:使用AS关键字
SELECT USER() AS 用户名;
SELECT USER() AS "用户名";
SELECT USER() AS ‘用户名‘;
SELECT last_name AS "姓 名" FROM employees;
方式二:使用空格
SELECT USER() 用户名;
SELECT USER() "用户名";
SELECT USER() ‘用户名‘;
SELECT last_name "姓 名" FROM employees;
八、+的作用
mysql中+的作用:
1、加法运算
①两个操作数都是数值型
100+1.5
②其中一个操作数为字符型
将字符型数据强制转换成数值型,如果无法转换,则直接当做0处理
‘张无忌‘+100--->100
③其中一个操作数为NULL
NULL+NULL--->NULL
NULL+100--->NULL
#需求:查询 first_name 和last_name 拼接成的全名,最终起别名为:姓 名
使用CONCAT拼接函数
SELECT CONCAT(first_name,last_name) AS "姓 名"
FROM employees;
九、DISTINCT的使用(只返回不同的值)
-- 需求:查询员工涉及到的部门编号有哪些,不重复
SELECT DISTINCT department_id FROM employees;
十、查看表的结构
①、DESC employees;
②、SHOW COLUMNS FROM employees;
基础查询
条件查询
语法:
SELECT 查询列表
FROM 表名
WHERE 筛选条件;
执行顺序:
①FROM子句
②WHERE子句
③SELECT子句
SELECT last_name,first_name
FROM employees
WHERE salary>20000;
特点:
1、按关系表达式筛选
关系运算符:> < >= <= = <>(不等于)
2、按逻辑表达式筛选
逻辑运算符:AND OR NOT
3、模糊查询
LIKE
IN
BETWEEN AND
IS NULL
一、按关系表达式筛选
#案例1:查询部门编号不是100的员工信息
SELECT *
FROM employees
WHERE department_id <> 100;
#案例2:查询工资<15000的姓名、工资
SELECT last_name,salary
FROM employees
WHERE salary<15000;
二、按逻辑表达式筛选
#案例1:查询部门编号不是 50-100之间员工姓名、部门编号、邮箱
方式1:
SELECT last_name,department_id,email
FROM employees
WHERE department_id <50 OR department_id>100;
方式2:
SELECT last_name,department_id,email
FROM employees
WHERE NOT(department_id>=50 AND department_id<=100);
#案例2:查询奖金率>0.03 或者 员工编号在60-110之间的员工信息
SELECT *
FROM employees
WHERE commission_pct>0.03 OR (employee_id >=60 AND employee_id<=110);
三、模糊查询
1、LIKE
功能:一般和通配符搭配使用,对字符型数据进行部分匹配查询
常见的通配符:
_ 任意单个字符
% 任意多个字符,支持0-多个
LIKE/NOT LIKE
#案例1:查询姓名中包含字符a的员工信息
SELECT *
FROM employees
WHERE last_name LIKE ‘%a%‘;
#案例2:查询姓名中包含最后一个字符为e的员工信息
SELECT *
FROM employees
WHERE last_name LIKE ‘%e‘;
#案例3:查询姓名中包含第一个字符为e的员工信息
SELECT *
FROM employees
WHERE last_name LIKE ‘e%‘;
#案例4:查询姓名中包含第三个字符为x的员工信息
SELECT *
FROM employees
WHERE last_name LIKE ‘__x%‘;
#案例5:查询姓名中包含第二个字符为_的员工信息
SELECT *
FROM employees
WHERE last_name LIKE ‘_\_%‘;
SELECT *
FROM employees
WHERE last_name LIKE ‘_$_%‘ ESCAPE ‘$‘;
2、IN
功能:查询某字段的值是否属于指定的列表之内
a IN(常量值1,常量值2,常量值3,...)
a NOT IN(常量值1,常量值2,常量值3,...)
IN/NOT IN
#案例1:查询部门编号是30/50/90的员工名、部门编号
方式1:
SELECT last_name,department_id
FROM employees
WHERE department_id IN(30,50,90);
方式2:
SELECT last_name,department_id
FROM employees
WHERE department_id = 30
OR department_id = 50
OR department_id = 90;
案例2:查询工种编号不是SH_CLERK或IT_PROG的员工信息
#方式1:
SELECT *
FROM employees
WHERE job_id NOT IN(‘SH_CLERK‘,‘IT_PROG‘);
#方式2:
SELECT *
FROM employees
WHERE NOT(job_id =‘SH_CLERK‘OR job_id = ‘IT_PROG‘);
3、BETWEEN AND
功能:判断某个字段的值是否介于X,X之间
BETWEEN AND/NOT BETWEEN AND
#案例1:查询部门编号是30-90之间的部门编号、员工姓名
方式1:
SELECT department_id,last_name
FROM employees
WHERE department_id BETWEEN 30 AND 90;
方式2:
SELECT department_id,last_name
FROM employees
WHERE department_id>=30 AND department_id<=90;
#案例2:查询年薪不是100000-200000之间的员工姓名、工资、年薪
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) AS 年薪
FROM employees
WHERE salary*12*(1+IFNULL(commission_pct,0))<100000 OR salary*12*(1+IFNULL(commission_pct,0))>200000;
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
WHERE salary*12*(1+IFNULL(commission_pct,0)) NOT BETWEEN 100000 AND 200000;
4、IS NULL/IS NOT NULL
#案例1:查询没有奖金的员工信息
SELECT *
FROM employees
WHERE commission_pct IS NULL;
#案例2:查询有奖金的员工信息
SELECT *
FROM employees
WHERE commission_pct IS NOT NULL;
SELECT *
FROM employees
WHERE salary IS 10000;(报错!)
----------------=与IS的对比------------------------------------
= 只能判断普通的内容
IS 只能判断NULL值
<=> 安全等于,既能判断普通内容,又能判断NULL值,不建议用,阅读性差
条件查询
排序查询
语法:
SELECT 查询列表
FROM 表名
【WHERE 筛选条件】
ORDER BY 排序列表
执行顺序:
①FROM子句
②WHERE子句
③SELECT子句
④ORDER BY 子句
举例:
SELECT last_name,salary
FROM employees
WHERE salary>20000
ORDER BY salary ;
特点:
1、排序列表可以是单个字段、多个字段、表达式、函数、列数、以及以上的组合
2、升序 ,通过 ASC ,默认行为
降序 ,通过 DESC
一、按单个字段排序
#案例1:将员工编号>120的员工信息进行工资的升序
SELECT *
FROM employees
ORDER BY salary ;
#案例1:将员工编号>120的员工信息进行工资的降序
SELECT *
FROM employees
WHERE employee_id>120
ORDER BY salary DESC;
二、按表达式排序
#案例1:对有奖金的员工,按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
三、按别名排序
#案例1:对有奖金的员工,按年薪降序
SELECT *,salary*12*(1+commission_pct,0) 年薪
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY 年薪 DESC;
思考为什么WHERE不能用别名进行判断?
因为是代码运行顺序的问题。
四、按函数的结果排序
#案例1:按姓名的字数长度进行升序
SELECT last_name
FROM employees
ORDER BY LENGTH(last_name);
五、按多个字段排序
#案例1:查询员工的姓名、工资、部门编号,先按工资升序,再按部门编号降序
SELECT last_name,salary,department_id
FROM employees
ORDER BY salary ASC,department_id DESC;
六、补充选学:按列数排序
SELECT * FROM employees
ORDER BY 2 DESC;
SELECT * FROM employees
ORDER BY first_name;
排序查询
注意: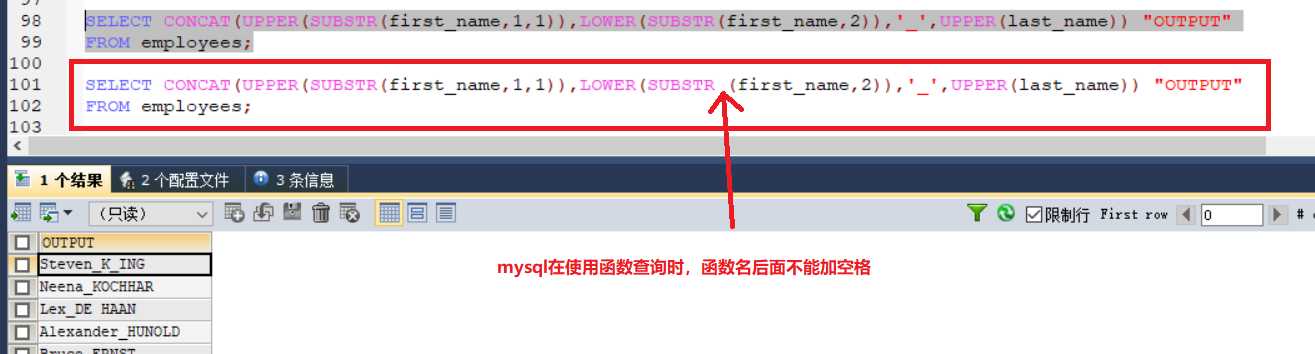
常见函数
函数:为了实现某个功能,将编写的一系列的命令集合封装在一起,对外仅仅显示方法名,供外部调用
1、自定义方法(函数)
2、调用方法(函数)★
叫什么 :函数名
干什么 :函数功能
常见函数(需掌握):
单行函数
字符函数
CONCAT
SUBSTR
LENGTH(str)
CHAR_LENGTH
UPPER
LOWER
TRIM
LEFT
RIGHT
LPAD
RPAD
INSTR
STRCMP
数学函数
ABS
CEIL
FLOOR
ROUND
TRUNCATE
MOD
日期函数
NOW
CURTIME
CURDATE
DATEDIFF
DATE_FORMAT
STR_TO_DATE
流程控制函数
IF
CASE
#一、字符函数
1、CONCAT 拼接字符
SELECT CONCAT(‘hello,‘,first_name,last_name) 备注 FROM employees;
2、LENGTH 获取字节长度,字节长度与数字编码格式有关
SELECT LENGTH(‘hello,郭襄‘);
3、CHAR_LENGTH 获取字符个数
SELECT CHAR_LENGTH(‘hello,郭襄‘);
4、SUBSTRING 截取子串
/*
注意:起始索引从1开始!!!
substr(str,起始索引,截取的字符长度)
substr(str,起始索引)没有第三个参数的话就是截取索引之后所有的值
*/
SELECT SUBSTR(‘张三丰爱上了郭襄‘,1,3);--->张三丰
SELECT SUBSTR(‘张三丰爱上了郭襄‘,7);--->郭襄
5、INSTR获取字符第一次出现的索引
SELECT INSTR(‘三打白骨精aaa白骨精bb白骨精‘,‘白骨精‘);--->3
6、TRIM去前后指定的字符,默认是去空格
SELECT TRIM(‘ 虚 竹 ‘) AS a;--->虚 竹
SELECT TRIM(‘x‘ FROM ‘xxxxxx虚xxx竹xxxxxxxxxxxxxxxxxx‘) AS a;--->虚xxx竹
7、LPAD/RPAD 左填充/右填充,10代表总共的字符个数
SELECT LPAD(‘木婉清‘,5,‘a‘);--->aa木婉清
SELECT RPAD(‘木婉清‘,5,‘a‘);--->木婉清aa
8、UPPER/LOWER 变大写/变小写
#案例:查询员工表的姓名,要求格式:姓首字符大写,其他字符小写,名所有字符大写,且姓和名之间用_分割,最后起别名“OUTPUT”
SELECT CONCAT(UPPER(SUBSTR(first_name,1,1)),LOWER(SUBSTR(first_name,2)),‘_‘,UPPER(last_name)) "OUTPUT"
FROM employees;
9、STRCMP 比较两个字符大小
SELECT STRCMP(‘aec‘,‘aec‘);
参数1大于参数2显示1,小于显示-1,等于显示0
10、LEFT/RIGHT 截取子串
SELECT LEFT(‘鸠摩智‘,1);--->鸠
SELECT RIGHT(‘鸠摩智‘,1);--->智
#二、数学函数
1、ABS 绝对值
SELECT ABS(-2.4);--->2.4
2、CEIL 向上取整 返回>=该参数的最小整数
SELECT CEIL(-1.09);
SELECT CEIL(0.09);
SELECT CEIL(1.00);
3、FLOOR 向下取整,返回<=该参数的最大整数
SELECT FLOOR(-1.09);
SELECT FLOOR(0.09);
SELECT FLOOR(1.00);
4、ROUND 四舍五入
SELECT ROUND(1.8712345);
SELECT ROUND(1.8712345,2); 2代表小数点后几位
5、TRUNCATE 截断
SELECT TRUNCATE(1.8712345,1);参数2表示截断小数点后几位
6、MOD 取余
SELECT MOD(-10,3);
a%b = a-a/b*b
-10%3 = -10 - (-10)/3*3 = -1
SELECT -10%3;
SELECT 10%3;
SELECT -10%-3;
SELECT 10%-3;
#三、日期函数
1、NOW 当前日期,时间
SELECT NOW();
2、CURDATE 当前日期
SELECT CURDATE();
3、CURTIME 当前时间
SELECT CURTIME();
4、DATEDIFF 两个日期差值,参数1减参数2
SELECT DATEDIFF(‘1998-7-16‘,‘2019-7-13‘);
5、DATE_FORMAT 将参数1按照转换成指定格式
SELECT DATE_FORMAT(‘1998-7-16‘,‘%Y年%m月%d日 %H小时%i分钟%s秒‘) 出生日期;
1998年07月16日 00小时00分钟00秒
6、STR_TO_DATE 按指定格式解析字符串为日期类型,这样字符串就能和日期比较
SELECT * FROM employees
WHERE hiredate<STR_TO_DATE(‘3/15 1998‘,‘%m/%d %Y‘);
#四、流程控制函数
1、IF函数
SELECT IF(100>9,‘好‘,‘坏‘);
如果 100>9,显示好,否则显示坏
#需求:如果有奖金,则显示最终奖金,如果没有,则显示0
SELECT IF(commission_pct IS NULL,0,salary*12*commission_pct) 奖金
FROM employees;
2、CASE函数
情况1 :实现等值判断
CASE 表达式
WHEN 值1 THEN 结果1
WHEN 值2 THEN 结果2
...
ELSE 结果n
END
案例:
部门编号是30,工资显示为2倍
部门编号是50,工资显示为3倍
部门编号是60,工资显示为4倍
否则不变
显示 部门编号,新工资,旧工资
SELECT department_id,salary,
CASE department_id
WHEN 30 THEN salary*2
WHEN 50 THEN salary*3
WHEN 60 THEN salary*4
ELSE salary
END newSalary
FROM employees;
②情况2:类似于多重IF语句,实现区间判断
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
...
ELSE 结果n
END
案例:如果工资>20000,显示级别A
工资>15000,显示级别B
工资>10000,显示级别C
否则,显示D
SELECT salary,
CASE
WHEN salary>20000 THEN ‘A‘
WHEN salary>15000 THEN ‘B‘
WHEN salary>10000 THEN ‘C‘
ELSE ‘D‘
END AS "级别"
FROM employees;
常见函数
聚合函数
说明:分组函数往往用于实现将一组数据进行统计计算,最终得到一个值,又称为统计函数
分组函数清单:
SUM(字段名):求和
AVG(字段名):求平均数
MAX(字段名):求最大值
MIN(字段名):求最小值
COUNT(字段名):计算非空字段值的个数
#案例1 :查询员工信息表中,所有员工的工资和、工资平均值、最低工资、最高工资、有工资的个数
SELECT SUM(salary),AVG(salary),MIN(salary),MAX(salary),COUNT(salary)
FROM employees;
#案例2:添加筛选条件
? #①查询employee_id表中记录数:
SELECT COUNT(employee_id) FROM employees;
? #②查询employee_id表中有佣金的人数:
SELECT COUNT(salary) FROM employees;
? #③查询employee_id表中月薪大于2500的人数:
SELECT COUNT(salary) FROM employees WHERE salary>2500;
?
? #④查询有领导的人数:
SELECT COUNT(manager_id) FROM employees;
#count的补充介绍★
#1、统计结果集的行数,推荐使用count(*)
SELECT COUNT(*) FROM employees;
SELECT COUNT(*) FROM employees WHERE department_id = 30;
COUNT(1)表示给数据添加了一列内容为1的数据,然后计算数据为1的行数
SELECT COUNT(1) FROM employees;
SELECT COUNT(1) FROM employees WHERE department_id = 30;
#2、搭配distinct实现去重的统计
#需求:查询有员工的部门个数
SELECT COUNT(DISTINCT department_id) FROM employees;
聚合函数
分组查询
语法:
SELECT 查询列表
FROM 表名
WHERE 筛选条件
GROUP BY 分组列表
HAVING 分组后筛选
ORDER BY 排序列表;
执行顺序:
①FROM子句
②WHERE子句
③GROUP BY 子句
④HAVING子句
⑤SELECT子句
⑥ORDER BY子句
特点:
①查询列表往往是 聚合函数和被分组的字段 ★
②分组查询中的筛选分为两类
筛选的基表 使用的关键词 位置
分组前筛选 原始表(FROM 后面的) WHERE GROUP BY 的前面
分组后筛选 分组后的结果集 HAVING GROUP BY 的后面
WHERE——GROUP BY ——HAVING
聚合函数做条件只可能放在HAVING后面!!!
简单的分组
#案例1:查询每个工种的员工平均工资
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
#案例2:查询每个领导的手下人数
SELECT COUNT(*),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id;
可以实现分组前的筛选
#案例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary) 最高工资,department_id
FROM employees
WHERE email LIKE ‘%a%‘
GROUP BY department_id;
#案例2:查询每个领导手下有奖金的员工的平均工资
SELECT AVG(salary) 平均工资,manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
可以实现分组后的筛选
#案例1:查询哪个部门的员工个数>5
SELECT COUNT(*) 员工个数,department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
#案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
#案例3:领导编号>102的每个领导手下的最低工资大于5000的最低工资
SELECT MIN(salary) 最低工资,manager_id
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000 ;
可以实现排序
#案例:查询没有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
HAVING MAX(salary)>6000
ORDER BY MAX(salary) ASC;
按多个字段分组
#案例:查询每个工种每个部门的最低工资,并按最低工资降序
提示:工种和部门都一样,才是一组
SELECT MIN(salary) 最低工资,job_id,department_id
FROM employees
GROUP BY job_id,department_id
ORDER BY MIN(salary) DESC;
分组查询
标签:UNC 处理 逻辑 又能 大于 miss 流程 图形化界面 first
原文地址:https://www.cnblogs.com/zrh918/p/13295794.html