标签:操作系统 cpu excel 通用 rop 获取 因此 中断 mysql数据库
MySQL数据库自己用了也有两三年了,基本上只是掌握增删改查的sql语句,从没有思考过MySQL的内部到底是怎么根据sql查询数据的,包括索引的原理,只知道加了索引查的就快,不知道为什么加上索引效率就会提升,包括索引的限制和优化也知之甚少,所以决定开一专题来学习与记录MySQL。
下图是一条查询sql语句的执行流程:
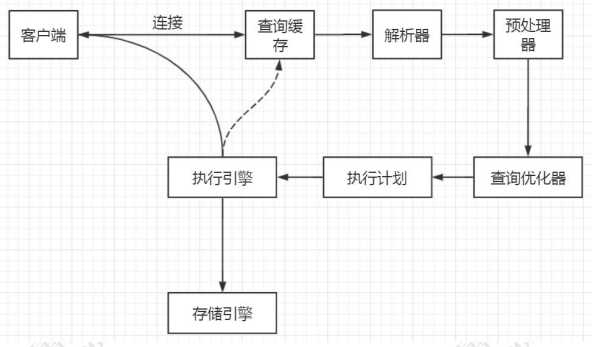
我们的程序或者工具要操作数据库,第一步要做什么事情?当然是跟数据库建立连接。首先,MySQL 必须要运行一个服务,监听默认的 3306 端口。在我们开发系统跟第三方对接的时候,必须要弄清楚的有两件事。第一个就是通信协议,比如我们是用 HTTP 还是 WebService 还是 TCP?第二个是消息格式,比如我们用 XML 格式,还是 JSON 格式,还是定长格式?报文头长度多少,包含什么内容,每个字段的详细含义。
MySQL 是支持多种通信协议的,可以使用同步/异步的方式,支持长连接/短连接。这里我们拆分来看。第一个是通信类型。
show global variables like ‘wait_timeout‘; -- 非交互式超时时间,如 JDBC 程序 show global variables like ‘interactive_timeout‘; -- 交互式超时时间,如数据库工具
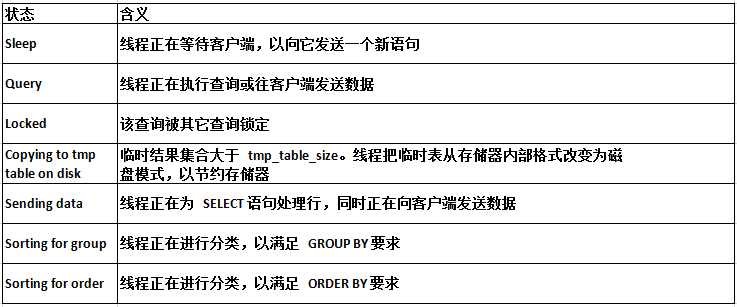
show global status like ‘Thread%‘; Threads_cached:缓存中的线程连接数。 Threads_connected:当前打开的连接数。 Threads_created:为处理连接创建的线程数。 Threads_running:非睡眠状态的连接数,通常指并发连接数。
 MySQL 服务允许的最大连接数是多少呢?在 5.7 版本中默认是 151 个,最大可以设置成 16384(2^14)。
MySQL 服务允许的最大连接数是多少呢?在 5.7 版本中默认是 151 个,最大可以设置成 16384(2^14)。show variables like ‘max_connections‘;
set global max_connections = 1000;
mysql -h192.168.8.211 -uroot -p123456

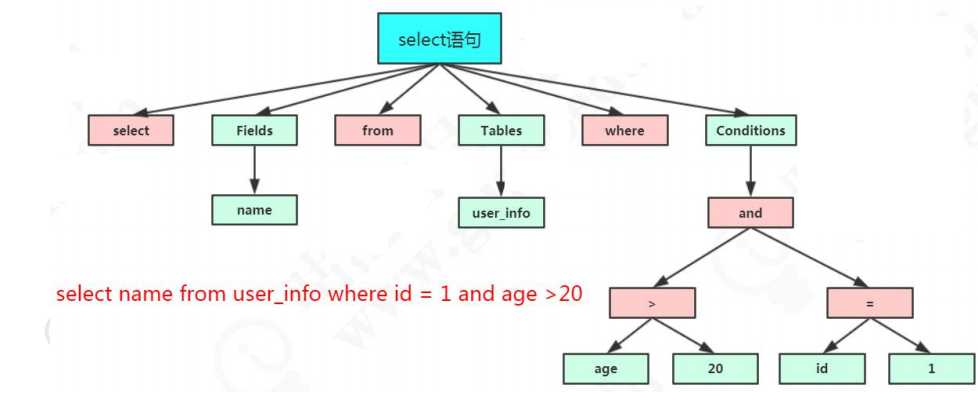
一直很好奇为什么我的一条 SQL 语句能够被识别呢?假如我随便执行一个字符串 penyuyan,服务器报了一个 1064 的错,它是怎么知道我输入的内容是错误的?这个就是 MySQL 的 Parser 解析器和 Preprocessor 预处理模块。这一步主要做的事情是对语句基于 SQL 语法进行词法和语法分析和语义的解析。
select name from user where id = 1;
select * from penyuyan;
show status like ‘Last_query_cost‘;
EXPLAIN select name from user where id=1;
show variables like ‘datadir‘;
默认情况下,每个数据库有一个自己文件夹,任何一个存储引擎都有一个 frm 文件,这个是表结构定义文件。

不同的存储引擎存放数据的方式不一样,产生的文件也不一样,innodb 是 1 个,memory 没有,myisam 是两个。 主要介绍一下InnoDB:
1.6 执行引擎,返回结果
执行引擎利用存储引擎提供的相应的 API 来完成操作。为什么我们修改了表的存储引擎,操作方式不需要做任何改变?因为不同功能的存储引擎实现的 API 是相同的。
基于上面分析的流程,我们一起来梳理一下 MySQL 的内部模块。
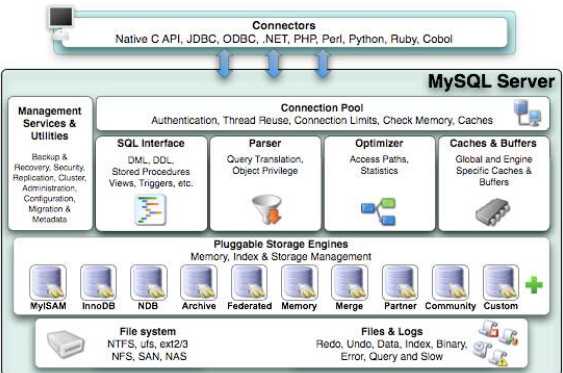
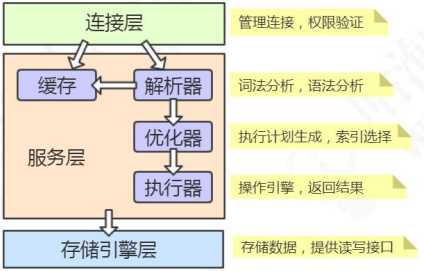
我们的客户端要连接到 MySQL 服务器 3306 端口,必须要跟服务端建立连接,那么管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成。

下一次读取相同的页,先判断是不是在缓冲池里面,如果是,就直接读取,不用再次访问磁盘。
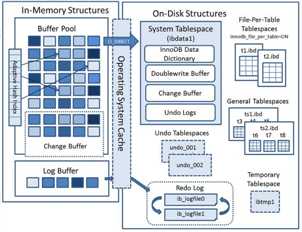 3.3.1.内存结构
3.3.1.内存结构Buffer Pool 主要分为 3 个部分: Buffer Pool、Change Buffer、Adaptive HashIndex,另外还有一个(redo)log buffer。
SHOW VARIABLES LIKE ‘innodb_change_buffer_max_size‘;
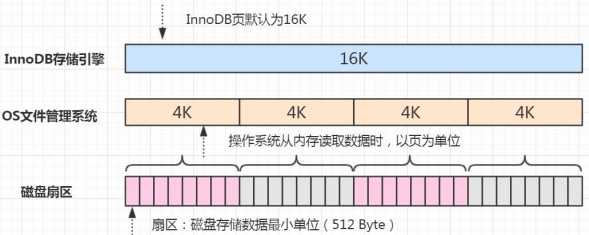
如果存储引擎正在写入页的数据到磁盘时发生了宕机,可能出现页只写了一部分的情况,比如只写了 4K,就宕机了,这种情况叫做部分写失效(partial page write),可
SHOW VARIABLES LIKE ‘innodb_file_per_table‘;
create tablespace ts2673 add datafile ‘/var/lib/mysql/ts2673.ibd‘ file_block_size=16K engine=innodb;
create table t2673(id integer) tablespace ts2673;
drop table t2673;
drop tablespace ts2673;
update user set name = ‘penyuyan‘ where id=1;
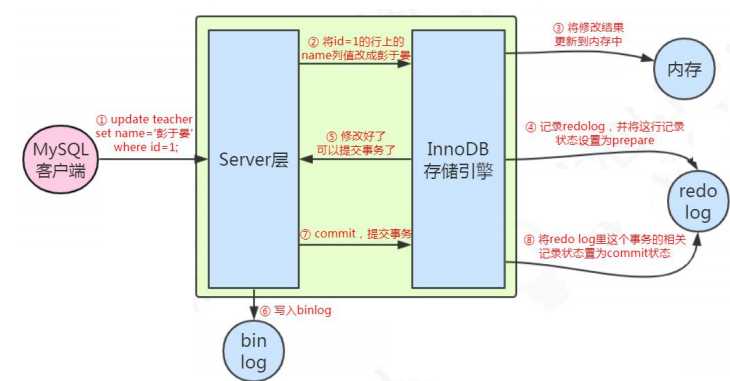
例如一条语句:update teacher set name=‘盆鱼宴‘ where id=1;
标签:操作系统 cpu excel 通用 rop 获取 因此 中断 mysql数据库
原文地址:https://www.cnblogs.com/talkingcat/p/13304554.html