标签:image 倍增 lazy com 示意图 turn http 实现 ret
后缀数组就是字符串的每个后缀的排序。
主要有两个sa和rk两个数组,sa[i]代表第i大的后缀的位置,rk[i]代表位置i的后缀的排位。满足rk[sa[i]] = sa[rk[i]] = i
有很多求后缀数组的方法,其中一种是倍增法。
先给字符串每一位排序,然后倍增排序。假设当前倍增长度为\(2^k\),那么对于位置i,以rk[i]为第一关键字,rk[i+\(2^k\)]为第二关键字排序。
时间复杂度O(n(logn)^2)。
偷个oiwiki的图,倍增排序示意图:
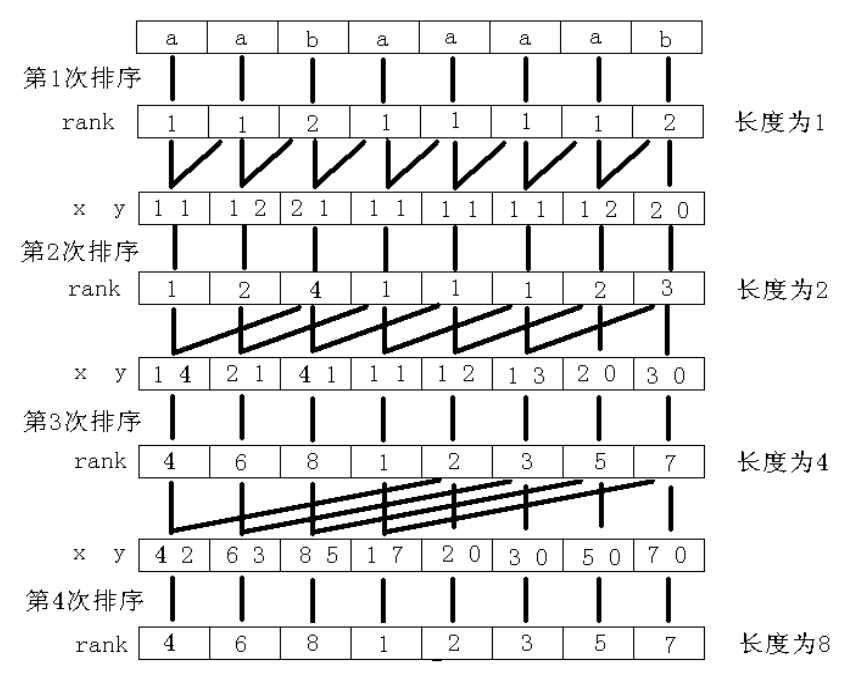
还有O(n)的复杂度的方法,有机会再补了。
const int N = 2e5 + 10;
int sa[N], rk[N << 1], oldrk[N << 1]; //倍增要开两倍空间,每次排序的格式化也要格式化两倍空间(重要)
char s[N];
int main() {
IOS;
cin >> s + 1;
int n = strlen(s + 1);
for(int i = 1; i <= n; i++) {
rk[i] = s[i] - ‘a‘ + 1; //由于rk初始化为0,所以一开始要从1开始
}
for(int i = 1; i <= n; i++) sa[i] = i;
for(int w = 1; w < n; w <<= 1) {
for(int i = 1; i <= n; i++) sa[i] = i;
sort(sa + 1, sa + n + 1, [w](int x, int y) {return rk[x] == rk[y] ? rk[x + w] < rk[y + w] : rk[x] < rk[y];});
for(int i = 0; i <= (n << 1); i++) oldrk[i] = rk[i]; //两倍空间,拷贝要完整地拷贝
int p = 0;
for(int i = 1; i <= n; i++) {
if(oldrk[sa[i]] == oldrk[sa[i - 1]] && oldrk[sa[i] + w] == oldrk[sa[i - 1] + w]) {
rk[sa[i]] = p;
} else {
rk[sa[i]] = ++p;
}
}
}
for(int i = 1; i <= n; i++) cout << sa[i] << " ";
cout << endl;
}
\(height[i] = lcp(sa[i], sa[i-1])\), 即第i名的后缀与它前一名的后缀的最长公共前缀。
具体就是使用引理\(height[rk[i]] \le height[rk[i-1]]-1\)来暴力求,时间复杂度O(n)。
int k = 0;
for(int i = 1; i <= n; i++) {
if(k) k--;
while(i + k < n && s[i + k] == s[sa[rk[i] - 1] + k]) k++;
ht[rk[i]] = k;
}
for(int i = 2; i <= n; i++) cout << ht[i] << " ";
cout << endl;
标签:image 倍增 lazy com 示意图 turn http 实现 ret
原文地址:https://www.cnblogs.com/limil/p/13324522.html