标签:start 之间 通过 document class when 需要 检查 number
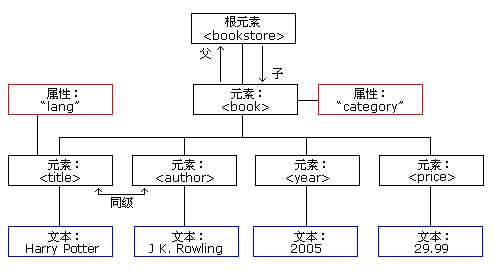
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
如需读取和更新 - 创建和处理 - 一个 XML 文档,则需要 XML 解析器。
PHP内置了两个XML解析器:Expat和DOM,和一个处理XML函数:SimpleXML
有两种基本的 XML 解析器类型:
与 DOM 或 Expat 解析器相比,SimpleXML 仅仅用几行代码就可以从 XML 元素中读取文本数据。
当执行类似下列的基础任务时,SimpleXML 使用起来非常快捷:
然而,在处理高级 XML 时,比如命名空间,最好使用 Expat 解析器或 XML DOM。
<from>Jani</from>上面的 XML 实例包含了格式良好的 XML。不过这个实例是无效的 XML,因为没有与它关联的文档类型声明 (DTD)。比如
<?xml version="1.0" encoding="utf-8"?>
然而,在使用 Expat 解析器时,这没有区别。Expat 是不检查有效性的解析器,忽略任何 DTD。
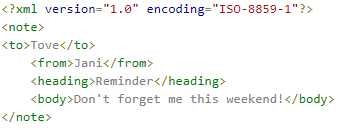
<?xml version="1.0" encoding="ISO-8859-1"?>
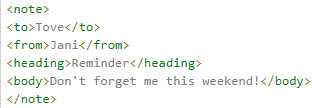
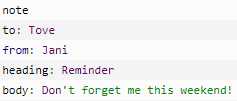
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don‘t forget me this weekend!</body>
</note>
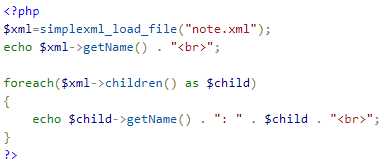
<?php
//初始化 XML 解析器
$parser=xml_parser_create();
//Function to use at the start of an element
function start($parser,$element_name,$element_attrs)
{
switch($element_name)
{
case "NOTE":
echo "-- Note --<br>";
break;
case "TO":
echo "To: ";
break;
case "FROM":
echo "From: ";
break;
case "HEADING":
echo "Heading: ";
break;
case "BODY":
echo "Message: ";
}
}
//Function to use at the end of an element
function stop($parser,$element_name)
{
echo "<br>";
}
//Function to use when finding character data
function char($parser,$data)
{
echo $data;
}
//Specify element handler
xml_set_element_handler($parser,"start","stop");
//Specify data handler
xml_set_character_data_handler($parser,"char");
//Open XML file
$fp=fopen("test.xml","r");
//Read data
while ($data=fread($fp,4096))
{
xml_parse($parser,$data,feof($fp)) or
die (sprintf("XML Error: %s at line %d",
xml_error_string(xml_get_error_code($parser)),
xml_get_current_line_number($parser)));
}
//Free the XML parser
xml_parser_free($parser);
?>
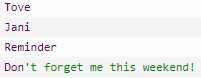
以上代码将输出:
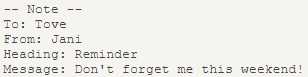
工作原理:


<?xml version="1.0" encoding="ISO-8859-1"?>
<from>Jani</from>
XML DOM 把上面的 XML 视为一个树形结构:


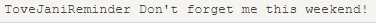

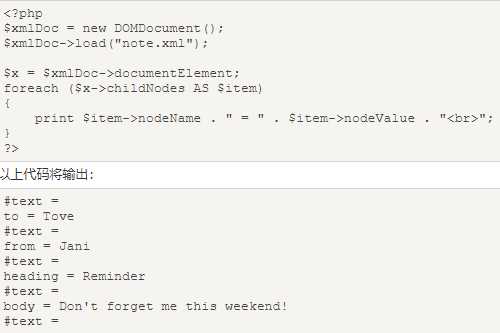
在上面的实例中,可以看到了每个元素之间存在空的文本节点。
当 XML 生成时,它通常会在节点之间包含空白。XML DOM 解析器把它们当作普通的元素,如果不注意它们,有时会产生问题。
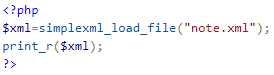


标签:start 之间 通过 document class when 需要 检查 number
原文地址:https://www.cnblogs.com/Rain99-/p/13324378.html