标签:mil 存储 不包含 编程语言 并且 计算 语言 出现 类型
(仅个人学习摘录)
递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
例子,计算阶乘 n! = 1 x 2 x 3 x ... x n,用函数 fact(n) 表示:
fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = fact(n-1) x n
fact(n) 用递归的方式写出来:
def fact(n):
if n==1:
return 1
return n * fact(n-1)
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑性不如递归清晰。
使用递归要防止栈溢出。在计算机中,函数调用是通过栈实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,把循环看成是一种特殊的尾递归函数也是可以的。
尾递归是指,在函数返回的时候,调用自身本身,并且,return 语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现溢出的情况。

可知,return fact_iter(num-1,num*project) 仅返回递归函数本身,num-1 和 num*project 在函数调用前就会被计算,不影响函数调用。
尾递归调用时,如果做了优化,栈就不会增长,但是编程语言对尾递归调用没有进行优化,所以还是会溢出。
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
练习:汉诺塔 recur.py
切片
取一个 list 或 tuple 的部分元素是非常常见的操作。
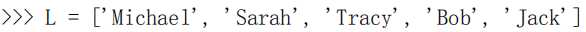
最简单的方法:
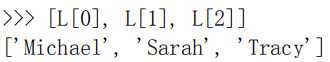
也可以利用循环,但是比较繁琐,Python 提供了切片(slice)操作符,可以简化操作。
取前 3 个元素:

L[0:3] 表示,从索引 0 开始取,知道索引 3 为止,但不包含索引 3。即索引 0、1、2,正好 3 个元素。
如果第一个索引是 0,还可以省略:

也可以不从索引 0 开始:
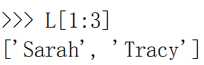
倒数切片:
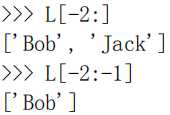
倒数第一个元素的索引是 -1。
只写 [:] 可以复制一个 list。
tuple 也可以进行切片操作,操作结果仍是 tuple:
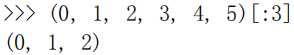
字符串也可以看成是一种 list,也可以进行切片操作,操作结果仍是字符串:
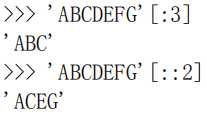
迭代
如果给定一个 list 或 tuple,我们可以通过 for 循环来遍历这个 list 或 tuple,这种遍历称为迭代(Iteration)。
在 Python 中,迭代是通过 for ... in 来完成的,Python 的 for 循环不仅可以用在 list 或 tuple 上,还可以作用在其他可迭代对象上。只要是可迭代对象,无论有无下标,都可以迭代,比如 dict:

因为 dict 的存储不是按照 list 的方式顺序排列,所以,迭代出的结果顺序很可能不一样。默认情况下,dict 迭代的是 key。如果要迭代 value,可以用 for value in d.value(),如果要同时迭代 key 和 value,可以用 for k,v in d.items()。
字符串也是可迭代对象,也可用 for 循环:
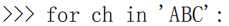
判断对象是否可迭代:
通过 collections 模块的 Iterable 类型判断:

Python 内置的 enumerate 函数可以把一个 list 变成索引—元素对,这样就可以在 for 循环中同时迭代索引和元素本身:

标签:mil 存储 不包含 编程语言 并且 计算 语言 出现 类型
原文地址:https://www.cnblogs.com/dingruijin/p/13340386.html