标签:灵活 灾难恢复 文件 http 成功 EAP 解决方案 incr 表设计
在数据库中存的就是一张张有着千丝万缕关系的表,所以表设计的好坏,将直接影响着整个数据库。而在设计表的时候,我们都会关注一个问题,使用什么存储引擎。等一下,存储引擎?什么是存储引擎?
什么是存储引擎?
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、
锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
例如,如果你在研究大量的临时数据,你也许需要使用内存MySQL存储引擎。内存存储引擎能够在内存中存储所有的表格数据。
又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。 这些不同的技术以及配套的相关功能在 MySQL中被称作存储引擎(也称作表类型 table_type)。 MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。
你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
mysql支持的存储引擎
1 :查询数据库支持的存储引擎
执行: show engines;
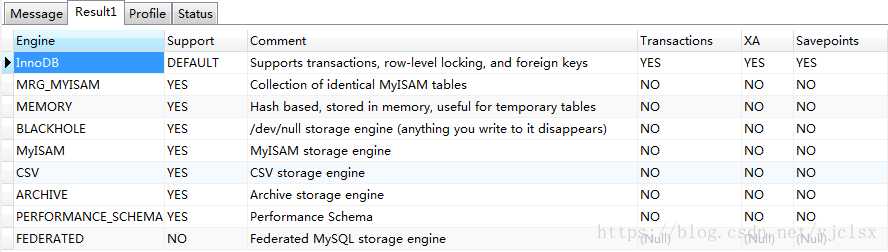
说明
engine:引擎名称。
suppot:是否支持。
comment:说明。
transactions:是够支持事务。
xa:是否支持XA事务。
savepoints:是否支持保存savepoints之间的内容。
一 常用的引擎的介绍(常用的MyISAM和InnoDB)
1:MyISAM (mysql5.5之前默认的存储引擎)
每个MyISAM表在磁盘上存储成3个文件,其中文件名和表名都相同,但是扩展名分别为:
特性:
并发性与锁级别-表解锁
支持全文索引
支持数据压缩 命令:进入到mysql的bin文件夹, .\myisampack.exe -b -f "需要压缩的test.MYI地址" (此命令实在Windows运行)。
运行完以后,会出现一个以OLD结尾的文件,删除OLD可能会出现问题。需要恢复 CHECK table 表名,REPAIR table 表名
有各种空间函数,即使计算空间计算等比较方便
适用场景:
非事务的类型
只读类应用,读取数据的速度快
空间类型(坐标,空间函数)
2 InnoDB 存储引擎 (mysql5.5以后默认的存储引擎)
InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。我的电脑上安装的MySQL 5.6.13版,InnoDB就是作为默认的存储引擎。InnoDB还引入了行级锁定和外键约束,在以下场合下,使用InnoDB是最理想的选择:
1.更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求。
2.事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎。
3.自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
4.外键约束。MySQL支持外键的存储引擎只有InnoDB。
5.支持自动增加列AUTO_INCREMENT属性。
一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。
独立表空间和系统表空间:
独立表空间:innodb_file_per_table on (5.5及以后 默认独立表空间)
每一张表都有自己独立的表空间,表的结构依然在.frm文件中,还有一个后缀为.ibd的文件,保存了这张表的数据和索引。
优点:
每张表都有自己独立的表空间,可实现单表在不同数据库中移动
空间可回收。drop table会自动回收;删除数据后,通过alter table emp engine=innodb也可回收不用的表空间
效率和性能会好一些
缺点:
由于每个表的数据都是以一个单独的文件来存放,所以会受到文件系统的大小限制
系统表空间:innodb_file_per_table off
每一个数据库的所有表的数据、索引都保存在一个文件中,默认在data目录下,名为ibdata1,大小为10M的文件,可以通过参数innodn_data_file_path=/data/ibdata1:2000M来指定存储路径。
表的 .frm文件是放在数据库的文件下的。 .ibdata1是放在data文件夹下的,表示公用的,会产生IO的瓶颈(因为都来读写着一张表)。 系统表空间无法简单的收缩文件大小(删除了数据库数据后,空间无法简单的收缩(变小))
优点:
(1)、可以将表空间分为多个文件放在不同的磁盘上,分布IO,提高性能。innodn_data_file_path=/data/ibdata1:2000M;/db/ibdata2:2000M:autoextend
autoextend表示如果指定的2000M空间用满后,该文件自动增长。
也就是说采用共享空间存储,存储空间的大小不受文件系统下文件大小的限制了,而取决于自身的限制,官方文档显示,表空间的最大限制是64TB。
(2)、表数据和表结构放在一起,方便管理
缺点:
由于所有的数据和索引都是在一个文件中混合存储,这样的话对一个表做了大量的删除操作后,表空间中会产生大量的空隙。而且都是对一个表操作,会产生IO瓶颈
建议使用独立表空间。

3:CSV 存储引擎
数据以文本方式存储,表的字段不能为空,不能有主键。
.frm 表结构, .csv数据的内容, .csm存储表的元数据 。
使用文本编辑器可以直接编辑.csv数据,然后保存,在数据库里面执行flush tables;刷新
注:要在最后一行数据回车一下,要不然最后一条数据不展示。
在excel里面操作提示兼容性问题,无法操作成功,编辑完以后修复一下,可能是excel版本的问题吧。
特点:
1以CSV格式进行数据存储,所有列的字段都不能为null,
2 不支持索引,
3 可以对数据文件在线编辑(在数据库里面执行flush tables;刷新)
4:Archive 存储引擎
以zlib对表数据进行压缩,磁盘I/O更少,数据存储在.ARZ。
.frm , .ARZ数据的内容。
特点:
只支持insert和select操作,只允许在自增ID列上加索引。
使用场景:
日志和数据采集,归档数据等
5 MEMORY 存储引擎
MEMORY存储引擎是用保存在内存中的数据来创建表,每个memory表对应一个磁盘文件。格式是.frm(表结构)
特点:由于他的数据是存放在内存中的,并且默认使用HASH索引(支持hash索引和BTree索引),所以它的访问速度特别快,同时也造成了他的缺点,就是数据库服务一旦关闭,数据就会丢失,另外对表的大小有限制
每个memory表中可存储数据量的大小,受到max_heap_table_size变量的约束,他的初始值是16MB,可以在定义Memary表的时候通过max_rows指定表的最大行数
1数据存在内存
2所有字段都是固定的长度varchar(10)=char(10),
3不支持Blog和Text等字段
4表最大值有max_heap_table_size 决定。
5表级锁
6 支持hash索引和BTree索引
标签:灵活 灾难恢复 文件 http 成功 EAP 解决方案 incr 表设计
原文地址:https://www.cnblogs.com/hup666/p/13369740.html