标签:its walk basic 服务器配置 并发处理 character http char 最大值
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据 ,又或者通过 重新定义 Collections.sorts 的 Comparator 方法 来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
在 Java 中我们称 Stream 为 流 ,我们经常会用流去对集合进行一些流水线的操作。Stream 就像工厂一样,只需要把集合、命令还有一些参数灌输到流水线中去,就可以加工成得出想要的结果。这样的流水线能大大简洁代码,减少操作。
原集合 —> 流 —> 各种操作(过滤、分组、统计) —> 终端操作
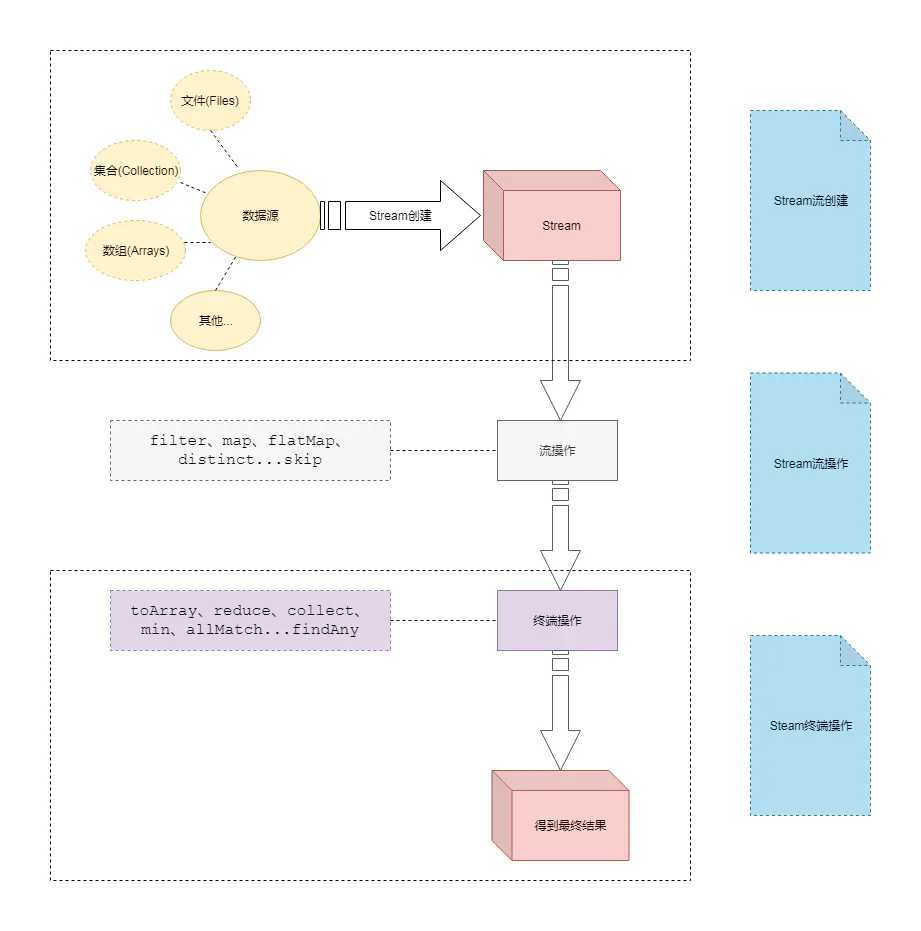
Stream 流的操作流程一般都是这样的,先将集合转为流,然后经过各种操作,比如过滤、筛选、分组、计算。最后的终端操作,就是转化成我们想要的数据,这个数据的形式一般还是集合,有时也会按照需求输出 count 计数。

public class Student { private String name; // 姓名 private String sex; // 性别 private int hight; // 身高 public Student(String name, String age, int hight) { this.name = name; this.sex = age; this.hight = hight; } // Get And Set public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public int getHight() { return hight; } public void setHight(int hight) { this.hight = hight; } @Override public String toString() { return "Student{" + "name=‘" + name + ‘\‘‘ + ", sex=‘" + sex + ‘\‘‘ + ", hight=" + hight + ‘}‘; } }
1) 使用传统的迭代方式来实现
public class Test { public static void main(String[] args) { List<Student> list = new ArrayList(); list.add(new Student("张三", "男", 168)); list.add(new Student("刘翏柳", "女", 168)); list.add(new Student("张丰", "男", 181)); list.add(new Student("李三炮", "男", 178)); list.add(new Student("李狗蛋", "男", 159)); list.add(new Student("张倩倩", "女", 162)); List<Student> newList = new ArrayList<>(); for (Student stu : list) { // 过滤: 姓名长度 >=3 并且 身高 >160 if (stu.getName().length() >= 3 && stu.getHight() > 160) { // 排序 - 矮的排前面 if (newList.size() > 0 && stu.getHight() < newList.get(0).getHight()) newList.add(0, stu); // 队头 else newList.add(stu); // 队尾 } } // 遍历新的集合 输出 for (Student student : newList) { System.out.println(student); } } }
2)Java8 中的 Stream API 进行实现
public class Test { public static void main(String[] args) { List<Student> list = new ArrayList(); list.add(new Student("张三", "男", 168)); list.add(new Student("刘翏柳", "女", 168)); list.add(new Student("张丰", "男", 181)); list.add(new Student("李三炮", "男", 178)); list.add(new Student("李狗蛋", "男", 159)); list.add(new Student("张倩倩", "女", 162)); // lambda表达式、链式编程、函数式接口、Stream流式计算 list.stream() .filter(stu -> stu.getName().length() >= 3) // 姓名长度 >=3 .filter(stu -> stu.getHight() > 160) // 身高 >160 .sorted((stu_1, stu_2) -> Integer.compare(stu_1.getHight(), stu_2.getHight())) // // 排序 - 矮的排前面 .forEach(System.out::println); // 遍历输出 } }
- 输出结果:
Student{name=‘张倩倩‘, sex=‘女‘, hight=162}
Student{name=‘刘翏柳‘, sex=‘女‘, hight=168}
Student{name=‘李三炮‘, sex=‘男‘, hight=178}
想使用 Stream 流,首先咱得先创建一个 Stream 流对象。创建 Steam 需要数据源.这些数据源可以是集合、可以是数组、可以使文件、甚至是你可以去自定义等等。
集合 Collection 作为 Stream 的数据源,应该也是我们用的最多的一种数据源了。Collection 里面也提供了一些方法帮助我们把集合 Collection 转换成 Stream 。
调用 Collection.stream() 函数创建一个 Stream 对象。相当于把集合 Collection 里面的数据都导入到了 Stream 里面去了。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 使用List创建一个流对象 Stream<Integer> stream = list.stream(); // TODO: 对流对象做处理
调用 Collection.parallelStream() 创建 Stream 对象。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 使用List创建一个流对象 Stream<Integer> stream = list.parallelStream(); // TODO: 对流对象做处理
parallelStream() 使用多线程并发处理最后子啊汇总结果,而 stream() 是单线程。所以相对来说 parallelStream() 效率要稍微高点。
数组也可以作为 Stream 的数据源。我们可以通过 Arrays.stream() 方法把一个数组转化成流对象。Arrays.stream() 方法很丰富,有很多个。大家可以根据实际情况使用。
int[] intArray = new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 使用数组创建一个流对象 IntStream stream = Arrays.stream(intArray); // TODO: 对流对象做处理
我们也可以把 BufferedReader 里面 lines 方法把 BufferedReader 里面每一行的数据作为数据源生成一个 Stream 对象。
File file = new File("/home/src/main/resources/application.yml"); try { // 把文件里面的内容一行一行的读出来 BufferedReader in = new BufferedReader(new FileReader(file)); // 生成一个Stream对象 Stream<String> stream = in.lines(); // TODO: 对流对象做处理 } catch (IOException e) { e.printStackTrace(); }
Files 里面多个生成 Stream 对象的方法,都是对 Path(文件) 的操作。
有的是指定 Path 目录下所有的子文件(所有的子文件相当于是一个列表了)作为 Stream 数据源,有的把指定 Path 文件里面的每一行数据作为 Stream 的数据源。
列出指定 Path 下面的所有文件。把这些文件作为 Stream 数据源。
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有的文件
Stream<Path> stream = Files.list(path);
// TODO: 对流对象做处理
} catch (IOException e) {
e.printStackTrace();
}
Files.walk() 方法用于遍历子文件(包括文件夹)。参数 maxDepth 用于指定遍历的深度。把子文件(子文件夹)作为 Stream 数据源。
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 第二个参数用于指定遍历几层
Stream<Path> stream = Files.walk(path, 2);
// TODO: 对流对象做处理
} catch (IOException e) {
e.printStackTrace();
}
Files.find 方法用于遍历查找(过滤)子文件。参数里面会指定查询(过滤)条件。把过滤出来的子文件作为 Stream 的数据源。
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有不是目录的文件
Stream<Path> stream = Files.find(path, 2, (path1, basicFileAttributes) -> {
// 过滤掉目录文件
return !basicFileAttributes.isDirectory();
});
// TODO: 对流对象做处理
} catch (IOException e) {
e.printStackTrace();
}
Files.lines 方法是把指定 Path 文件里面的每一行内容作为 Stream 的数据源。
Path path = Paths.get("D:\\home\\src\\main\\resources");
try {
// 找到指定path下的所有不是目录的文件
Stream<Path> stream = Files.find(path, 2, (path1, basicFileAttributes) -> {
// 过滤掉目录文件
return !basicFileAttributes.isDirectory();
});
// TODO: 对流对象做处理
} catch (IOException e) {
e.printStackTrace();
}
我们也可以自己去创建 Stream 自己提供数据源。Stream 类里面提供 of()、iterate()、generate()、builder() 等一些方法来创建 Stream,Stream 的数据源我们自己提供。
Stream.of() 函数参数就是数据源。
Stream<Integer> ofSteam = Stream.of(1,2,3,4,5,6);
Stream.iterate() 可以用来生成无限流,函数需要两个参数:第一个参数是初始值、第二个参数用于确定怎么根据前一个元素的值生成下一个元素。
// Stream.iterate() 流式迭代器 Stream<BigInteger> integers = Stream.iterate( BigInteger.ONE, // 初始值 bigInteger -> bigInteger.add(BigInteger.ONE) // 用于确定怎么根据前一个元素的值生成下一个元素 ); // 简单输出 integers.limit(10).forEach(System.out::println);
Stream.generate() 也是用于生成一个无限流。参数用于获取每个元素。
// Stream.generate() 生成无限流 Stream<Double> generateA = Stream.generate(() -> { return java.lang.Math.random() * 100; }); // 简单输出前10个值 generateA.limit(10).forEach(randomInt -> System.out.println(randomInt));
Stream.build() 通过建造者模式生成一个 Stream 建造器。然后把需要加入 Stream 里面的数据源一个一个通过建造器添加进去。
// Stream.builder() 构造一个 Stream 对象 Stream.Builder<Integer> build = Stream.<Integer>builder() .add(1) .add(2) .add(3); build.accept(4); build.accept(5); // 遍历输出 build.build().forEach(integer -> System.out.println(integer)); // TODO: 对流对象做处理
Stream 其他创建方式我们就不一一举例了。有如下方式。
Stream 流操作就是对 Stream 流的各种处理。Stream 里面已经给提供了很多中间操作(我们一般称之为操作符)。
Stream 提供的流操作符。
| Stream流操作符 | 解释 |
|---|---|
| filter | 对流里面的数据做过滤操作 |
| map | 对流里面每个元素做转换 |
| mapToInt | 把流里面的每个元素转换成int |
| mapToLong | 流里面每个元素转换成long |
| mapToDouble | 流里面每个元素转换成double |
| flatMap | 流里面每个元素转换成Steam对象,最后平铺成一个Stream对象 |
| flatMapToInt | 流里面每个元素转换成IntStream对象,最后平铺成一个IntStream对象 |
| flatMapToLong | 流里面每个元素转换成LongStream对象,最后平铺成一个LongStream对象 |
| flatMapToDouble | 流里面每个元素转换成DoubleStream对象,最后平铺成一个DoubleStream对象 |
| distinct | 去重 |
| sorted | 对流里面的元素排序 |
| peek | 查看流里面的每个元素 |
| limit | 返回前n个数 |
| skip | 跳过前n个元素 |
Stream 提供了这么多的操作符,而且这些操作符是可以组合起来使用。
Stream 流终端操作是流式处理的最后一步,之前已经对 Stream 做了一系列的处理之后。该拿出结果了。我们可以在终端操作中实现对流的遍历、查找、归约、收集等等一系列的操作。
Stream 流终端操作提供的函数有。
| 终端操作符 | 解释 |
|---|---|
| forEach | 遍历 |
| forEachOrdered | 如果流里面的元素是有顺序的则按顺序遍历 |
| toArray | 转换成数组 |
| reduce | 归约 - 根据一定的规则将Stream中的元素进行计算后返回一个唯一的值 |
| collect | 收集 - 对处理结果的封装 |
| min | 最小值 |
| max | 最大值 |
| count | 元素的个数 |
| anyMatch | 任何一个匹配到了就返回true |
| allMatch | 所有都匹配上了就返回true |
| noneMatch | 没有一个匹配上就返回true |
| findFirst | 返回满足条件的第一个元素 |
| findAny | 返回某个元素 |
关于 Stream 终端操作部分,我们就着重讲下 collect() 函数的使用。因为其他的终端操作符都很好理解。collect() 稍稍复杂一点。
collect() 的使用主要在于对参数的理解,所有我们这里要专门讲下 collect() 函数的参数 Collector 这个类,以及怎么去构建 Collector 对象。只有在了解了这些之后,咱们才可以熟练的把他们用在各种场景中。
Collector 类目前没别的用处,就是专门用来作为 Stream 的 collect() 方法的参数的。把 Stream 里面的数据转换成我们最终想要的结果上。
Collector 各个方法,以及每个泛型的介绍:
/** * Collector是专门用来作为Stream的collect方法的参数的 * * 泛型含义 * T:是流中要收集的对象的泛型 * A:是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。 * R:是收集操作得到的对象(通常但不一定是集合)的类型。 */ public interface Collector<T, A, R> { /** * 生成结果容器,容器类型为A * (多线程的情况下可能会调用多次,开多个线程同时去处理一个流,每个线程调用一次) */ Supplier<A> supplier(); /** * A对应supplier()函数创建的结果容器 * T对应Stream流里面一个一个的元素 * 用于消费元素,也就是归纳元素,一般在这个里面把流里面的元素T(也可以转换下)放到supplier()创建的结果T里面去 */ BiConsumer<A, T> accumulator(); /** * 用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果A * 多线程的情况下,多个线程并行执行。每个线程产生一个结果 */ BinaryOperator<A> combiner(); /** * 用于将之前整合完的结果A转换成为R * * combiner()完成之后了A, 这里还可以在转一道。生成你自己想要的结果 */ Function<A, R> finisher(); /** * characteristics表示当前Collector的特征值, * 这是个不可变Set * 它定义了收集器的行为--尤其是关于流是否可以多线程并行执行,以及可以使用哪些优化的提示 */ Set<Characteristics> characteristics(); /** * 它定义了收集器的行为--尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示 */ enum Characteristics { /** * accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED, * 那它仅在用于无序数据源时才可以并行归约 * 多线程并行 */ CONCURRENT, /** * 归约结果不受流中项目的遍历和累积顺序的影响(无序) */ UNORDERED, /** * 无需转换结果 */ IDENTITY_FINISH } /** * 四参方法,用于生成一个Collector,T代表流中的一个一个元素,R代表最终的结果 */ public static<T, R> Collector<T, R, R> of(Supplier<R> supplier, BiConsumer<R, T> accumulator, BinaryOperator<R> combiner, Characteristics... characteristics); /** * 五参方法,用于生成一个Collector,T代表流中的一个一个元素,A代表中间结果,R代表最终结果,finisher用于将A转换为R */ public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier, BiConsumer<A, T> accumulator, BinaryOperator<A> combiner, Function<A, R> finisher, Characteristics... characteristics); }
有了上面的介绍,接下来我们自己来 new 一个 Collector 对象,把我们 Steam 流里面的数据转换成 List 。(当然了Collectors类里面有提供这个方法,这里我们自己写一个也是为了方便大家的理解)
// 自己来组装Collector,返回一个List @Test public void collectNew() { Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List<Integer> intList = stream.collect( new Collector<Integer, List<Integer>, List<Integer>>() { // 生成结果容器,容器类型为,我们这里为List<Integer> @Override public Supplier<List<Integer>> supplier() { return new Supplier<List<Integer>>() { @Override public List<Integer> get() { return new ArrayList<>(); } }; } // 把流里面的结果都放到结果容器里面去 @Override public BiConsumer<List<Integer>, Integer> accumulator() { return new BiConsumer<List<Integer>, Integer>() { @Override public void accept(List<Integer> integers, Integer integer) { integers.add(integer); } }; } // 两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果A @Override public BinaryOperator<List<Integer>> combiner() { return new BinaryOperator<List<Integer>>() { @Override public List<Integer> apply(List<Integer> left, List<Integer> right) { left.addAll(right); return left; } }; } // 可以对最终的结果做一个转换操作 @Override public Function<List<Integer>, List<Integer>> finisher() { return new Function<List<Integer>, List<Integer>>() { @Override public List<Integer> apply(List<Integer> integers) { return integers; } }; } // 特征值 @Override public Set<Characteristics> characteristics() { return EnumSet.of(Collector.Characteristics.UNORDERED, Collector.Characteristics.IDENTITY_FINISH); } }); for (Integer item : intList) { System.out.println(item); } }
我们将对常规的迭代、Stream 串行迭代以及 Stream 并行迭代进行性能测试对比,迭代循环中,我们将对数据进行过滤、分组等操作。分别进行以下几组测试:
| 测试 | 结论(迭代使用时间) |
| 多核 CPU 服务器配置环境下,对比长度 100 的 int 数组的性能; | 常规的迭代 < Stream 并行迭代 < Stream 串行迭代 |
| 多核 CPU 服务器配置环境下,对比长度 1.00E+8 的 int 数组的性能; | Stream 并行迭代 < 常规的迭代 < Stream 串行迭代 |
| 多核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能; | Stream 并行迭代 < 常规的迭代 < Stream 串行迭代 |
| 单核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能; | 常规的迭代 < Stream 串行迭代 < Stream 并行迭代 |
结论:
在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
在串行处理操作中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8 中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在并行处理操作中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,ForkJoin 框架将每个切片的处理结果 Join 合并起来。最后就是要注意 Stream 的使用场景。
标签:its walk basic 服务器配置 并发处理 character http char 最大值
原文地址:https://www.cnblogs.com/Dm920/p/13365719.html
