标签:nsf translate lse check read types fail ddl case
月初的时候,Flink 终于发布 1.11.0 版本, CDC 的功能还是比较期待的(虽然比预期差很多)
当然是升级一波了
最新的代码已经上传到 GitHub : https://github.com/springMoon/sqlSubmit
跑 sqlSubmit 的代码,随便来个 kafka to kafka 的sql
在执行这句的时候:
env.execute(Common.jobName)
报了这个错:
Exception in thread "main" java.lang.IllegalStateException: No operators defined in streaming topology. Cannot execute. at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraphGenerator(StreamExecutionEnvironment.java:1872) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:1863) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:1848) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1699) at org.apache.flink.streaming.api.scala.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.scala:699) at com.rookie.submit.main.SqlSubmitBak$.main(SqlSubmitBak.scala:68) at com.rookie.submit.main.SqlSubmitBak.main(SqlSubmitBak.scala)
报错了,但是任务还是跑起来了,这个 任务名是什么鬼,WTF?
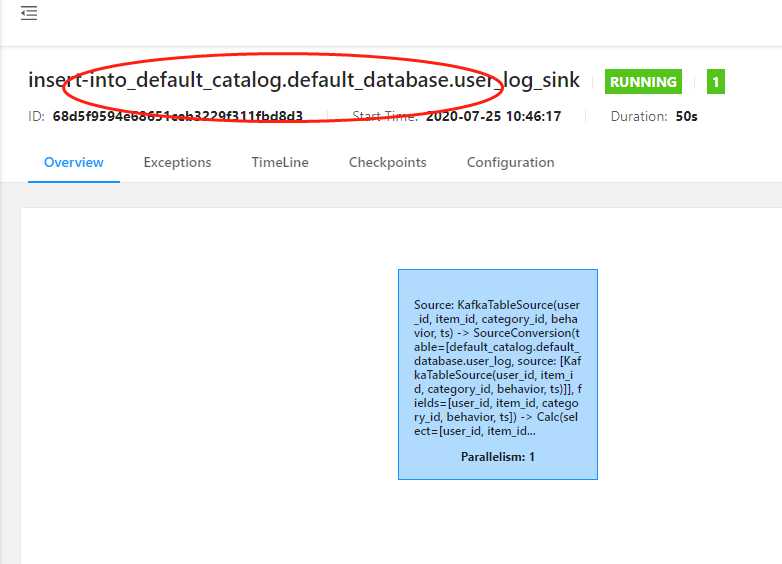
这种时候,当然是 debug 下代码,到底怎么了
debug tabEnv.executeSql(sql) ,执行到:
org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql() 方法:

parser.parse(statement) 就是解析sql 成 算子了,这个我不懂,就跳过了
直接看下面一句,执行
executeOperation(operations.get(0))
调到方法,代码比较长就不贴了,各位同学请自行查看源码:
private TableResult executeOperation(Operation operation)
这是根据算子的操作类型,选择对于的语句执行, insert 语句属于 ModifyOperation 所以执行最前面的一个分支

进去,找到这个方法:
@Override public TableResult executeInternal(List<ModifyOperation> operations) { List<Transformation<?>> transformations = translate(operations); List<String> sinkIdentifierNames = extractSinkIdentifierNames(operations); String jobName = "insert-into_" + String.join(",", sinkIdentifierNames); Pipeline pipeline = execEnv.createPipeline(transformations, tableConfig, jobName); try { JobClient jobClient = execEnv.executeAsync(pipeline); TableSchema.Builder builder = TableSchema.builder(); Object[] affectedRowCounts = new Long[operations.size()]; for (int i = 0; i < operations.size(); ++i) { // use sink identifier name as field name builder.field(sinkIdentifierNames.get(i), DataTypes.BIGINT()); affectedRowCounts[i] = -1L; } return TableResultImpl.builder() .jobClient(jobClient) .resultKind(ResultKind.SUCCESS_WITH_CONTENT) .tableSchema(builder.build()) .data(Collections.singletonList(Row.of(affectedRowCounts))) .build(); } catch (Exception e) { throw new TableException("Failed to execute sql", e); } }
可以看到,在执行到这里的时候,直接指定了jobName ,提交任务了,吐血
String jobName = "insert-into_" + String.join(",", sinkIdentifierNames);
经过大佬指点后,去 JIRA 提了个bug:https://issues.apache.org/jira/browse/FLINK-18545
那个时候,刚好在说快速发布FLink 1.11.1 修复一些比较严重的bug ,本来以为可以赶上这趟车的,没想到讨论了比较长时间,赶不上了。
讨论中,有个大佬提到 executeSql 可以执行很多种类的sql 比如 DDL,DML,如果是给一个 DDL 语句指定jobName 比较奇怪,所以建议我用 org.apache.flink.table.api.StatementSet,并在 StatementSet 中添加可以指定 jobName 的 execute 方法。
/** * add insert statement to the set. */ StatementSet addInsertSql(String statement); /** * execute all statements and Tables as a batch. * * <p>The added statements and Tables will be cleared when executing this method. */ TableResult execute();
这个方法我是可以接受的,所以就直接改了。
改动设计如下几个类:
接口:org.apache.flink.table.api.StatementSet
实现类:org.apache.flink.table.api.internal.StatementSetImpl
接口:org.apache.flink.table.api.internal.TableEnvironmentInternal
实现类:org.apache.flink.table.api.internal.TableEnvironmentImpl
就是复制之前的代码,给 execute 加个 参数
接口:org.apache.flink.table.api.StatementSet
/** * execute all statements and Tables as a batch. * * <p>The added statements and Tables will be cleared when executing this method. */ TableResult execute(); /** * execute all statements and Tables as a batch. * * <p>The added statements and Tables will be cleared when executing this method. */ TableResult execute(String jobName);
实现类:org.apache.flink.table.api.internal.StatementSetImpl
@Override public TableResult execute() { try { return tableEnvironment.executeInternal(operations); } finally { operations.clear(); } } @Override public TableResult execute(String jobName) { Preconditions.checkNotNull(jobName, "Streaming Job name should not be null."); try { return tableEnvironment.executeInternal(operations, jobName); } finally { operations.clear(); } }
接口:org.apache.flink.table.api.internal.TableEnvironmentInternal
/** * Execute the given modify operations and return the execution result. * * @param operations The operations to be executed. * @return the affected row counts (-1 means unknown). */ TableResult executeInternal(List<ModifyOperation> operations); /** * Execute the given modify operations and return the execution result. * * @param operations The operations to be executed. * @param jobName The jobName * @return the affected row counts (-1 means unknown). */ TableResult executeInternal(List<ModifyOperation> operations, String jobName);
实现类:org.apache.flink.table.api.internal.TableEnvironmentImpl
执行的实现中,将传入的参数,替换默认的jobName
@Override public TableResult executeInternal(List<ModifyOperation> operations) { return executeInternal(operations, null); } @Override public TableResult executeInternal(List<ModifyOperation> operations, String jobName) { List<Transformation<?>> transformations = translate(operations); List<String> sinkIdentifierNames = extractSinkIdentifierNames(operations); if (jobName == null) { jobName = "insert-into_" + String.join(",", sinkIdentifierNames); } Pipeline pipeline = execEnv.createPipeline(transformations, tableConfig, jobName); try { JobClient jobClient = execEnv.executeAsync(pipeline); TableSchema.Builder builder = TableSchema.builder(); Object[] affectedRowCounts = new Long[operations.size()]; for (int i = 0; i < operations.size(); ++i) { // use sink identifier name as field name builder.field(sinkIdentifierNames.get(i), DataTypes.BIGINT()); affectedRowCounts[i] = -1L; } return TableResultImpl.builder() .jobClient(jobClient) .resultKind(ResultKind.SUCCESS_WITH_CONTENT) .tableSchema(builder.build()) .data(Collections.singletonList(Row.of(affectedRowCounts))) .build(); } catch (Exception e) { throw new TableException("Failed to execute sql", e); } }
代码就改完了,执行个sql 看下
由于使用 StatementSet 的方式,提交,要把insert 的语句单独提出来,所以提交sql 的代码也处理了下:
// execute sql val statement = tabEnv.createStatementSet() var result: StatementSet = null for (sql <- sqlList) { try { if (sql.startsWith("insert")) { // ss result = statement.addInsertSql(sql) } else tabEnv.executeSql(sql) logger.info("execute success : " + sql) } catch { case e: Exception => logger.error("execute sql error : " + sql, e) e.printStackTrace() System.exit(-1) } }
// 执行insert result.execute(Common.jobName)
跑个任务看下:
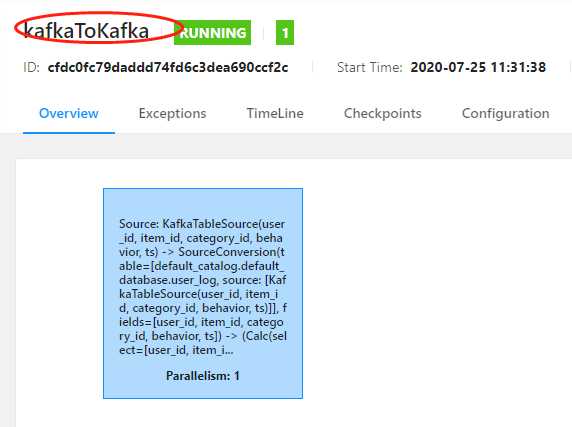
jobName 已经是指定的了。
上面把本地的代码改完了,但是还没修改flink 的 jar ,之前编译过Flink 1.11.0 的源码,还挺快的,改了这个代码,发现编译不了了,卡在 flink-runtion-web 这里,执行 npm install 的时候执行不动了
<executions>
<execution>
<id>install node and npm</id>
<goals>
<goal>install-node-and-npm</goal>
</goals>
<configuration>
<nodeVersion>v10.9.0</nodeVersion>
</configuration>
</execution>
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>ci --cache-max=0 --no-save</arguments>
<environmentVariables>
<HUSKY_SKIP_INSTALL>true</HUSKY_SKIP_INSTALL>
</environmentVariables>
</configuration>
</execution>
<execution>
<id>npm run build</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>run build</arguments>
</configuration>
</execution>
</executions>
所以,就直接把 jar 拉下来,用 压缩软件打开,直接把对于的class 文件换了。
本地需要修改 maven 仓库的 flink-table-api-java-1.11.0.jar 这个jar包
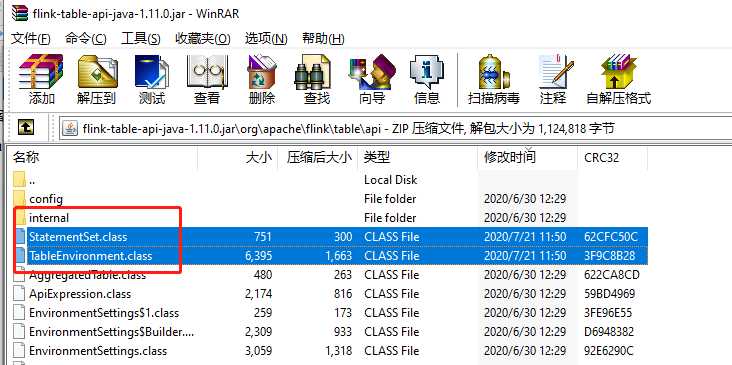
部署的flink 由于 flink-table 的代码都打包到 flink-table_2.11-1.11.0.jar 中,所以需要替换这个包的对于class,就可以了。
社区的大佬有一篇博客,写了另一种更优雅的解决版本: https://www.jianshu.com/p/5981646cb1d4
搞定
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文

解决 Flink 1.11.0 sql 不能指定 jobName 的问题
标签:nsf translate lse check read types fail ddl case
原文地址:https://www.cnblogs.com/Springmoon-venn/p/13375972.html