标签:使用 shu mic tab oracle hdf 刷新 数据 default
jdk安装前往官网,这里我安装jdk-8u261
解压
sudo mkdir -p /opt/moudle
sudo tar -zxvf jdk-8u261-linux-x64.tar.gz -C /opt/moudle/
设置环境变量
export JAVA_HOME=/opt/moudle/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
刷新配置
source /etc/profile
检查java
java -version
# 出现下面安装成功
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
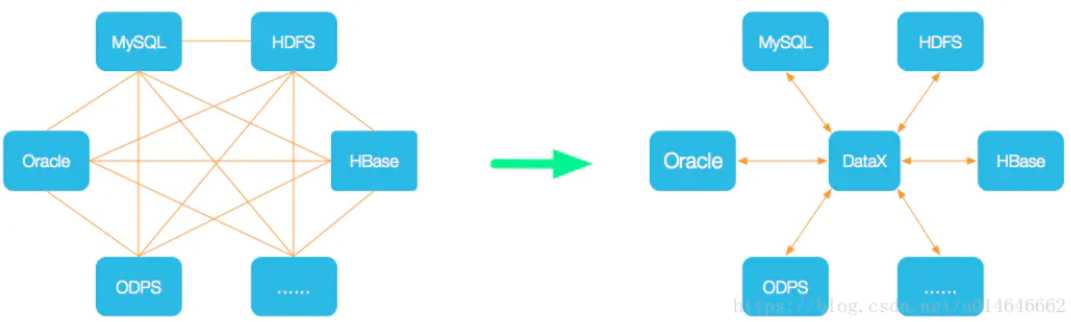
DataX是阿里巴巴的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
!
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
解压
tar -zxvf datax.tar.gz -C /opt/software/
运行自检脚本
cd /opt/software/datax/
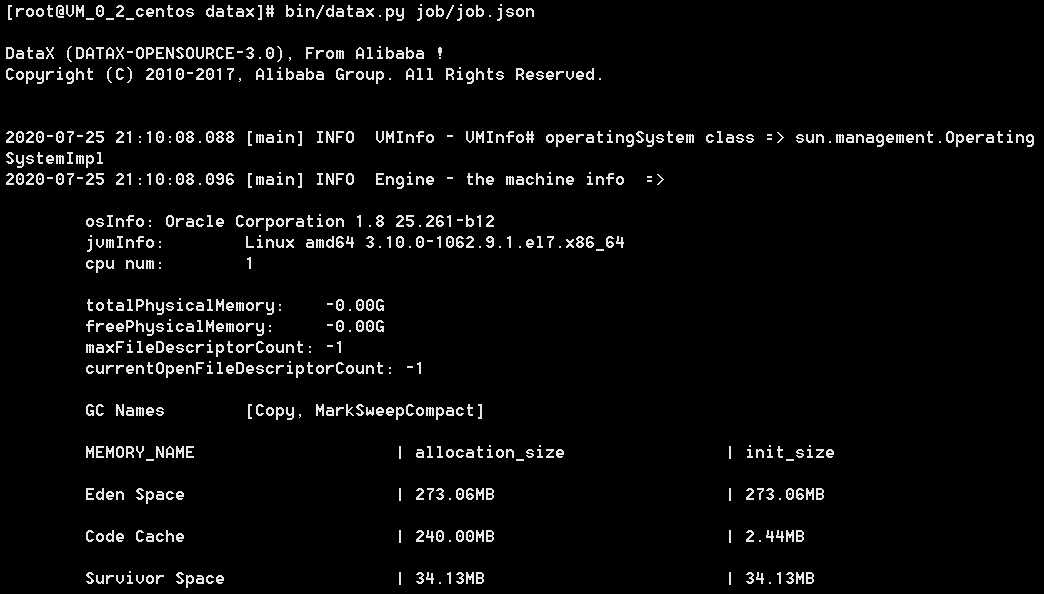
bin/datax.py job/job.json
出现下面界面表示成功:
/opt/software/datax/job/job.json格式。{
"content":[
{
"reader":{
"name":"streamreader",# 流式读,根据DataX定义好的设置
"parameter":{
"column":[#把column里所有value读到流当中
{
"type":"string",
"value":"DataX"
},
{
"type":"long",
"value":19890604
},
{
"type":"date",
"value":"1989-06-04 00:00:00"
},
{
"type":"bool",
"value":true
},
{
"type":"bytes",
"value":"test"
}
],
"sliceRecordCount":100000
}
},
"writer":{
"name":"streamwriter",# 流式写,根据DataX定义好的设置
"parameter":{
"encoding":"UTF-8",
"print":false#打印
}
}
}
],
"setting":{
"errorLimit":{# errorLimit错误限制
"percentage":0.02,# 最大容忍错误限制百分比2%
"record":0# 容忍错误记录调试 0
},
"speed":{# 控制并发数:通过byte或channel控制,这里默认通过byte控制
"byte":10485760#以 sliceRecordCount乘以byte,打印数据条数占用空间
}
}
}
首先查看官方json配置模版
# 查看 streamreader --> streamwriter 模版
python /opt/software/datax/bin/datax.py -r streamreader -w streamwriter
# 模版如下:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
根据模版编写json文件
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
"type":"string",
"value":"xujunkai, hello world!"
},
{
"type":"string",
"value":"徐俊凯, 你好!"
},
],
"sliceRecordCount": "10"#打印次数
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", #编码方式utf-8
"print": true
}
}
}
],
"setting": {
"speed": {#控制并发数
"channel": "2"#控制并发2次-->这里因为是打印所以会sliceRecordCount乘以channel 打印20遍。如果设置为mysql真的会进行并发
}
}
}
}
创建一个json文件,在根目录
mkdir json
cd json/
vim stream2stream.json
# 将上述内容粘贴进去
运行job
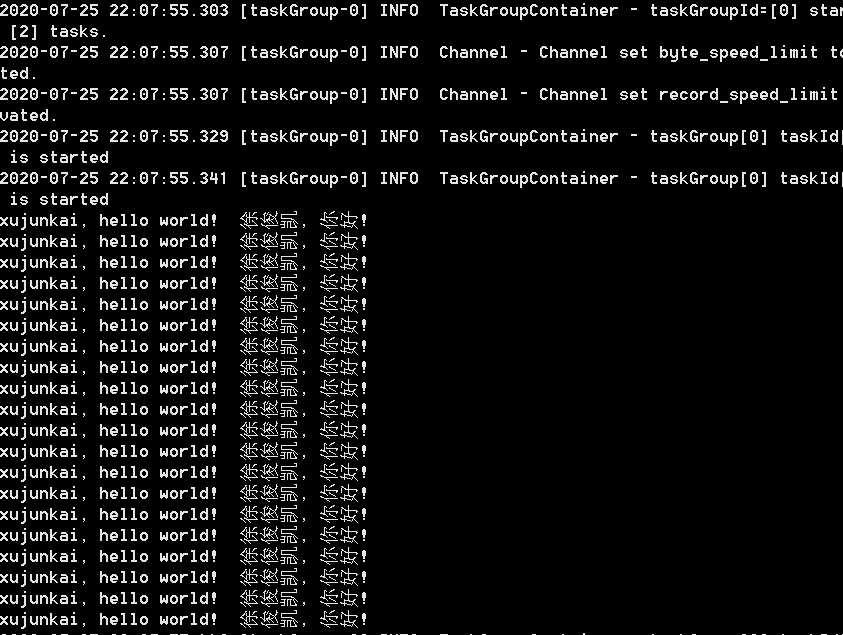
/opt/software/datax/bin/datax.py ./stream2stream.json
如下图:
写入和读取方准备创建库和表
# 创建库
create database `testdatax` character set utf8
# 创建表
create table user1w(
id int not null auto_increment,
name varchar(10) not null,
score int not null,
primary key(`id`))engine=InnoDB default charset=utf8;
编写一个简单存储过程,读取数据端插入数据:
DELIMITER //
create PROCEDURE add_user(in num INT)
BEGIN
DECLARE rowid INT DEFAULT 0;
DECLARE name CHAR(1);
DECLARE score INT;
WHILE rowid < num DO
SET rowid = rowid + 1;
set name = SUBSTRING(‘abcdefghijklmnopqrstuvwxyz‘,ROUND(1+25*RAND()),1);
set score= FLOOR(40 + (RAND()*60));
insert INTO user1w (name,score) VALUES (name,score);
END WHILE;
END //
DELIMITER ;
执行插入数据
call add_user(10000);
python /opt/software/datax/bin/datax.py -r mysqlreader -w mysqlwriter,json文件配置:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", # 读取端,根据DataX定义好的设置
"parameter": {
"column": [], # 读取端需要同步的列
"splitPk": "",# 数据抽取时指定字段进行数据分片
"connection": [
{
"jdbcUrl": [], #读取端连接信息
"table": []# 读取端指定的表
}
],
"password": "", #读取端账户
"username": "", #读取端密码
"where": ""# 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", #写入端,根据DataX定义好的设置
"parameter": {
"column": [], #写入端需要同步的列
"connection": [
{
"jdbcUrl": "", # 写入端连接信息
"table": []# 写入端指定的表
}
],
"password": "", #写入端密码
"preSql": [], # 执行写入之前做的事情
"session": [],
"username": "", #写入端账户
"writeMode": ""# 操作乐星
}
}
}
],
"setting": {
"speed": {
"channel": ""#指定channel数
}
}
}
}
我的配置json:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123"
"column": ["*"],
"splitPk": "id",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://读取端IP:3306/testdatax?useUnicode=true&characterEncoding=utf8"
],
"table": ["user1w"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://写入端IP:3306/testdatax?useUnicode=true&characterEncoding=utf8",
"table": ["user1w"]
}
],
"password": "123",
"preSql": [
"truncate user1w"
],
"session": [
"set session sql_mode=‘ANSI‘"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
cd到datax下bin目录执行:
python2 datax.py /root/json/mysql2mysql.json
会打印同步数据信息完毕。更多配置见github-dataX
python /opt/software/datax/bin/datax.py -r mysqlreader -w mysqlwriter
标签:使用 shu mic tab oracle hdf 刷新 数据 default
原文地址:https://www.cnblogs.com/xujunkai/p/13378942.html