标签:其他 完成 需要 很多 遍历 数据读取 通过 好的 避免
1.MySQL会为每个线程分配一个内存(sort_buffer)用于排序该内存大小为sort_buffer_size
1>如果排序的数据量小于sort_buffer_size,排序将会在内存中完成
2>如果排序数据量很大,内存中无法存下这么多数据,则会使用磁盘临时文件来辅助排序,也称外部排序
3>在使用外部排序时,MySQL会分成好几份单独的临时文件用来存放排序后的数据,然后在将这些文件合并成一个大文件
2.mysql会通过遍历索引将满足条件的数据读取到sort_buffer,并且按照排序字段进行快速排序
1>如果查询的字段不包含在辅助索引中,需要按照辅助索引记录的主键返回聚集索引取出所需字段
2>该方式会造成随机IO,在MySQL5.6提供了MRR的机制,会将辅助索引匹配记录的主键取出来在内存中进行排序,然后在回表
3>按照情况建立联合索引来避免排序所带来的性能损耗,允许的情况下也可以建立覆盖索引来避免回表
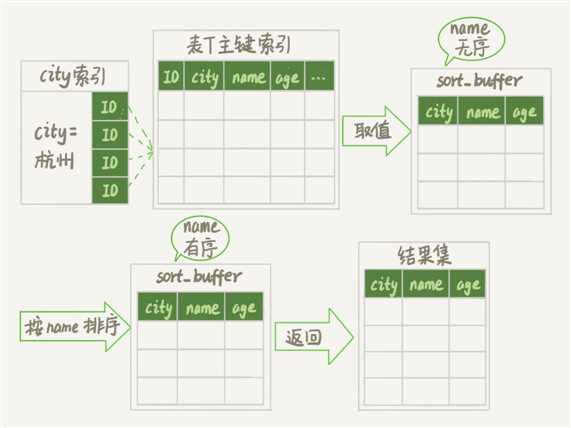
全字段排序
1.通过索引将所需的字段全部读取到sort_buffer中
2.按照排序字段进行排序
3.将结果集返回给客户端
缺点:
1.造成sort_buffer中存放不下很多数据,因为除了排序字段还存放其他字段,对sort_buffer的利用效率不高
2.当所需排序数据量很大时,会有很多的临时文件,排序性能也会很差
优点:MySQL认为内存足够大时会优先选择全字段排序,因为这种方式比rowid 排序避免了一次回表操作
rowid排序
1.通过控制排序的行数据的长度来让sort_buffer中尽可能多的存放数据,max_length_for_sort_data
2.只将需要排序的字段和主键读取到sort_buffer中,并按照排序字段进行排序
3.按照排序后的顺序,取id进行回表取出想要获取的数据
4.将结果集返回给客户端
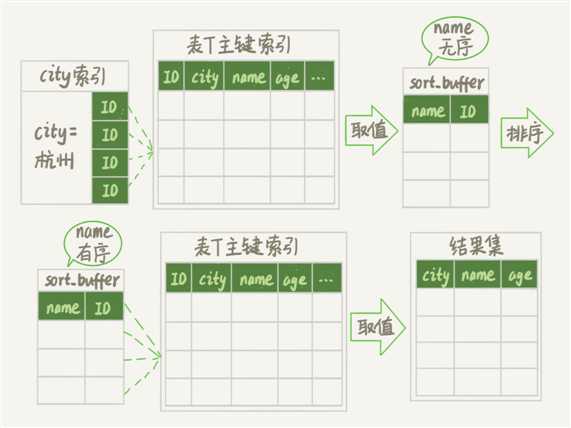
优点:更好的利用内存的sort_buffer进行排序操作,尽量减少对磁盘的访问
缺点:回表的操作是随机IO,会造成大量的随机读,不一定就比全字段排序减少对磁盘的访问
3.按照排序的结果返回客户所取行数
标签:其他 完成 需要 很多 遍历 数据读取 通过 好的 避免
原文地址:https://www.cnblogs.com/wsw-seu/p/13396113.html