标签:间隔 pac ini tput erro 自动 变化 stress 存在
性能分析小案例系列,可以通过下面链接查看哦
https://www.cnblogs.com/poloyy/category/1814570.html
系统架构背景
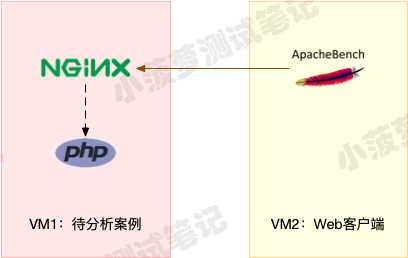
- VM1:用作 Web 服务器,来模拟性能问题
- VM2:用作 Web 服务器的客户端,来给 Web 服务增加压力请求
- 使用两台虚拟机(均是 Ubuntu 18.04)是为了相互隔离,避免交叉感染
VM2 运行 ab 命令,初步观察 Nginx 性能
简单介绍 ab 命令
- ab(apache bench)是一个常用的 HTTP 服务性能测试工具
- 可以向目标服务器并发发送请求
运行 ab 命令
并发 100 个请求测试 VM1 的 Nginx 性能,总共测试 1000 个请求
ab -c 100 -n 1000 http://172.20.72.58:10000/
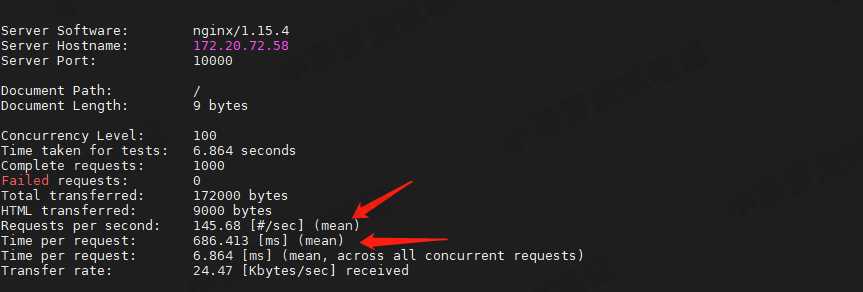
从 ab 的输出结果可以看到,Nginx 能承受的每秒平均请求数只有 145.68(有点差强人意)
那到底是哪里出了问题呢
接下来,我们将通过一系列的命令来观察哪里出问题了
通过命令分析 VM1 的性能问题
VM2 长时间运行 ab 命令
并发 5 个请求,持续并发请求 10min
ab -c 5 -t 600 http://172.20.72.58:10000/
接下来的命令都在 VM1 上执行
top 查看系统 CPU 使用率、进程 CPU 使用率、平均负载
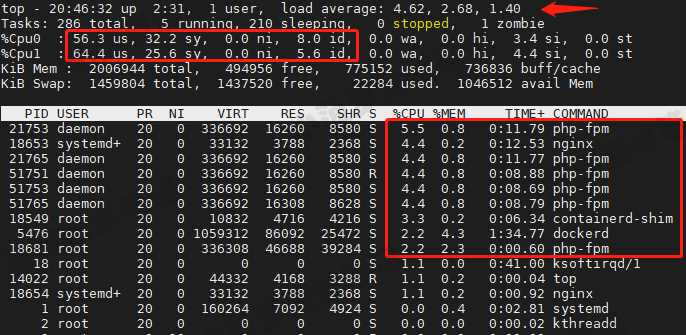
结果分析
- 平均负载已远超 CPU数量(2)
- Nginx、docker、php 相关的进程总的 CPU 使用率大概 40%左右
- 但是系统 CPU 使用率(us+sy)已达到 96%了,空闲 CPU(id)只剩下 3.7%
提出疑问
为什么进程所占用的 CPU 使用率并不高,但是系统 CPU 使用率和平均负载会这么高?
回答疑问,分析进程列表
- containerd-shim:运行容器的,3.3% 的 CPU 使用率挺正常
- Nginx 和 php-fpm:运行 Web 服务的,占用的 CPU 使用率也才 5-6%
- 再往后就没有什么占用 CPU 使用率的进程了
嘶,发现 top 并没有满足我们的需求,看来得祭出另一个命令了
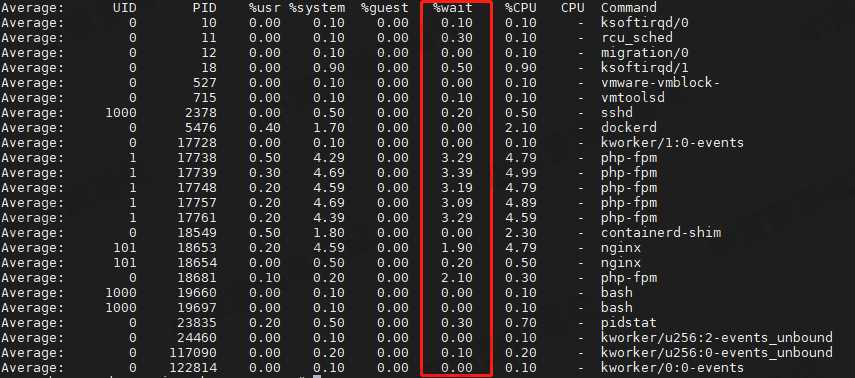
pidstat 查看是否有异常进程的 CPU 使用率过高
每秒取一次结果,共取 10 次
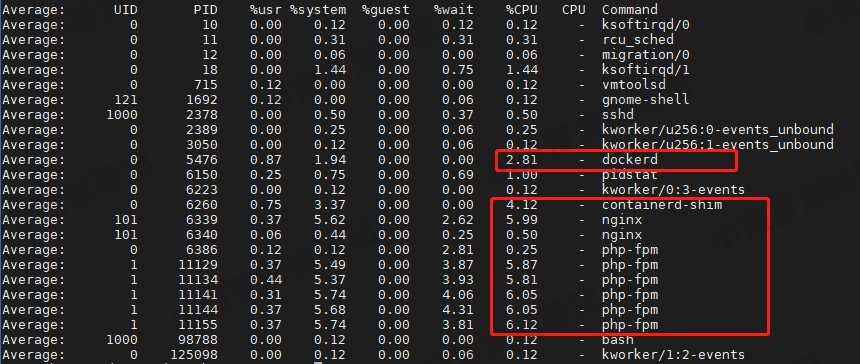
结果分析
跟 top 命令的结果差不多,Nginx、dockerd、php-fpm 的 CPU 使用率偏高,但是加起来并没有用户态 CPU 使用率这么高
问题来了
用户 CPU 使用率已经达到 55%,但却找不到时哪个进程有问题,这到底是咋肥事?难道是命令太辣鸡了吗?
答案
命令的存在肯定是有它的意义,问题肯定是出在我们自己身上,是否遗漏了什么关键信息?
再次运行 top 命令

结果分析
发现了一个关键点,就绪队列有 6 个进程处于 R 状态
6 个正常吗?
- 回想一下 ab 测试的参数,并发请求数是 5
- 再看进程列表里, php-fpm 的数量也是 6, 再加上 Nginx
- 好像同时有 6 个进程也并不奇怪
仔细瞧一瞧
php-fpm、Nginx、docker 这么多个进程只有 1 个 php-fpm 进程是 R 状态的,其他都处于 S(Sleep)状态,这就奇怪了
找到真正处于 R 状态的进程
调整 top 列表排序规则
在 top 列表中,按 shift + f,进入 top 列表的显示规则页面
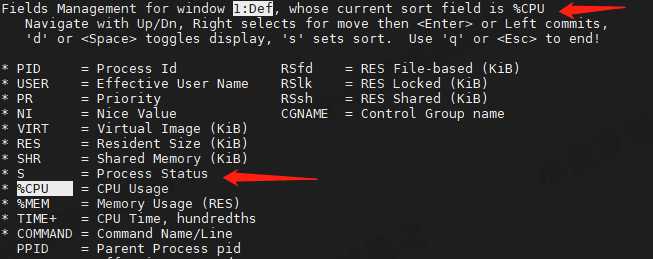
可以看到默认排序的列是 %CPU,这里改成 S 列,就可以更快看到哪些进程的状态是 R 了
来看看到底有哪些 R 状态的进程呢
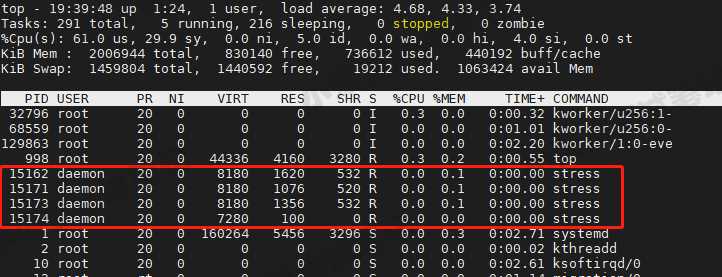
- 真正处于 Running(R)状态的,却是几个 stress 进程
- 这几个 stress 进程就比较奇怪了,需要做进一步的分析
观察一段时间, stress 进程的变化
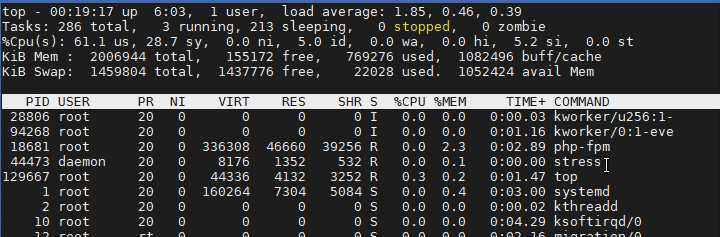
每次刷新列表,stress 进程的数量都会变化,而且 PID(进程号)也会跟着变
更具体的动态查看 stress 进程的变化
watch -d ‘ps aux | grep stress | grep -v grep‘
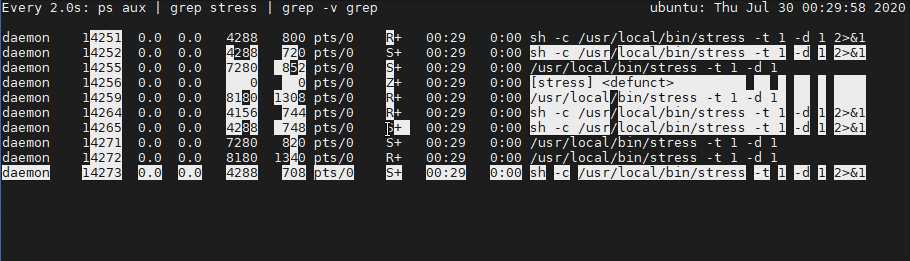
- 其实可以看到 stress 进程有三种状态:R、S、Z
- 多个 stress 进程在不断生成,由 R 变 S 再变 Z
- 三种变化:进程PID、进程数量、进程状态
进程 PID 在不断变化的可能原因
原因一:进程在不停地崩溃重启
比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启
原因二:这些进程都是短时进程
- 就是在其他应用内部通过 exec 调用的外面命令
- 这些命令一般都只运行很短的时间就会结束,很难用 top 这种间隔时间比较长的工具发现
stress 进程 PID 为什么在不断变化
首先,我并没有手动执行 stress 命令,所以它很大可能是通过其他命令去执行的
找到 stress 的父进程

stress 是被 php-fpm 调用的子进程,并且进程数量不止一个(这里是 2 个)
grep 查找是否有代码在调用 stress

可以看到, index.php 文件是包含了 stress 命令
index.php 源码
<?php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
?>r
- 很明显,就是 index.php 中调用了 stress 命令
- 每个请求都会调用一个 stress 命令,模拟 I/O 压力
- stress 会通过 write() 、 unlink() 对 I/O 进程进行压测
猜测
就是因为 stress 模拟 I/O 压力导致的 CPU 使用率升高
灵魂拷问
如果是模拟 I/O 压力,为什么 pidstat 命令的时候 iowait% 并不高呢
看来得继续深挖分析
VM2 带参数发送请求
index.php 有一句源码值得注意
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0)
当请求传了 verbose 参数时...
VM2 带 verbose 参数发送请求
curl http://172.20.72.58:10000?verbose=1
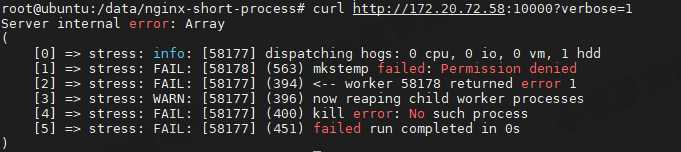
- 看到错误消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s
- 原来 stress 命令并没有成功,它因为权限问题失败退出了
结果分析猜测
正是由于权限错误,大量的 stress 进程在启动时初始化失败,过多的进程上下文切换,进而导致 CPU 使用率的升高
关于进程上下文切换的猜测验证
未压测前的系统上下文切换次数
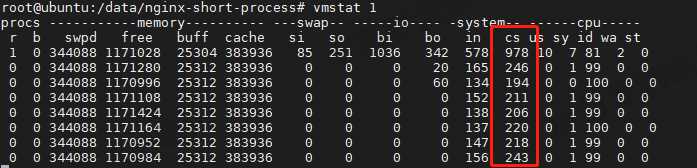
只有 200 左右
压测后的系统上下文切换次数
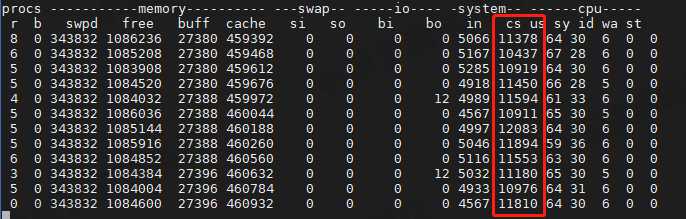
直蹦 10000 左右了,上下文切换次数的确涨了很多
stress 进程的上下文切换次数
前面是猜测 stress 进程有问题,那就来看看 stress 进程的上下文切换次数
pidstat -w 2 | grep stress
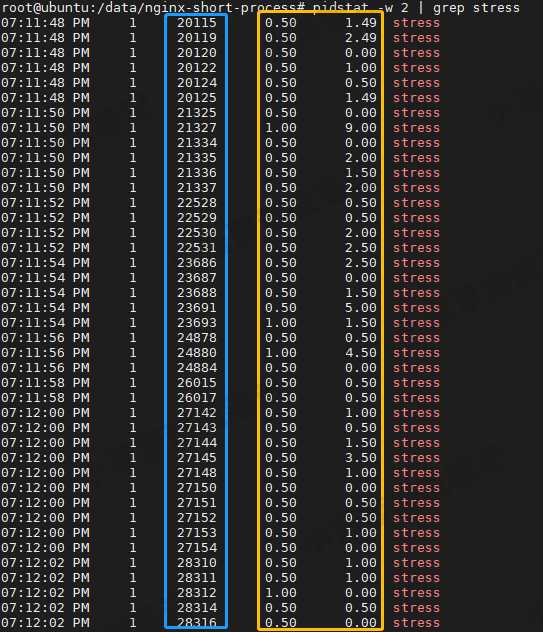
- 黄圈:自愿上下文切换次数和非自愿上下文切换次数并不高
- 蓝圈:进程PID 一直在变化
灵魂拷问
为什么 stress 进程的上下文切换次数这么低?
回答
- 因为 stress 是短时进程
- 会频繁的产生新的 stress 进程
- 系统需要从旧的 stress 进程切换到新的 stress 进程再运行,这样切换次数就会增加
VM1 通过 perf 查看性能分析报告
上一篇文章中也见到过这个 perf 命令
记录性能事件
等待大约 15 秒后按 Ctrl+C 退出
查看性能报告,结果分析
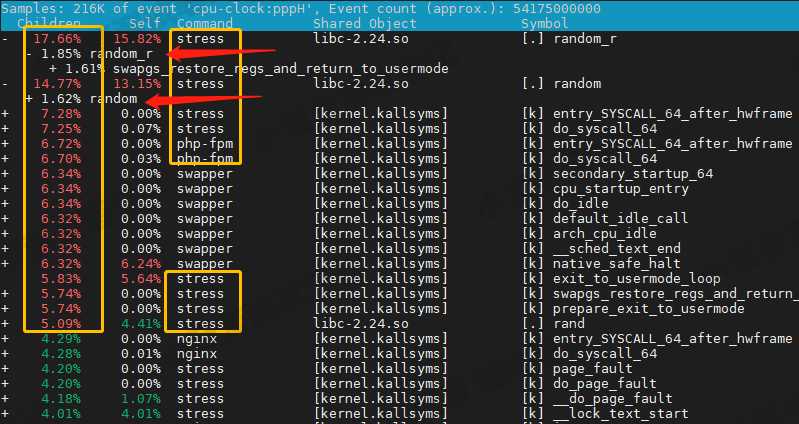
- 占了 CPU 时钟事件的前几名都是 stress 进程
- 而且调用栈中比例最高的是随机数生成函数 random() ,看来它的确就是 CPU 使用率升高的元凶了
拓展-swapper 进程是啥?
从上面报告其实可以看到排在前面的还有 swapper 进程,那么它是啥呢?
- swapper 跟 SWAP 没有任何关系
- 它只在系统初始化时创建 init 进程,之后,它就成了一个最低优先级的空闲任务
- 也就是说,当 CPU 上没有其他任务运行时,就会执行 swapper
- 所以,你可以称它 为“空闲任务”
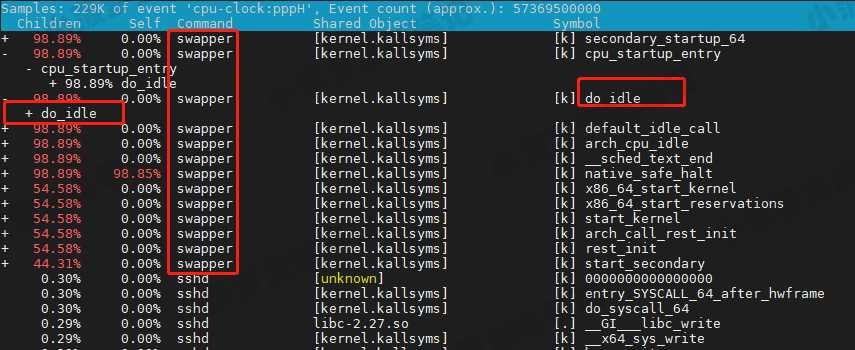
- 当没有其他任务时,可以看到 swapper 基本占满了 CPU 时钟事件
- 它的主要耗费都是 do_idle,也就是在执行空闲任务
优化问题
只要修复权限问题,并减少或删除 stress 的调用
总结
- CPU 使用率升高的主要原因就是短时进程 stress 频繁的进行进程上下文切换
- 对于短时进程,我们需要通过 pstree 命令找到它的父进程,然后再分析父进程存在什么问题
注意
当然,实际生产环境中的问题一般都要比这个案例复杂,在你找到触发瓶颈的命令行后,却可能发现,这个外部命令的调用过程是应用核心逻辑的一部分,并不能轻易减少或者删除;这时,你就得继续排查,为什么被调用的命令,会导致 CPU 使用率升高或 I/O 升高等问 题
分析整体思路
- 短时间压测,发现服务器性能低下
- 长时间压测,让服务器保持一个高负载的状态,从而可以慢慢分析问题所在
- 通过 top 命令监控系统资源情况,发现用户态的 CPU 使用率(us)较高,且空闲 CPU (id) 很低
- 但是找不到用户态 的 CPU 使用率很高的进程,最高就 6%
- 进一步通过 pidstat 查看是否有 CPU 使用率异常高的进程
- 发现 pidstat 行不通,再次通过 top 命令仔细观察
- 发现 Running(R)状态的进程有 6 个之多,但是 CPU 使用率较高的进程并没有处于 R 状态
- 切换 top 列表的排序规则,倒序,集中看 R 状态的进程一段时间,发现是 stress 进程,而且时多时少,进程 PID 还会变化
- 通过 watch 实时观察 stress 进程,发现 stress 进程会从从 R 状态变到 S 再变到 Z,而且会不断生成新的 stress 进程
- 猜测 stress 进程可能是短时进程,通过其他进程进行调用它
- 通过 pstree 找到 stress 进程的父进程,发现是 php-fpm 进程,接下来就是分析父进程了
- 通过 grep 查找 stress 命令是否存在 Nginx 应用中,发现存在 index.php 文件中
- 查看源码,确认每次请求都会触发 stress 命令
- stress 命令可以模拟 I/O 压力的,通过 top 看到 iowait 其实并不算高
- 在 VM2 发送带请求参数,可以确认 stress 命令是执行失败的
- 可以猜测大量的请求进来,导致大量的 stress 进程初始化执行失败,从而增加进程上下文切换次数增加,最终导致 CPU 使用率升高
- 通过 vmstat 对比压测前后的上下文切换次数,可以发现压测的上下文切换次数的确增加了
- 通过 pidstat 查看 stress 的上下文切换次数,但发现并不高,其实是因为 stress 是短时进程,上下文切换次数主要增加在旧进程切换到新进程的运行上
- 通过 perf record 录制性能事件 30s
- 通过 perf report 查看性能报告,可以看到占用 CPU 时钟事件的前几名都是 stress 进程,然后调度比例最高的是 random 函数
- 确认问题根源就是 stress 进程调用了 random 函数
炒鸡重点
- 其实有时候 top、vmstat、pidstat 命令用完了可能还不一定能发现问题根源
- 这个时候就要更加细心的查看这些命令返回结果其中的猫腻,虽然可能找不到问题根源,但可能会发现某些线索
- perf 虽然强大,但并不是一开始分析就适合用它的
性能分析(3)- 短时进程导致用户 CPU 使用率过高案例
标签:间隔 pac ini tput erro 自动 变化 stress 存在
原文地址:https://www.cnblogs.com/poloyy/p/13399523.html