标签:res temp list line lang n+1 == 数据 sea
?顺序(线性)查找
?二分查找/折半查找
?插值查找
?斐波那契查找
●有一个数列: {1,8,10, 89,1000,1234},判断数列中是否包含此名称【顺序查找】要求: 如果找到了,就提示找到,并给出下标值。
思路:如果查找到全部符合条件的值。
package com.xudong.DataStructures;
public class LinearSearchDemo {
public static void main(String[] args) {
int arr[] = {1,9,11,-1,34,89};
int index = linearSearch(arr,11);
if (index == -1){
System.out.println("没有找到!");
}else {
System.out.println("找到,下标位=" + index);
}
}
public static int linearSearch(int[] arr,int value){
//线性查找是逐一比对,发现有相同值,就返回下标
for (int i = 0; i < arr.length; i++) {
if (arr[i] == value){
return i;
}
}
return -1;
}
}
●二分查找是在有序数组进行二分查找

package com.xudong.DataStructures;
import java.util.ArrayList;
import java.util.List;
//使用二分查找的前提是该数组是有序的
public class BinarySearchDemo {
public static void main(String[] args) {
int arr[] = {1,8,10,89,1000,1000,1000,1234,};
List<Integer> resIndexList = binarySearch(arr,0,arr.length - 1,1000);
System.out.println("resIndex = " + resIndexList);
}
/**
* @param arr 数组
* @param left 左边索引
* @param right 右边索引
* @param findVal 要查找的值
*/
public static List<Integer> binarySearch(int[] arr, int left, int right, int findVal){
if (left > right){
return new ArrayList<Integer>();
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (findVal > midVal){//向右边递归
return binarySearch(arr,mid + 1,right,findVal);
}else if (findVal < midVal){//向左边递归
return binarySearch(arr, left, mid - 1, findVal);
}else {
List<Integer> resIndexList = new ArrayList<>();
int temp = mid - 1;
while (true){
//向左边扫描,把所有满足的相同的值的索引放入ArrayList中
if (temp < 0 || arr[temp] != findVal){
break;
}
resIndexList.add(temp);
temp -= 1;
}
resIndexList.add(mid);
//向右边扫描,把所有满足的相同的值的索引放入ArrayList中
temp = mid + 1;
while (temp <= arr.length - 1 && arr[temp] == findVal) {
resIndexList.add(temp);
temp += 1;
}
return resIndexList;
}
}
}
要求数组是有序的
●插值查找算法类似于二分查找,不同的是插值查找每次从自适应mid处开始查找,例如我们要从{1,8, 10, 89, 1000, 1234}找1这个数,那我们就会从前边开始找,插值查找就是应用这种原理
●将折半查找中的求mid索引的公式,low表示左边索引,high表示右边索引

●int midlIndex = low + (high - low)* (key - arr[low])/ (arr[high] - arr[low]);/插值索引/

?对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找,速度较快.
?关键字分布不均匀的情况下,该方法不一定比折半查找要好
package com.xudong.DataStructures;
public class InsertValueSearchDemo {
public static void main(String[] args) {
int[] arr = new int[100];
for (int i = 0; i < 100; i++) {
arr[i] = i + 1;
}
int index = insertValueSearch(arr,0,arr.length -1,100);
System.out.println("index =" + index);
}
public static int insertValueSearch(int[] arr, int left, int right, int findVal){
if (left > right || findVal < arr[0] || findVal > arr[arr.length - 1]){
return -1;
}
int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]);
int midVal = arr[mid];
if (findVal > midVal){
return insertValueSearch(arr,mid + 1,right,findVal);
}else if (findVal < midVal){
return insertValueSearch(arr, left, mid - 1, findVal);
}else {
return mid;
}
}
}
要求数组是有序的
●黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。取其前三位数字的近似值是0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比。这是一个神奇的数字,会带来意想不到的效果。
●斐波那契数列{1,1,2,3,5,8,13,21,34,55}发现斐波那契数列的两个相邻数的比例,无限接近黄金分割值0.618
●斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid不再是中间或插值得到,而是位于黄金分割点附近,即【mid=low+F(k-1)-1】
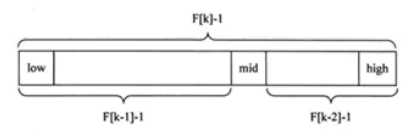
?由斐波那契数列【F[k]=F[k-1]+F[k-2]】的性质,可以得到【(F[k]-1 =(F[k-1]-1)+(F[k-2]-1)+1】。该式说明:只要顺序表的长度为【F[k]-1】,则可以将该表分成长度为【F[k-1]-1】和【F[k-2]-1】的两段,即如上图所示。从而中间位置为【mid=low+F(k-1)-1】
?类似的,每一子段也可以用相同的方式分割
?但顺序表长度n不一定刚好等于【F[k]-1】, 所以需要将原来的顺序表长度n增加至【F[k]-1】。这里的k值只要能使得【F[k]-1】恰好大于或等于n即可,由以下代码得到,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),都赋为n位置的值即可。
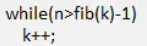
package com.xudong.DataStructures;
import java.util.Arrays;
public class FibonacciSearchDemo {
public static int maxSize = 20;
public static void main(String[] args) {
int[] arr = {1,8,10,89,1000,1234};
System.out.println("index=" + fibonacciSearch(arr,1234));
}
//非递归方法得到一个斐波那契数列
public static int[] fibonacci(){
int[] f = new int[maxSize];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < maxSize; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
//使用非递归的方式编写斐波那契查找算法
public static int fibonacciSearch(int[] a,int key){
int low = 0;
int high = a.length - 1;
int k = 0; //表示斐波那契分割数值的下标
int mid = 0;
int f[] = fibonacci();//获得斐波那契数列
//获得斐波那契分割数值的下标
while (high > f[k] - 1){
k++;
}
//f[k]的值可能大于数组a的长度,使用Array类创造新数组并指向temp[]
//不足的部分用0补充
int[] temp = Arrays.copyOf(a,f[k]);
//使用a数组最后的数填充temp
for (int i = high + 1; i < temp.length; i++) {
temp[i] = a[high];
}
//找到要找的数key
while (low <= high){
mid = low + f[k - 1] - 1;
if (key < temp[mid]){//向左边查找
high = mid - 1;
k--;
}else if (key > temp[mid]){//向右边查找
low = mid + 1;
k -= 2;
}else {
if (mid <= high){
return mid;
}else {
return high;
}
}
}
return -1;
}
}
标签:res temp list line lang n+1 == 数据 sea
原文地址:https://www.cnblogs.com/nnadd/p/13429691.html