标签:高性能 c 语言 back 显示 java 没有 提前 sdi redis
https://blog.csdn.net/bernkafly/article/details/89553711
redis概述
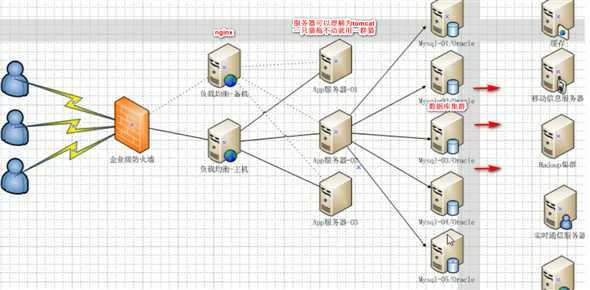
传统的数据访问:
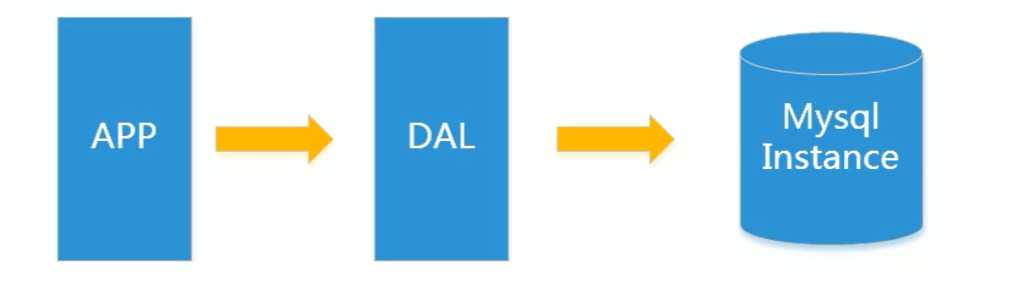
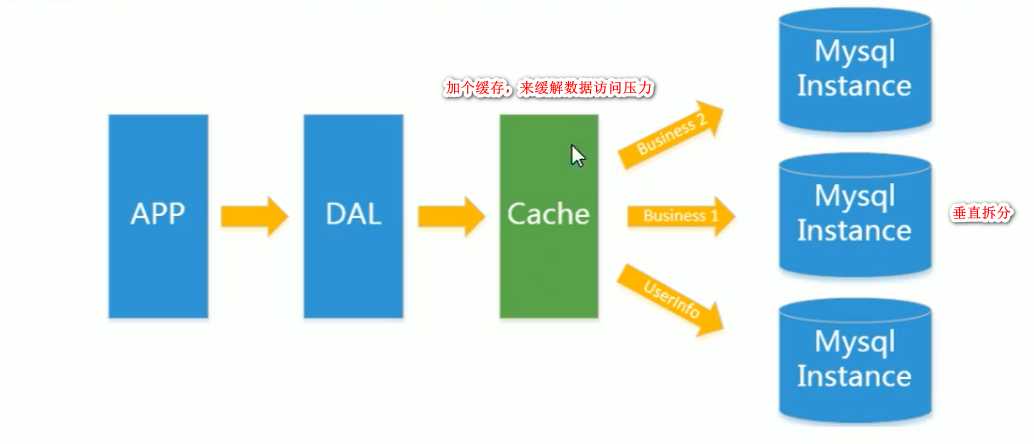
缓存 + MySql 垂直拆分:
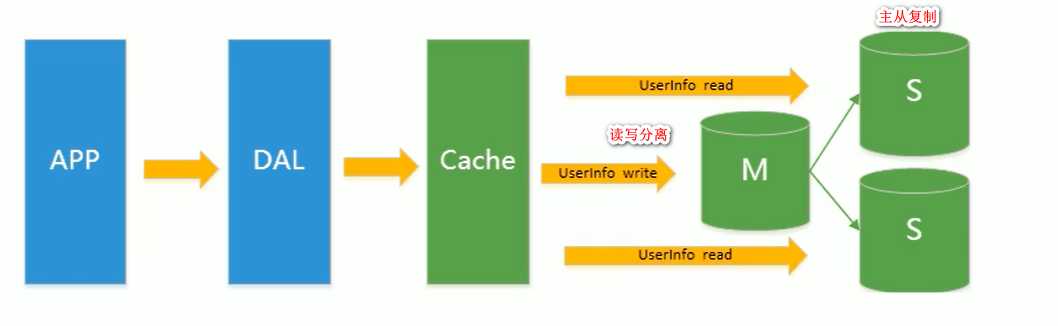
主从复制,读写分离:
分表分库+水平拆分+MySql 集群:
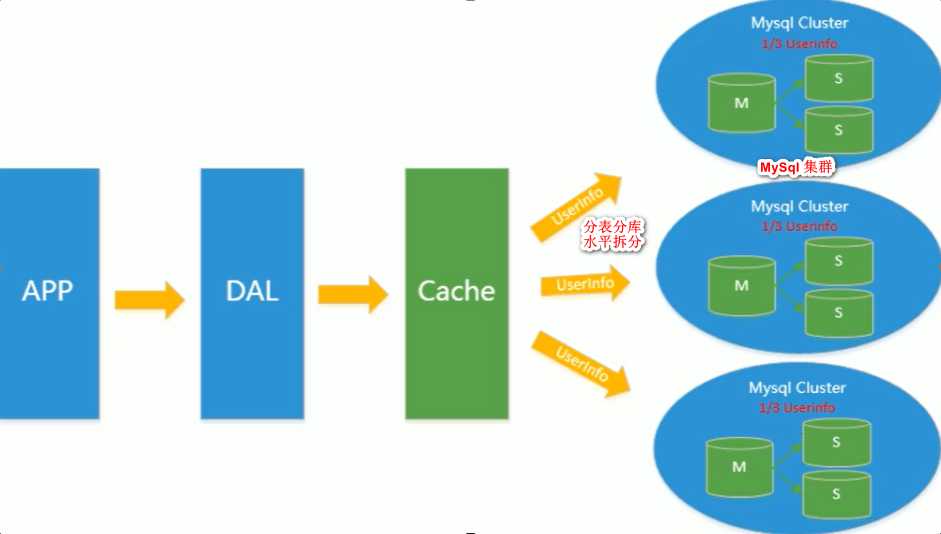
到了现在的数据访问流程:
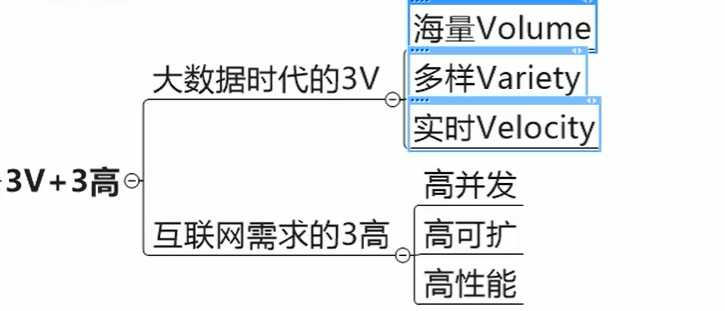
3V + 3高:
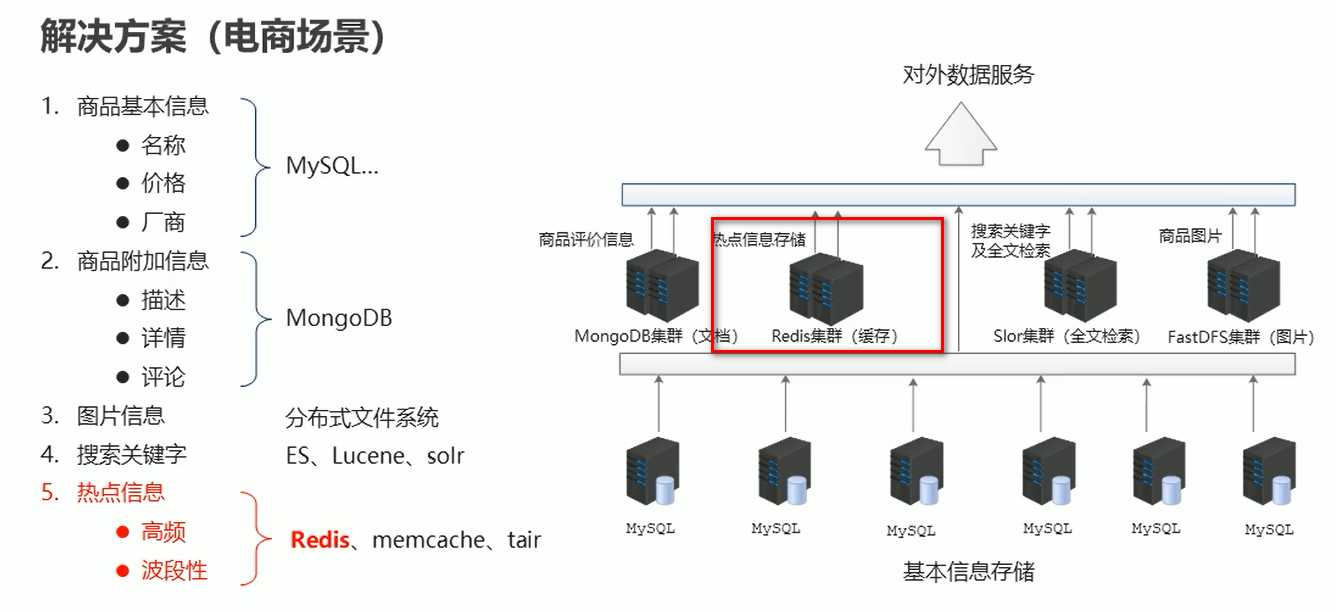
UDSL 这是阿里研发的数据库访问用的,如同我们连的jdbc ,我们不需要知道jdbc 怎么连接的数据库,我们直接连接jdbc 就可以了
UDSL 连接了多种数据库,因为如果找一个精通MySql、Oracle等多个数据库的人,是很难得,所有只要会用UDSL 就可以了
UDSL 完成了映射、API、热点缓存。。。
BSON
是一种类json 的一种二进制形式的存储格式,它和JSON 一样,支持内嵌的文档 和 数组对象
redis在项目中的位置
redis 是C 语言开发的高性能 键值对 的数据库
为了降低学习难度,现在window 下使用redis 。。。
安装完以后,双击redis-server.exe 运行redis
启动以后可以看到redis 默认端口是 6379,有一个PID,记住,然后把命令窗口关了再打开,发现PID 和刚刚的不一样,每次打开的都是不一样的,
切记:不可以打开两个redis 服务,会闪退的,除非把redis 端口改了,才可以打开多个redis 服务
先打开redis-server.exe 再打开redis-cli.exe 就可以看到端口号,说明连上了
redis 基本操作:k - value 操作!!
添加: set [key] [value] 比如: set wb wangbiao
查询: get [key] 比如: get wb
* 如果不存在,返回 nil
然后可以打开服务端,再打开客户端,在客户端输入命令试试。。。
清屏: clear
退出: quit exit <ESC>:esc 是按一下esc 键就直接退出了。。。
redis 数据类型
string hash list set sorted_set
数据类型指的是 右边的value 的类型!
stirng:单个数据,也是最简单的存储类型,虽然可以存储数字,也可以用,比如100,但本质还是一个字符串
操作:
添加:set [key] [value]
添加多个:mset [key1] [value1] [key2] [value2] [key3] [value3]。。。 比如:mset a 姓名 b 性别 c 年龄 a b c 分别是三个值的 键!
切记:原来有的值,再写的话会覆盖,没有的就是添加
获取:get [key]
获取多个:mget [key1] [key3] [key3]。。。
删除:del [key]
获取数值的长度,就是字母的个数:strlen [key] 返回的一个数字,即字符串长度
在数值后面追加 数值内容:append [key] [value] 比如:已经有了一个键是 wb 值是 wangbiao 如果:append wb 111 的话,get wb 结果就是王彪111
注意:如果已经存在 key,就是追加,如果之前没有key 就会新建一个 键值对 数据
数值增减操作:切记:只能对数字的string 操作,如果值 为字符串,那还怎么增减数字 啊,肯定会报错!!如果添加的为负数,那就等于是减少
比如数据量过大时候,一个表肯定不行,需要分表,这时候key 在不同表里会有重复的可能,就把数据覆盖了,造成了数据丢失,
解决方案:
incr [key] 可以通过key 设置value 就像主键自增一样,执行一次,value 就会+1
incrby [key] [increment] 和上面incr 一样,就是可以设置增加的数值,比如:之前如果有个key 为a,value 为1,incrby a 100,最后的value 值为 101
incrbyfloat [key] [increment] 通过命令就能看出来,是可以增加小数
decr [key] 可以减少数值,这个命令指的是一个一个减少
decrby [key] [increment] 可以设置减少数值的范围
数据时效设置:就是设置数据能活多久
setex [key] [seconds] [value] 设置数据存活多少秒 比如:setex a 10 abc 数值abc 就只有10秒存活时间
psetex [key] [milliseconds] [value] 设置数据存活多少毫秒
切记:如果设置了存活多久以后,又 set key value 时候,如果 key 一样,之前的设置存活多久会直接无效,值也会被set 命令设置的值给替换掉!
string 类型的注意:
数据最大存储量:512M
数值计算的最大范围:不能超过JAVA 中long 的最大值!
string 类型的应用场景:
比如:需要给一个用户设置粉丝数,通常给key 设置的是:表名+主键+主键的值+属性,然后设置value
set user:id:321513:fans 99999
另外一种方法:以json 格式存储,比如需要设置粉丝,还设置博客订阅数
set user:id:321513 {id:321513,blogs:123,fans:99999}
hash类型 因为redis 本来就是 key value 形式存储的,但hash 也是key value 这只的键值对形式,就是说,redis 的value 里又是一个键值对!
基本操作:
如果执行的是之前存在的key ,那就会修改掉以前的数据
添加/修改数据: hset [key] [field] [value] 比如:hset user name wangbiao 再来一个:hset user age 25
添加多个值: hmset [key] [fied1] [value1] [field2] [value2] 比如:hmset user name wangbiaobiao age 3
获取数据: hget [key] [field] 比如:hget user name 返回wangbiao
hgetall [key] 比如hgetall user 返回的是user 这个hash 的所有属性
获取多个数据: hmget [key] [field1] [field2]。。。 比如:hmget user name age 获取的只有值,不像 hgetall key 那样,键值对都显示出来了
删除数据: hdel [key] [field1] [field2] 比如:删除一个就是 hdel user name 删除两个就是:hdel user name age
获取 key 的数量: hlen [key] 比如:hlen user 返回的就是2,因为user 里只有name 和 age 两个属性
获取哈希表是否有什么字段: hexists [key] [field] 比如:hexists user name 返回1,如果hexists user aaa 就返回的是0
hash 扩展 和 注意事项
获取一个哈希表里的所有字段: hkeys [key] 比如:hkeys user 返回的是user里的name 和 age 这两个属性
获取一个哈希表的所有值: hvals [key] 比如:hvals user 返回的是wangbiao 和 3 这两个user 里的值
设置指定字段增加数值: hincrby [key] [field] [increment] 比如:hincrby user age 1 返回的4
设置增加字段增加为小数: hincrbyfloat [key] [field] [increment]
注意:虽然hash 非常灵活,但是不要什么都往hash 里面塞东西,会很影响效率!
hash 适合做购物车
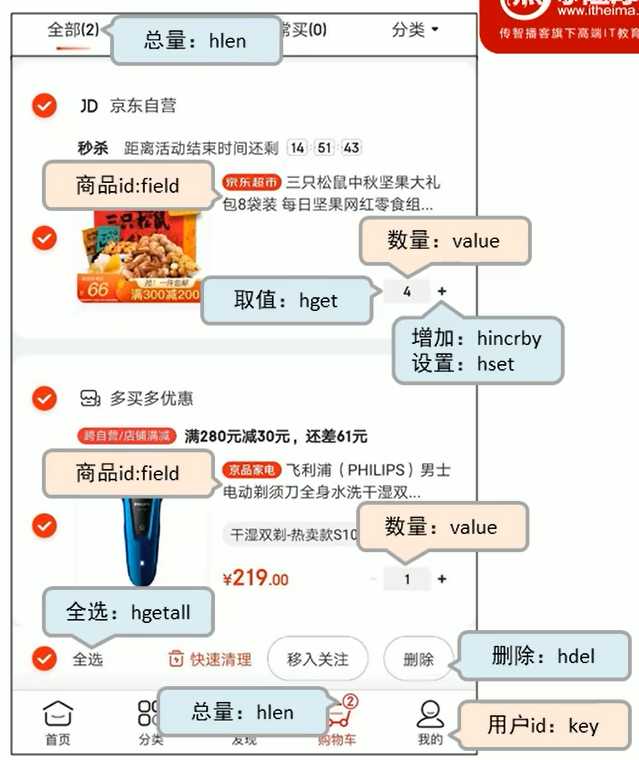

这里有个语法非常重要:
hsetnx [key] [field] [value] 就是说,如果有这个数据,就会执行不成功,如果没有这个 field ,就会执行成功
list 类型 这里指的是双向链表结构,list 类型数据操作都是stirng 类型的
基本操作:
添加/修改:
lpush [key] [value1] [value2]... 从左边添加数据 比如:lpush list1 1 2 3 添加一个 或 添加多个是一样的
rpush [key] [value1] [value2]... 从右边添加
要注意的是:比如从左边进去1 2 3 三个值,查到的结果是3 2 1 是反着的,如果想正着,那就容右边进
获取数据:
lrange [key] [start] [stop] 比如:lrange list1 0 2 这个必须要添加开始 和 结束,如果不知道有多少个,那就lrange list1 0 -1
lindex [key] [index] 这个通过索引获取的一个 值!
len [key] 这个查到的是 list 数据类型里有多少个数值
删除数据:
lpop [key] 从左边删除出去一个
rpop [key] 从右边删除出去一个
规定时间内移除数据:
blpop [key1] [key2] [timeout] 可以设置多少秒以内可以获取数据,比如:blpop list1 10 就是十秒内数据有效,超过十秒就访问不到数据了,当然还可以写多个redis 的key ,那就等于是同多个数据结构里去找
brpop [key1] [key2] [timeout] 这个跟上面的一样,一左一右。。。
回想朋友圈的点赞:
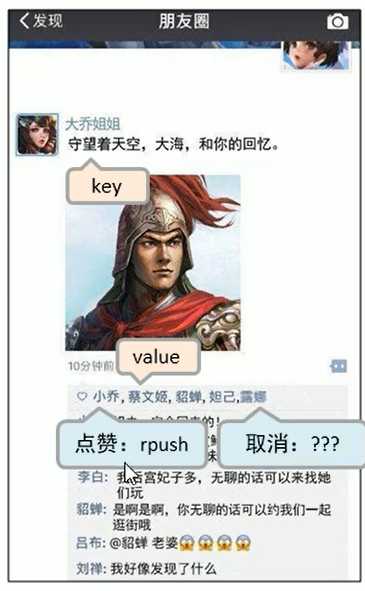
比如,有个人取消了点赞,就直接从中间名单里消失,
lrem [key] [count] [value] 删除指定数据,count 表示删除多少个,比如有多个一样的重复的数据,有5 个,我要删3个:lrem aaa 3 a
list 可以实现日志的消息队列,如下图:
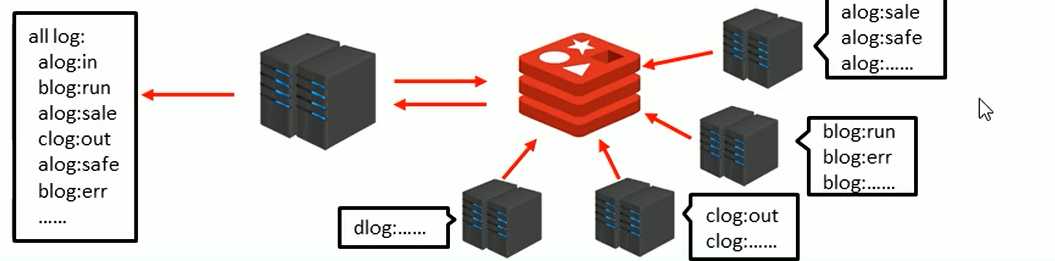
现在日志存在a b c d 四台服务器,如果想要看所有的日志,总不能一个一个的服务器上拿日志,最好的是定义redis 的 key,
以key 的字段名去打印日志,最后在直接查找lrange log 0 -1 就把所有的日志都查出来了,因为list 本来就是自己会排序的
set 类型 存储大量数据,查询效率高,与hash 的存储结构完全相同,只存键,不存值,并且值不允许重复,可以利用不重复的特征去做 数据过滤 的问题
添加数据: sadd [key] [member1] [member2] 比如:sadd users zs li ww 添加张三李四王五
获取全部数据: smembers [key] 比如:smembers users
删除数据: srem [key] [member1] [member2] 比如:srem users ww 王五被删除
获取集合数据总量: scard [key] 比如:scard users 返回 2,因为刚刚ww 被删除了
判断集合是否包含指定数据: sismember [key] [member] 比如:sismember users zs 返回1,因为users里有zs 张三
随机获取集合中的一个 或 多个数据: srandmember [key] [count] 比如:srandmember users 1 返回的是随机的一个值
随机获取一个 或 多个数据,但是集合中就会直接移除,等于剪切的意思: spop [key] [count] 比如:spop users 2 获取两个,集合里就删除了两个

求两个集合的交、并、差集:
交:sinter [key1] [key2] 比如:sinter 集合1 集合2 返回的是两个集合里存在有的一样的数据
并:sunion [key1] [key2] 比如:sunion 集合1 集合2 返回的是连个集合合并的数据,当然,有重复的数据是只显示一次的
差:sdiff [key1] [key2] 这个看先后顺序,sdiff 集合1 集合2 和 sdiff 集合1 集合2 结果是不一样的
求两个集合的交、并、差集,并存在指定的集合中
交:sinterstore [destination] [key1] [key2] 比如:sinterstore 集合3 集合1 集合2 这样就把1 和 2 交的部分存在了集合3里,下面的也是这种语法
并:sunionstore [destination] [key1] [key2]
差:sdiffstore [destination] [key1] [key2]
把指定的数据从原始集合里 移动到 目标集合里
smove [source] [destination] [member] 比如:smove 集合2 集合1 aaa 就是把 集合2 里的 aaa 移到了 集合1里面了
sorted_set 类型 除了像set 类型那样可以存储大量数据,但是支持排序
添加数据:
zadd [key] [score1] [member1] [score2 member2]... 比如:zadd users 100 zs 90 ls 添加一个集合users ,zs张三成绩100,ls李四成绩90
获取全部数据:
zrange [key] [start] [stop] [WITHSCORES] 比如:zrange users 0 -1 返回的是成绩人的名字,如果:zrange users 0 -1 withscores 返回的是成绩人名字 + 成绩 都显示
zrevrange [key] [start] [stop] [WITHSCORES] 和上面用法一样,这个是倒叙,从大到小排列
删除数据:
zrem key member [member...] 比如:zrem users zs 张三成绩就删除了。。
按条件查询数据:
zrangebyscore key min max [WITHSCORES] [LIMIT] 比如:zrangebyscore users 50 99 withscores 查看50 到 99 之间的分数
但是如果:zrangebyscore users 50 99 limit 0 3 withscores 分页查询,跟mysql一样的
zrevrangebyscore key max min [WITHSCORES] 跟上面一样的,倒序而已
条件删除数据:
zremrangebyrank key start stop 比如:zremrangebyrank users 0 1 按下标索引删除数据,这个就表示前两个删除了
zremrangebyscore key min max 比如:zremrangebyscore users 20 50 按数据值删除数据,20 到 50之间的数据都删除
获取集合数据总量:
zcard key 比如:zcard users 返回的是2,因为只有两个数据
zcard key min max 比如:在card key 50 99 获取50 到 99 之间有几个数据
集合交、并 操作:
zinterstore destination numkeys key [key]... 比如:zinterstore 集合3 集合1 集合2 返回的是,只有一样的数值名称,并且把值全相加了
但是如果:zinterstore 集合3 集合1 集合2 aggregate max 返回的是数值名称一样的值,最大的是值是多少
zunionstore destination numkeys key [key]...
获取数据对应的索引:
zrevrank key member 比如:zrevrank users zs 查看zs 张三的下标索引是多少,这个从 小 到 大
zrank key member 比如:zrank users zs 这个和上面的一样,是从大到小排序的下标
score 值获取:
zscore key member 比如:zscore users zs 获得zs 张三的值
修改:
zincrby key increment member 比如:zincrby users 50 zs zs 张三的值在原来基础上又加了 50
sorted_set 注意事项:
sorted_set 底层还是基于 set 结构的,它保存的数据可以是一个双精度 double 值,当修改数据时,虽然返回 0 看到的是修改失败,但实际有可能已经改了!
redis 的 key 的通用操作:
删除指定key: del [key]
查看key 是否存在: exists [key]
获取key 的类型: type [key]
为指定 key 设置有效期:
expire [key] [secods] 比如:expire users 10 等10 秒过后,users 这个 key 无效了
pexpire [key] [milliseconds] 这个和上面一样,这个是设置的 毫秒 值
expireat [key] [timestamp] 这个是时间戳
pexpireat [key] [milliseconds-timestamp] 毫秒的时间戳
获取key 的有效时间:
ttl [key] 可以查看key 还有多少秒 的有效时间 返回 -1,说明存在但没有设置有效期,返回-2,说明已经失效了
pttl [key] 这个是毫秒
把 key 设置成永久性的,可以一直访问的到的:
persist [key]
为 key 改名:
rename [key] [newkey] 如果之前的名字存在,就直接改了,会覆盖掉之前的名字,之前的就不存在了
renamenx [key] [newkey] 如果有改的新的名字 也已经存在了,就会修改失败,改的新的名字没有存在的话,就会修改成功
对所有 key 排序
sort + 后面有很多属性 可以sort users 这样就是从小到达排序,后面还可以再跟其他属性的方法,倒序,分组什么的
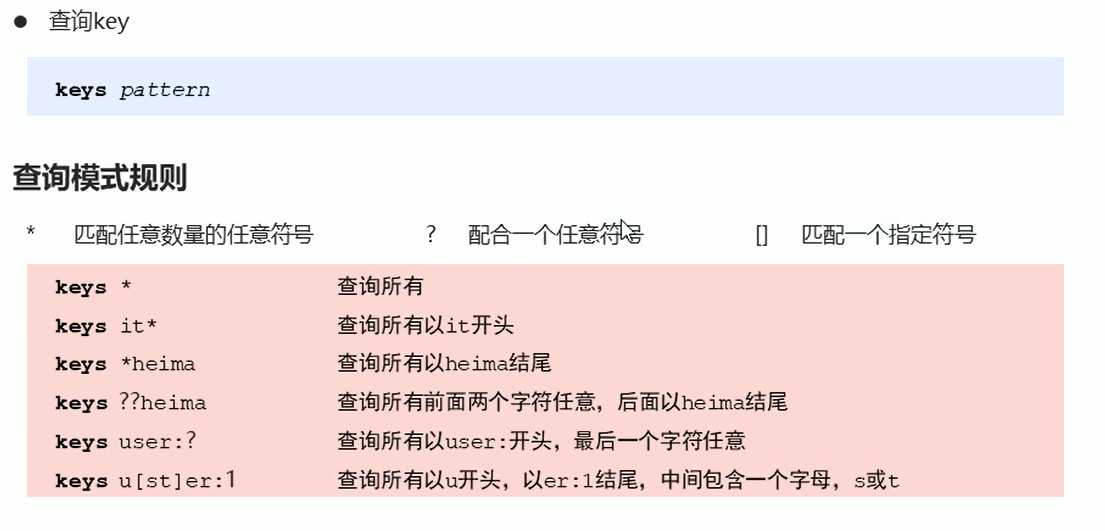
redis 为了避免 key 的重复问题,把数据库分为16份,编号0--15
切换数据库: select [index] 比如:select 1 反正0 - 15之间的数字都可以,一般不会这么叫,只是确实存在分为了16个数据库
quit 退出。。
ping 为了测试是否连接上了服务,连接上的话会返回pang 没连上就没反应的
echo message 这个就是打印,后面跟什么,就打印什么
数据移动: move [key] [db] 比如:move aaa 1 就是提前先切换到有aaa 的这个数据库,执行了这个以后,aaa 就到了 1 数据库
数据清除:这个是危险操作!
dbsize 看数据库有多少数据,返回一个数字
flushdb 这个会删除当前的数据库里所有的数据,坚决不用!
flushall 这个是所有的0--15 的数据库的所有数据全部删除!!坚决不用!
使用 Jedis:
依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
然后就可以直接测试:
public class JedisTest {
@Test
public void testJedis(){
//1 连接redis
Jedis jedis = new Jedis("127.0.0.1", 6379);
//2 操作redis
jedis.set("name","wangbiao");
String name = jedis.get("name");
System.out.println(name);
//3 关闭释放连接
jedis.close();
}
}
jedis 里完整的包含了redis 里的所有方法!所以就想用redis 一样用 jedis

可以自己做一个JedisPool 的工具类:
写一个properties 文件:
redis.host=127.0.0.1
redis.port=6379
redis.maxTotal=30
redis.maxIdle=10
工具类:
package com.biao.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.ResourceBundle;
public class JedisUtils {
private static JedisPool jp = null;
private static String host = null;
private static int port;
private static int maxTotal;
private static int maxIdle;
static {
ResourceBundle rb = ResourceBundle.getBundle("redis");
host = rb.getString("redis.host");
port = Integer.parseInt(rb.getString("redis.port"));
maxTotal = Integer.parseInt(rb.getString("redis.maxTotal"));
maxIdle = Integer.parseInt(rb.getString("redis.maxIdle"));
JedisPoolConfig jpc = new JedisPoolConfig();
jpc.setMaxIdle(maxIdle);
jpc.setMaxTotal(maxTotal);
jp = new JedisPool(jpc,host,port);
}
public static Jedis getJedis(){
return jp.getResource();
}
public static void main(String[] args) {
JedisUtils.getJedis();
}
}
redis-desktop-manager: 可视化操作redis 的工具
下一篇是Linux 上真实的玩转Redis
标签:高性能 c 语言 back 显示 java 没有 提前 sdi redis
原文地址:https://www.cnblogs.com/abiu/p/13440919.html