标签:特性 数据库 postgres lte rom record sel 有趣 之一
在前几篇文章中,我们讨论了PostgreSQL索引引擎、访问方法的接口以及两种访问方法:hash索引和B-tree。在本文中,我们将描述GiST索引。
GiST
GiST是广义搜索树«generalized search tree»的缩写。这是一个平衡搜索树,就像前面讨论的«b-tree»。
有什么区别吗?«btree»索引严格地与比较语义联系在一起:支持«greater»、«less»和«equal»操作符是它唯一能做的(但是非常有能力!)然而,对于现代数据库存储的数据类型,这些操作符根本没有意义:地理数据、文本文档、图像……
GiST索引方法可以帮助我们处理这些数据类型。它允许定义一个规则来跨平衡树分发任意类型的数据,并定义一种使用此表示形式来供操作符访问的方法。例如,GiST index可以«accommodate»R-tree用于支持相对位置操作符(位于左侧、右侧、contains等)的空间数据,或者RD-tree用于支持交集或包含操作符的集合。
由于可扩展性,可以在PostgreSQL中从头开始创建一种全新的方法:为此,必须实现与索引引擎的接口。但这不仅需要对索引逻辑的预想,还需要对数据结构映射到页,锁的有效实现以及对WAL日志的支持。所有这些都需要具备较高的开发人员技能和巨大的人力资源。GiST通过接管低级问题并提供其自己的接口来简化任务:几种功能与技术无关,而与应用领域有关。从这个意义上讲,我们可以将GiST视为构建新访问方法的框架。
架构
GiST是由节点页组成的高度平衡树。 节点由索引行组成。
通常,叶节点的每一行(叶行)都包含一些谓词(布尔表达式)和对表行(TID)的引用。 索引数据(键)必须符合此谓词。
内部节点的每一行(内部行)还包含一个谓词和对子节点的引用,并且子树的所有索引数据都必须满足此谓词。 换句话说,内部行的谓词包括所有子行的谓词。GiST索引的这一重要特征取代了B树的简单排序。
GiST树中的搜索使用专门的一致性函数(«consistent»)-接口定义的功能之一,并且以自己的方式为每个受支持的操作符家族实现。
为索引行调用一致性函数,并确定该行的谓词是否与搜索谓词(指定为“索引字段运算符表达式”)一致。对于内部行,此函数实际上确定是否需要下降到相应的子树,而对于叶行,此函数确定索引的数据是否满足谓词。
搜索从根节点开始,就像普通的树搜索一样。一致性函数支持找出有意义的子节点(可能有多个)可以输入,而哪些子节点不需要。然后对找到的每个子节点重复该算法。如果节点是叶子,则由一致性函数选择的行将作为结果之一返回。
搜索是深度优先的:算法首先尝试到达叶节点。这样可以在可能的情况下尽快返回第一结果(如果用户只对几个结果感兴趣,而不对所有结果感兴趣,这可能很重要)。
一致性函数与 «greater», «less», 或 «equal»运算符无关。一致性函数的语义可能完全不同,因此,不要假定索引以特定顺序返回值。
我们将不讨论GiST中值的插入和删除算法:更多接口函数执行这些操作。但是,有一点很重要。将新值插入索引后,将选择该值在树中的位置,以便其父行的谓词尽可能少地扩展(理想情况下完全不扩展)。但是,当删除一个值时,父行的谓词不再减少。仅在以下情况下会发生这种情况:将页分为两部分(页没有足够的空间来插入新的索引行时),或者从头开始创建索引(使用REINDEX或VACUUM FULL命令)。因此,频繁更改数据的GiST索引的效率会随时间降低。
此外,我们将考虑一些针对各种数据类型和GiST有用属性的索引示例:
·点(和其他几何实体)和最近邻居的搜索。
·间隔和排除约束。
·全文搜索。
R-tree用于points
我们将通过一个平面中的点的索引示例来说明上述内容(我们还可以为其他几何实体建立类似的索引)。 常规的B树不适合这种数据类型的数据,因为没有为点定义比较运算符。
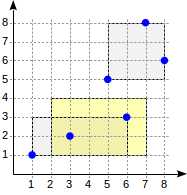
R-tree的想法是将平面划分为矩形,这些矩形总共覆盖所有索引的点。 索引行存储一个矩形,谓词可以这样定义:“所寻找的点位于给定的矩形之内”。
R树的根将包含几个最大的矩形(可能是相交的)。子节点将包含较小尺寸的矩形,这些矩形嵌入到父节点中,并且覆盖所有基础点。
从理论上讲,叶节点必须包含要索引的点,但是所有索引行中的数据类型必须相同,因此,再次存储了矩形,但是将“折叠”成点。
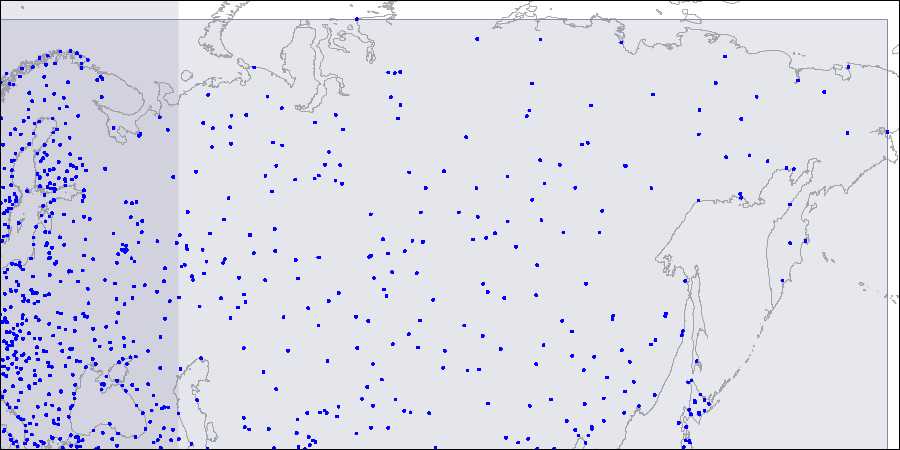
为了可视化这种结构,我们提供了R树的三层的图像。点是机场的坐标(类似于演示数据库的“ airports”表中的坐标,但提供了来自openflights.org的更多数据)。
第一层:两个大的有交集的矩形
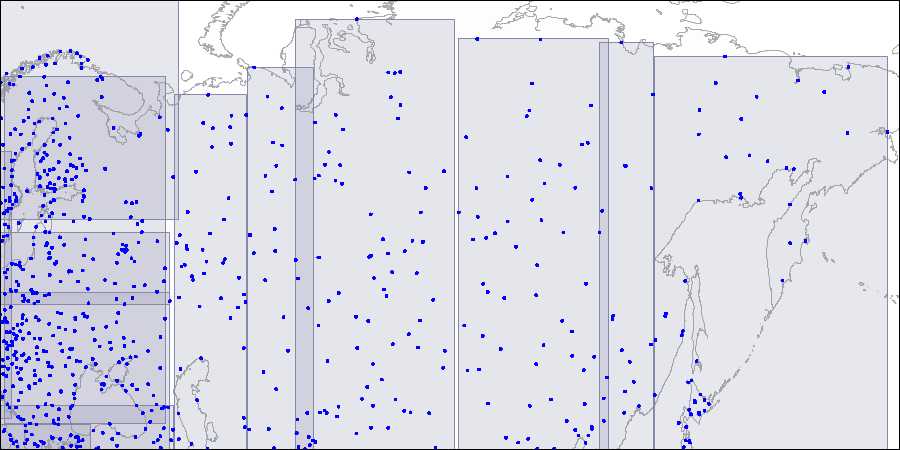
第二层:大的矩形被分为小的矩形
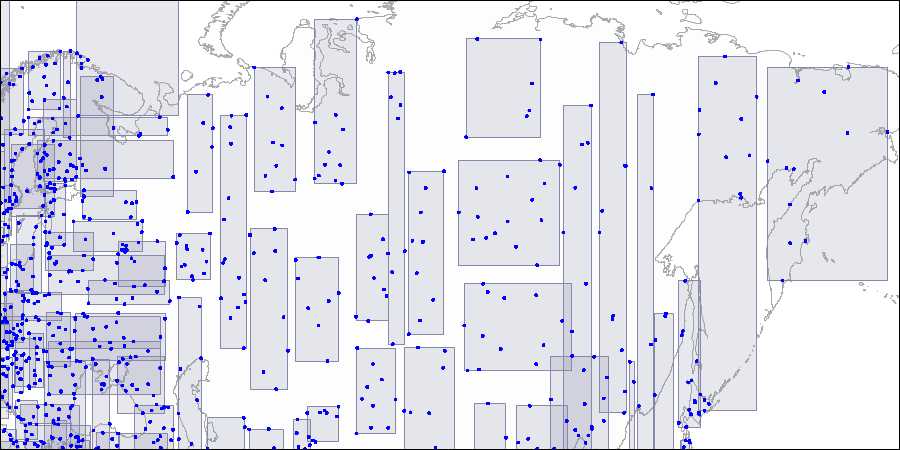
第三层:每个矩形都包含足够多的点以容纳一个索引页
现在让我们考虑一个非常简单的«一层»示例:
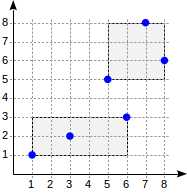
postgres=# create table points(p point); postgres=# insert into points(p) values (point ‘(1,1)‘), (point ‘(3,2)‘), (point ‘(6,3)‘), (point ‘(5,5)‘), (point ‘(7,8)‘), (point ‘(8,6)‘); postgres=# create index on points using gist(p);
通过这种拆分,索引结构将如下所示:
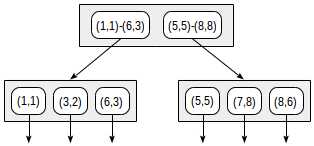
创建的索引可用于加速以下查询,例如:«查找给定矩形中包含的所有点»。这个条件可以形式化为:p <@ box ‘(2,1),(6,3)‘(来自«points_ops»家族的操作符<@表示«包含在»中):
postgres=# set enable_seqscan = off;
postgres=# explain(costs off) select * from points where p <@ box ‘(2,1),(7,4)‘;
QUERY PLAN
----------------------------------------------
Index Only Scan using points_p_idx on points
Index Cond: (p <@ ‘(7,4),(2,1)‘::box)
(2 rows)
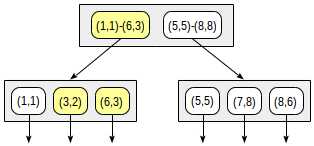
操作符(“indexed-field <@ expression”,其中indexed-field是一个点,表达式是一个矩形)的一致性函数定义如下。对于内部行,如果其矩形与表达式定义的矩形相交,则返回«yes»。对于叶子行,如果其点(«collapsed»矩形)包含在表达式定义的矩形中,则函数返回«yes»。
搜索从根节点开始。矩形(2,1)-(7,4)与(1,1)-(6,3)相交,但与(5,5)-(8,8)不相交,因此无需下降到第二个子树。
到达一个叶子节点,我们经历所包含的三个点,返回两个结果:(3,2)и(6,3)。
postgres=# select * from points where p <@ box ‘(2,1),(7,4)‘; p ------- (3,2) (6,3) (2 rows)
内部原理
不幸的是,«pageinspect»不允许查看GiST索引。但是还有另一种方法可用:«gevel»扩展。但是它不包括在标准交付中。可以自己尝试安装。
如果一切顺利,您将可以使用三个功能。首先,我们可以得到一些统计数据:
postgres=# select * from gist_stat(‘airports_coordinates_idx‘);
gist_stat
------------------------------------------
Number of levels: 4 +
Number of pages: 690 +
Number of leaf pages: 625 +
Number of tuples: 7873 +
Number of invalid tuples: 0 +
Number of leaf tuples: 7184 +
Total size of tuples: 354692 bytes +
Total size of leaf tuples: 323596 bytes +
Total size of index: 5652480 bytes+
(1 row)
很明显,机场坐标上的索引的大小是690页,索引由四个层组成:根层和两个内部层如上图所示,第四个层次是leaf。
实际上,8000个点的索引看起来要小得多:这里为清晰起见,它的填充系数为10%。
第二,我们可以输出索引树:
postgres=# select * from gist_tree(‘airports_coordinates_idx‘);
gist_tree
-----------------------------------------------------------------------------------------
0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) +
1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) +
1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) +
1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) +
2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) +
3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) +
4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) +
...
第三,我们可以输出存储在索引行的数据。注意以下细微差别:函数的结果必须转换为所需的数据类型。在我们的情况下,这个类型是«box»(一个边界矩形)。例如,注意顶层的5行:
postgres=# select level, a from gist_print(‘airports_coordinates_idx‘)
as t(level int, valid bool, a box) where level = 1;
level | a
-------+-----------------------------------------------------------------------
1 | (47.663586,80.803207),(-39.2938003540039,-90)
1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336)
1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047)
1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291)
1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088)
(5 rows)
实际上,上面提供的数据就是根据这些数据创建的。
到目前为止讨论的操作符(例如谓词p <@ box ‘(2,1),(7,4)‘中的<@)可以称为搜索操作符,因为它们指定查询中的搜索条件。
还有另一种操作符类型:排序操作符。它们用于按order BY子句的排序顺序的规范,而不是列名的常规规范。下面是这种查询的一个例子:
postgres=# select * from points order by p <-> point ‘(4,7)‘ limit 2; p ------- (5,5) (7,8) (2 rows)
p <->point‘(4,7)‘这是一个使用排序运算符<->的表达式,它表示从一个参数到另一个参数的距离。查询的意义是返回最接近点(4,7)的两个点。这样的搜索被称为k-NN ---- k最近邻居搜索。
为了支持这类查询,访问方法必须定义一个额外的距离函数,并且排序操作符必须包含在适当的操作符类(例如,用于点的«points_ops»类)。下面的查询显示了操作符及其类型(«s»-搜索和«o»-排序):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = ‘point_ops‘
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = ‘gist‘
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------+-------------+--------------
<<(point,point) | s | 1 strictly left
>>(point,point) | s | 5 strictly right
~=(point,point) | s | 6 coincides
<^(point,point) | s | 10 strictly below
>^(point,point) | s | 11 strictly above
<->(point,point) | o | 15 distance
<@(point,box) | s | 28 contained in rectangle
<@(point,polygon) | s | 48 contained in polygon
<@(point,circle) | s | 68 contained in circle
(9 rows)
策略的数量也被显示,并解释其含义。很明显,有比«btree»更多的策略,其中只有一些只是支持点。可以为其他数据类型定义不同的策略。
距离函数是为索引元素调用的,它必须计算从表达式(“indexed-field ordering-operator expression”)定义的值到给定元素的距离。对于叶元素,这只是到索引值的距离。对于内部元素,函数必须返回到子叶元素的最小距离。由于遍历所有子行代价很高,因此允许该函数乐观地低估距离,但以降低搜索效率为代价。但是,决不允许函数高估距离,因为这将破坏索引的工作。
distance函数可以返回任何可排序类型的值(对于排序值,PostgreSQL将使用相应的«btree»访问方法操作符家族中的比较语义,如前面所述)。
对于平面上的点,距离以通常意义上的方式解释:(x1,y1) <-> (x2,y2)的值等于横坐标和纵坐标的差平方和的平方根。点到边界矩形的距离取该点到该矩形的最小距离,如果该点位于矩形内,则取零。不需要遍历子点就可以很容易地计算出这个值,而且这个值肯定不会大于到任何子点的距离。
让我们考虑一下上述查询的搜索算法。
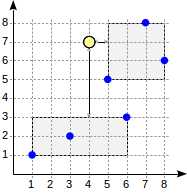
搜索从根节点开始。节点包含两个边界矩形。到(1,1)-(6,3)的距离是4.0,到(5,5)-(8,8)的距离是1.0。
子节点按照距离增加的顺序遍历。这样,我们首先下降到最近的子节点,计算到点的距离(为了便于观察,我们将在图中显示数字):
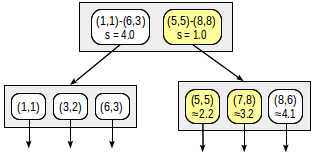
该信息足以先返回两个点(5,5)和(7,8)。由于我们知道到位于矩形(1,1)-(6,3)内的点的距离是4.0或更大,所以我们不需要下降到第一个子节点。
但如果我们需要找出前三个点呢?
postgres=# select * from points order by p <-> point ‘(4,7)‘ limit 3; p ------- (5,5) (7,8) (8,6) (3 rows)
尽管第二个子节点包含所有这些点,但是如果不查看第一个子节点,我们就不能返回(8,6),因为这个节点可以包含更近的点(因为4.0 < 4.1)。
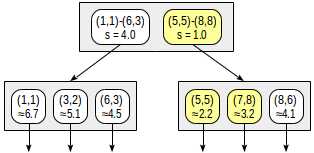
对于内部行,这个例子说明了距离函数的需求。通过为第二行选择更小的距离(4.0而不是实际的4.5),我们降低了效率(算法不必要地开始检查额外的节点),但没有破坏算法的正确性。
直到最近,GiST还是唯一能够处理排序操作符的访问方法。但是情况已经发生了变化:RUM访问方法(待进一步讨论)已经加入了这一组方法,而且老的B-tree也不太可能加入其中:我们的同事Nikita Glukhov开发的一个补丁正在社区讨论中。
从2019年3月开始,在即将发布的PostgreSQL 12(也由Nikita编写)中,为SP-GiST增加了k-NN支持。b树补丁仍在进行中。
R-trees用于intervals
使用GiST访问方法的另一个例子是对间隔进行索引,例如,时间间隔(«tsrange»类型)。所有的区别是内部节点将包含边界间隔,而不是边界矩形。
让我们考虑一个简单的例子。我们将出租一间小屋,并将预订间隔存储在一张表中:
postgres=# create table reservations(during tsrange); postgres=# insert into reservations(during) values (‘[2016-12-30, 2017-01-09)‘), (‘[2017-02-23, 2017-02-27)‘), (‘[2017-04-29, 2017-05-02)‘); postgres=# create index on reservations using gist(during);
该索引可用于加速以下查询,例如:
postgres=# select * from reservations where during && ‘[2017-01-01, 2017-04-01)‘;
during
-----------------------------------------------
["2016-12-30 00:00:00","2017-01-08 00:00:00")
["2017-02-23 00:00:00","2017-02-26 00:00:00")
(2 rows)
postgres=# explain (costs off) select * from reservations where during && ‘[2017-01-01, 2017-04-01)‘;
QUERY PLAN
------------------------------------------------------------------------------------
Index Only Scan using reservations_during_idx on reservations
Index Cond: (during && ‘["2017-01-01 00:00:00","2017-04-01 00:00:00")‘::tsrange)
(2 rows)
区间&&运算符表示相交;因此,查询必须返回与给定区间相交的所有区间。对于这样的操作符,一致性函数确定给定的区间是否与内部行或叶子页行中的值相交。
注意,这不是关于以某种顺序获取区间,尽管为区间定义了比较运算符。我们可以对区间使用«btree»索引,但在这种情况下,我们将不得不在不支持以下操作的情况下做:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = ‘range_ops‘
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = ‘gist‘
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------------+-------------+--------------
@>(anyrange,anyelement) | s | 16 contains element
<<(anyrange,anyrange) | s | 1 strictly left
&<(anyrange,anyrange) | s | 2 not beyond right boundary
&&(anyrange,anyrange) | s | 3 intersects
&>(anyrange,anyrange) | s | 4 not beyond left boundary
>>(anyrange,anyrange) | s | 5 strictly right
-|-(anyrange,anyrange) | s | 6 adjacent
@>(anyrange,anyrange) | s | 7 contains interval
<@(anyrange,anyrange) | s | 8 contained in interval
=(anyrange,anyrange) | s | 18 equals
(10 rows)
我们可以使用相同的«gevel»扩展查看内部。我们只需要记住在调用gist_print时改变数据类型:
postgres=# select level, a from gist_print(‘reservations_during_idx‘)
as t(level int, valid bool, a tsrange);
level | a
-------+-----------------------------------------------
1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00")
1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00")
1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00")
(3 rows)
R-tree用于Exclusion constraint(排除约束)
GiST索引可用于支持排除约束(EXCLUDE)。
排除约束确保任意两个表行的给定字段在某些操作符方面不会相互“对应”。如果选择«equals»操作符,我们就精确地得到了唯一的约束:给定的任意两行的字段互不相等。
索引支持排除约束以及唯一约束。我们可以选择任意的操作符:
1.它由索引方法-«can_exclude»属性(例如«btree»、GiST或spi -GiST,但不包括GIN)支持。
2.它是可交换的,即满足条件:a operator b = b operator a。
下面列出了一些合适的策略和操作符示例(操作符可以有不同的名称并不是对所有数据类型都可用):
· For «btree»:
- «equals» `=`
·For GiST and SP-GiST:
- «intersection» `&&`
- «coincidence» `~=`
- «adjacency» `-|-`
我们可以在排除约束中使用相等运算符,但这是不实用:唯一的约束会更有效。这就是为什么我们在讨论b-树时没有涉及排除约束。
让我们看一个使用排除约束的示例。不允许保留相交区间是合理的。
postgres=# alter table reservations add exclude using gist(during with &&);
一旦我们创建了排除约束,我们可以添加行:
postgres=# insert into reservations(during) values (‘[2017-06-10, 2017-06-13)‘);
但是试图插入一个相交的间隔到表中会导致错误:
postgres=# insert into reservations(during) values (‘[2017-05-15, 2017-06-15)‘);
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl" DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
«btree_gist» extension
让我们把问题复杂化。我们扩大我们的小生意,我们打算租几间小别墅:
postgres=# alter table reservations add house_no integer default 1;
我们需要修改排除约束,以便把门牌号也考虑进去。但是,GiST不支持整数的相等运算:
postgres=# alter table reservations drop constraint reservations_during_excl; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist" HINT: You must specify an operator class for the index or define a default operator class for the data type.
在这种情况下,“btree_gist”扩展将提供帮助,它为b-树固有的操作增加了GiST支持。最终,GiST可以支持任何操作符,那么为什么我们不应该教它支持«greater»、«less»和«equal»操作符呢?
postgres=# create extension btree_gist; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
现在我们仍然无法预定同一日期的第一个小屋:
postgres=# insert into reservations(during, house_no) values (‘[2017-05-15, 2017-06-15)‘, 1); ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
但是我们可以预定第二个:
postgres=# insert into reservations(during, house_no) values (‘[2017-05-15, 2017-06-15)‘, 2);
但是要注意,虽然GiST可以以某种方式支持«greater»、«less»和«equal»操作符,但是B-tree在这方面做得更好。因此,只有在本质上需要GiST索引时,才值得使用这种技术,就像我们的示例中那样。
RD-tree用于全文检索
全文检索
让我们从简单介绍PostgreSQL全文搜索开始(如果你已经知道,你可以跳过这一节)。
全文搜索的任务是从文档集中选择那些与搜索查询匹配的文档。(如果有很多匹配文档,那么找到最佳匹配非常重要,但在这里我们将不讨论它)
出于搜索的目的,文档被转换为专门化的类型«tsvector»,它包含lexemes及其在文档中的位置。词素(lexemes)是被转换成适合搜索的形式的单词。例如,单词通常被转换为小写,变量结尾被切断:
postgres=# select to_tsvector(‘There was a crooked man, and he walked a crooked mile‘);
to_tsvector
-----------------------------------------
‘crook‘:4,10 ‘man‘:5 ‘mile‘:11 ‘walk‘:8
(1 row)
我们还可以看到一些单词(叫做stop words)被完全删除了(«there»,«was»,«a»,«and»,«he»),因为它们可能出现得太频繁了,搜索起来没有意义。当然,所有这些转换都可以配置,但那就是另一回事了。
搜索查询用另一种类型表示:«tsquery»。粗略地说,一个查询由一个或几个由连接词连接的词素(lexemes)组成:«and»&,«or»|,«not»!..我们还可以使用括号来明确操作优先级。
postgres=# select to_tsquery(‘man & (walking | running)‘);
to_tsquery
----------------------------
‘man‘ & ( ‘walk‘ | ‘run‘ )
(1 row)
只有一个匹配操作符@@用于全文搜索。
postgres=# select to_tsvector(‘There was a crooked man, and he walked a crooked mile‘) @@ to_tsquery(‘man & (walking | running)‘); ?column? ---------- t (1 row) postgres=# select to_tsvector(‘There was a crooked man, and he walked a crooked mile‘) @@ to_tsquery(‘man & (going | running)‘); ?column? ---------- f (1 row)
写到这,这些信息已经足够了。在下一篇以GIN索引为特性的文章中,我们将更深入地研究全文搜索。
RD-trees
要想快速的全文搜索,首先,表需要存储一个类型为«tsvector»的列(以避免每次搜索时执行代价高昂的转换),其次,必须在该列上构建索引。其中一种可能的索引是GiST。
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# create index on ts using gist(doc_tsv); postgres=# insert into ts(doc) values (‘Can a sheet slitter slit sheets?‘), (‘How many sheets could a sheet slitter slit?‘), (‘I slit a sheet, a sheet I slit.‘), (‘Upon a slitted sheet I sit.‘), (‘Whoever slit the sheets is a good sheet slitter.‘), (‘I am a sheet slitter.‘), (‘I slit sheets.‘), (‘I am the sleekest sheet slitter that ever slit sheets.‘), (‘She slits the sheet she sits on.‘); postgres=# update ts set doc_tsv = to_tsvector(doc);
当然,将最后一步(将文档转换为«tsvector»)委托给触发器是很方便的。
postgres=# select * from ts; -[ RECORD 1 ]---------------------------------------------------- doc | Can a sheet slitter slit sheets? doc_tsv | ‘sheet‘:3,6 ‘slit‘:5 ‘slitter‘:4 -[ RECORD 2 ]---------------------------------------------------- doc | How many sheets could a sheet slitter slit? doc_tsv | ‘could‘:4 ‘mani‘:2 ‘sheet‘:3,6 ‘slit‘:8 ‘slitter‘:7 -[ RECORD 3 ]---------------------------------------------------- doc | I slit a sheet, a sheet I slit. doc_tsv | ‘sheet‘:4,6 ‘slit‘:2,8 -[ RECORD 4 ]---------------------------------------------------- doc | Upon a slitted sheet I sit. doc_tsv | ‘sheet‘:4 ‘sit‘:6 ‘slit‘:3 ‘upon‘:1 -[ RECORD 5 ]---------------------------------------------------- doc | Whoever slit the sheets is a good sheet slitter. doc_tsv | ‘good‘:7 ‘sheet‘:4,8 ‘slit‘:2 ‘slitter‘:9 ‘whoever‘:1 -[ RECORD 6 ]---------------------------------------------------- doc | I am a sheet slitter. doc_tsv | ‘sheet‘:4 ‘slitter‘:5 -[ RECORD 7 ]---------------------------------------------------- doc | I slit sheets. doc_tsv | ‘sheet‘:3 ‘slit‘:2 -[ RECORD 8 ]---------------------------------------------------- doc | I am the sleekest sheet slitter that ever slit sheets. doc_tsv | ‘ever‘:8 ‘sheet‘:5,10 ‘sleekest‘:4 ‘slit‘:9 ‘slitter‘:6 -[ RECORD 9 ]---------------------------------------------------- doc | She slits the sheet she sits on. doc_tsv | ‘sheet‘:4 ‘sit‘:6 ‘slit‘:2
索引应该如何构造?不能直接使用R-tree,因为不清楚如何为文档定义一个«边界矩形»。但是我们可以对访问集合(sets)方法进行一些修改,即所谓的RD-树(RD代表«Russian Doll»)。在这种情况下,集合被理解为词素(lexemes)的集合,但一般来说,集合可以是任意的。
rd-tree的一个思想是用一个边界集替换一个边界矩形,也就是一个包含子集所有元素的集合。
一个重要的问题是如何在索引行中表示集合。最简单的方法就是枚举集合中的所有元素。比如:
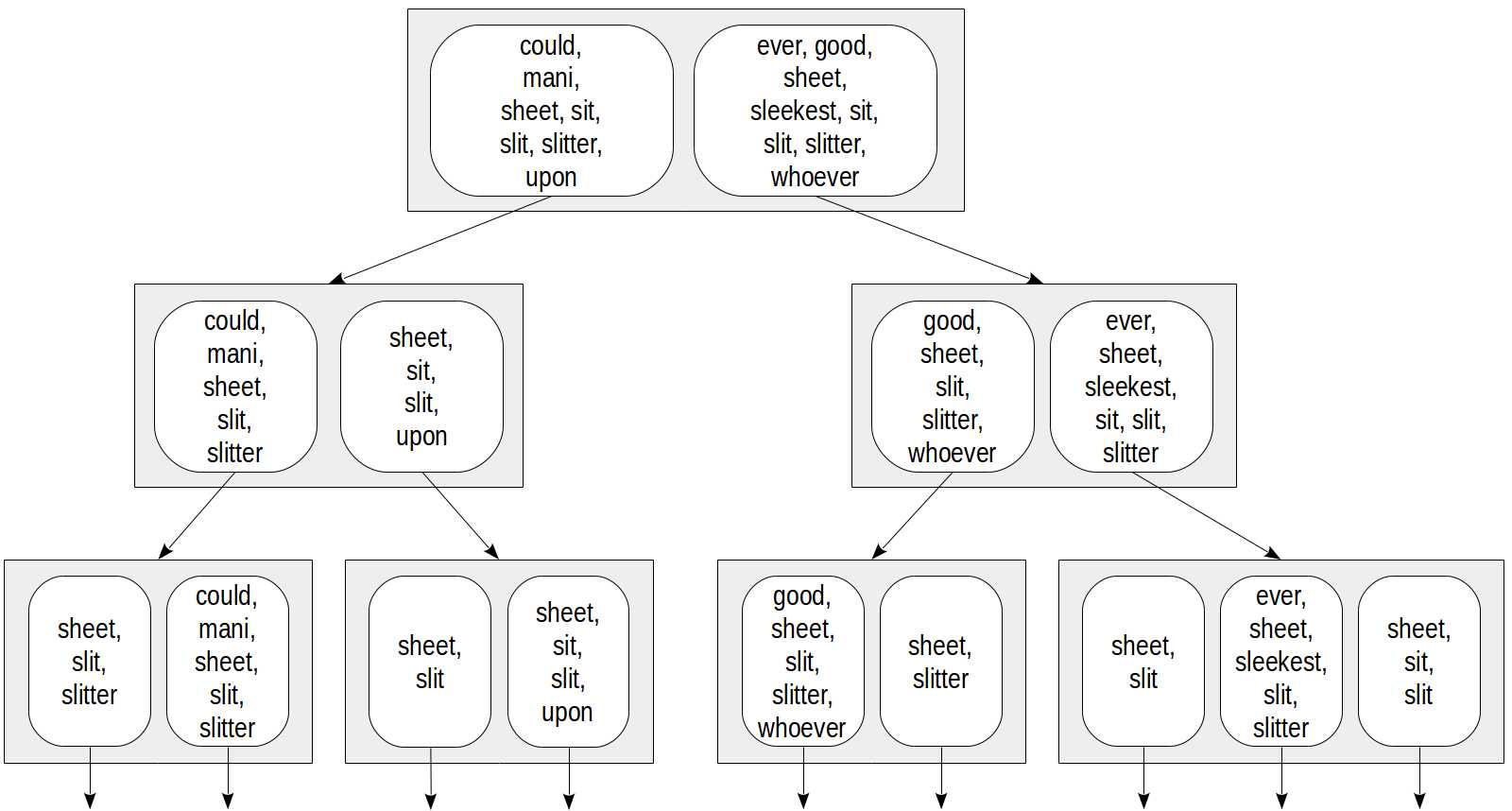
然后,例如,对于通过条件doc_tsv @@ to_tsquery(‘sit‘)访问,我们只能下降到那些包含«sit»词素的节点:
这种表述有明显的问题。文档中lexemes的数量可能非常大,因此索引行将具有较大的大小并进入TOAST,从而大大降低了索引的效率。即使每个文档只有很少的唯一lexemes,集合的并集仍然可能非常大:根的值越高,索引行越大。
有时会使用这样的表示,但用于其他数据类型。全文搜索使用另一种更紧凑的解决方案——所谓的签名树。它的想法对所有使用过Bloom filter的人来说都很熟悉。
每个词素可以用它的签名表示:一个特定长度的bit串,其中除一个bit之外的所有位都为零。此bit的位置由词位的哈希函数的值决定(我们前面讨论了哈希函数的内部内容)。
文档签名是所有文档词典的按位或签名。
假设词汇的签名如下:
could 1000000 ever 0001000 good 0000010 mani 0000100 sheet 0000100 sleekest 0100000 sit 0010000 slit 0001000 slitter 0000001 upon 0000010 whoever 0010000
文档的签名如下:
Can a sheet slitter slit sheets? 0001101 How many sheets could a sheet slitter slit? 1001101 I slit a sheet, a sheet I slit. 0001100 Upon a slitted sheet I sit. 0011110 Whoever slit the sheets is a good sheet slitter. 0011111 I am a sheet slitter. 0000101 I slit sheets. 0001100 I am the sleekest sheet slitter that ever slit sheets. 0101101 She slits the sheet she sits on. 0011100
索引树可以表示为:
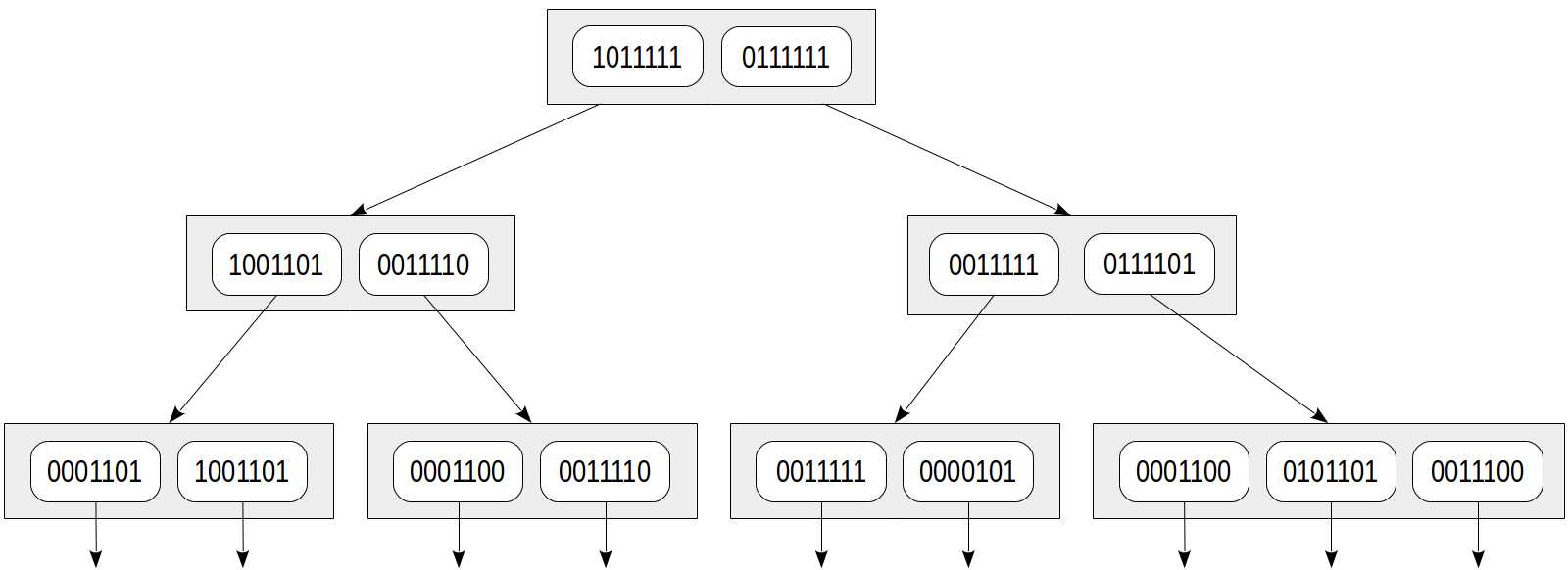
这种方法的优点是显而易见的:索引行大小相同,而且这样的索引很紧凑。但它也有一个明显的缺点:为了紧凑性,牺牲了准确性。
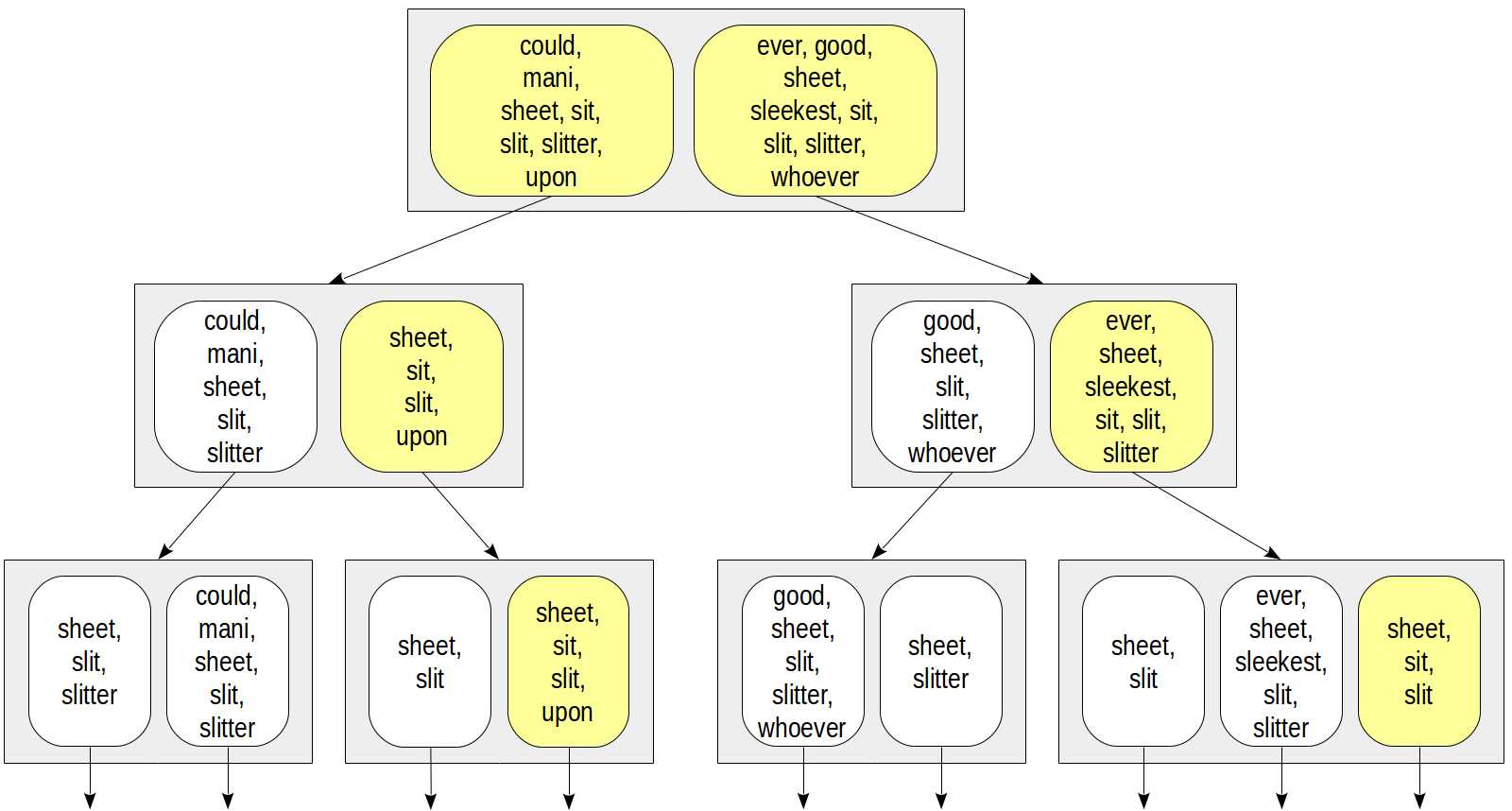
让我们考虑相同的条件doc_tsv @@ to_tsquery(‘sit‘)。让我们以与文档相同的方式计算搜索查询的签名:在本例中为0010000。一致性函数必须返回所有其签名至少包含查询签名中的一位的子节点:
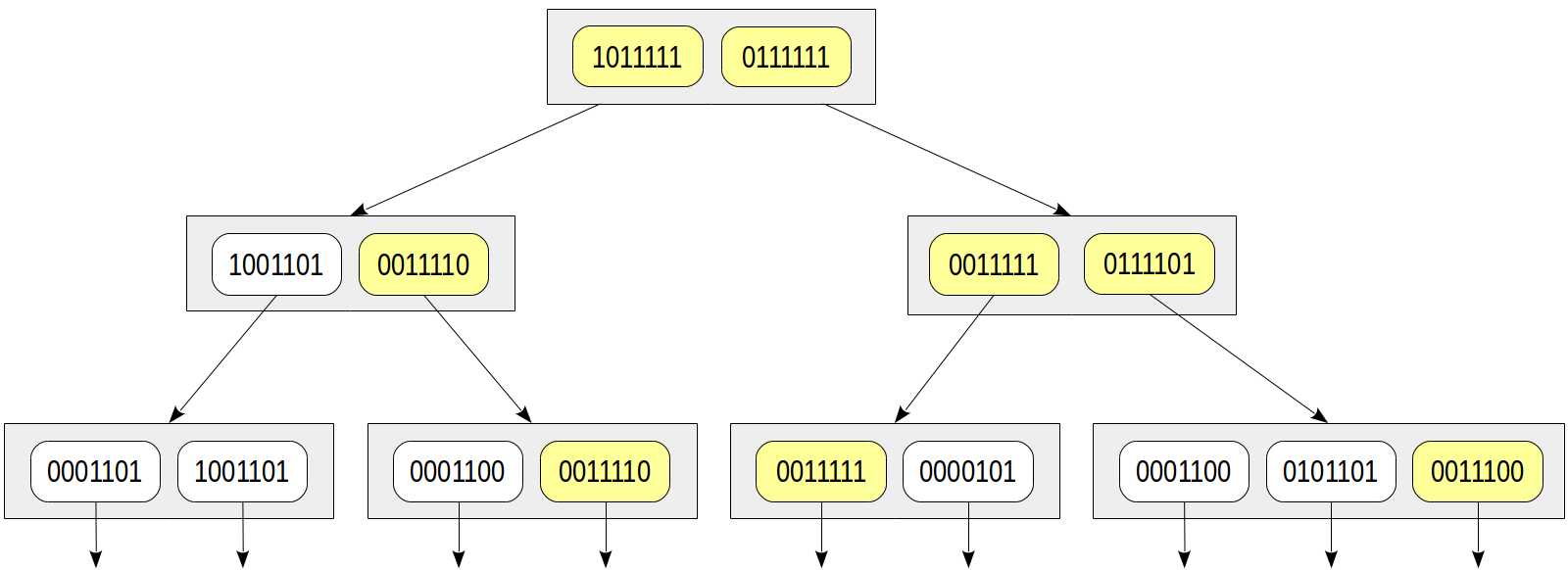
与上图相比较:我们可以看到树变成了黄色,这意味着在搜索过程中出现了误报和过多的节点。在这里,我们选择了«whoever»词汇素,不幸的是,它的签名与«sit»词汇素的签名相同。重要的是在模式中不能出现错误的否定,也就是说,我们肯定不会错过需要的值。
此外,不同的文档也可能会得到相同的签名:在我们的例子中,文档«I slit a sheet, a sheet I slit»、«I slit sheets»(两者的签名都是0001100)。如果叶索引行没有存储«tsvector»的值,索引本身将给出false positives。当然,在这种情况下,该方法将要求索引引擎用表重新检查结果,这样用户就不会看到这些误报。但搜索效率可能会受到影响。
实际上,签名在当前实现中是124个bytes大,而在图中是7bit,因此上述问题比示例中出现的可能性要小得多。但实际上,还有更多的文档被编入了索引。想办法减少false positives的数量的实现变得有点棘手:«tsvector»索引存储在一片叶子索引行,但前提是其规模不大(略小于1/16的一个页面,这是大约一半的千字节8 kb页面)。
示例
为了了解索引是如何在实际数据上工作的,让我们以«pgsql-hacker»电子邮件的归档为例。示例中使用的版本包含356125条消息,其中包含发送日期、主题、作者和文本:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------
id | 1572389
parent_id | 1562808
sent | 1997-06-24 11:31:09
subject | Re: [HACKERS] Array bug is still there....
author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov>
body_plain | Andrew Martin wrote: +
| > Just run the regression tests on 6.1 and as I suspected the array bug +
| > is still there. The regression test passes because the expected output+
| > has been fixed to the *wrong* output. +
| +
| OK, I think I understand the current array behavior, which is apparently+
| different than the behavior for v1.0x. +
...
添加和填充«tsvector»类型的列并构建索引。在这里,我们将在一个矢量中连接三个值(subject, author, 和 message text),以表明文档不需要是一个字段,可以由完全不同的任意部分组成。
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(subject||‘ ‘||author||‘ ‘||body_plain); NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125 fts=# create index on mail_messages using gist(tsv);
正如我们所看到的,一定数量的单词因为太大而被删除。但是最终创建的索引可以支持搜索查询:
fts=# explain (analyze, costs off)
select * from mail_messages where tsv @@ to_tsquery(‘magic & value‘);
QUERY PLAN
----------------------------------------------------------
Index Scan using mail_messages_tsv_idx on mail_messages
(actual time=0.998..416.335 rows=898 loops=1)
Index Cond: (tsv @@ to_tsquery(‘magic & value‘::text))
Rows Removed by Index Recheck: 7859
Planning time: 0.203 ms
Execution time: 416.492 ms
(5 rows)
我们可以看到,在898行匹配条件的情况下,access方法返回7859多行,这些行是通过重新检查表过滤掉的。这说明了准确性的损失对效率的负面影响。
内部原理
为了分析索引的内容,我们将再次使用«gevel»扩展:
fts=# select level, a
from gist_print(‘mail_messages_tsv_idx‘) as t(level int, valid bool, a gtsvector)
where a is not null;
level | a
-------+-------------------------------
1 | 992 true bits, 0 false bits
2 | 988 true bits, 4 false bits
3 | 573 true bits, 419 false bits
4 | 65 unique words
4 | 107 unique words
4 | 64 unique words
4 | 42 unique words
...
存储在索引行中的特殊类型«gtsvector»的值实际上是签名加上源«tsvector»。如果向量可用,输出将包含词素(唯一单词)的数量,否则将包含签名中的true或false位数。
很明显,在根节点中,签名退化为«all ones»,也就是说,一个索引级别变得毫无用处(还有一个几乎毫无用处,只有四个false bits)。
属性
让我们看看GiST访问方法的属性(查询已经在前面提供):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) postgres-# from pg_am a, postgres-# unnest(array[‘can_order‘,‘can_unique‘,‘can_multi_col‘,‘can_exclude‘]) p(name) postgres-# where a.amname = ‘gist‘ postgres-# order by a.amname; amname | name | pg_indexam_has_property --------+---------------+------------------------- gist | can_order | f gist | can_unique | f gist | can_multi_col | t gist | can_exclude | t (4 rows) postgres=#
不支持值排序和惟一约束。正如我们所看到的,索引可以建立在几个列上,并在排除约束中使用。
以下索引层属性可用:
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | f
最有趣的属性是列层。一些属性独立于操作符类:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f search_array | f search_nulls | t
(不支持排序;索引不能用于搜索数组;支持null)。
但是剩下的两个属性«distance_orderable»和«returnable»将取决于所使用的操作符类。例如,对于points,我们将得到:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | t returnable | t
第一个属性表示距离操作符可用于搜索最近的邻居点。第二个说明该索引可以用于仅索引扫描。尽管叶子索引行存储的是矩形而不是点,但是access方法可以返回所需的内容。
以下是interval的属性:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | t
对于interval,距离函数没有定义,因此,搜索最近的邻居点是不可能的。
对于全文搜索,我们得到:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | f
由于叶子行只能包含签名而不包含数据本身,因此已经失去了对仅索引扫描的支持。然而,这只是一个小小的损失,因为没有人对type«tsvector»的值感兴趣:这个值用于选择行,而需要显示的是源文本,但无论如何索引中都没有。
其他数据类型
最后,除了已经讨论过的几何类型(通过点的例子)、间隔和全文搜索类型之外,我们还将提到目前由GiST访问方法支持的其他一些类型。
在标准类型中,这是ip地址的类型“inet”。其余的都是通过扩展添加的:
·cube为多维数据集提供«cube»数据类型。对于这种类型,就像对于平面中的几何类型一样,定义了GiST操作符类:R-tree,支持搜索最近邻。
·seg为带有边界的interval提供«seg»数据类型,并为该数据类型(R-tree)添加了对GiST索引的支持。
·intarray扩展了整数数组的功能,并为它们添加了GiST支持。实现了两个操作符类:«gist_int_ops»(RD-tree,具有索引行中键的完整表示)和«gist_bigint_ops»(签名RD-tree)。第一个类可用于小数组,第二个类可用于大数组。
·ltree为树状结构添加了«ltree»数据类型,并为该数据类型(RD-tree)提供了GiST支持。
·pg_trgm添加了一个专门的操作符类«gist_trgm_ops»,用于在全文搜索中使用三元组合。但这将与GIN索引一起进一步讨论。
原文地址:https://habr.com/en/company/postgrespro/blog/444742/
标签:特性 数据库 postgres lte rom record sel 有趣 之一
原文地址:https://www.cnblogs.com/abclife/p/13446943.html