标签:原创文章 写法 也会 long 成都 工程 关于 需要 splay
每周至少一篇原创技术文章今天咱们要讨论的树,它不是现实结构的树,也不是数据结构要讨论的树,而是「从业务视角抽象出来的树形结构」。
树形结构可以用在很多的业务上,比如组织结构中的上下级关系、商品分类管理、文件系统、后台系统中的页面和组件关系等等。
下面请系好安全带,我们将从数据库设计、设计模式、前端组件三个方面来介绍关于树状结构设计的方方面面,助你通关全栈树状结构!
树状结构最简单最常用的方法其实是直接存储在JSON里面。现在有很多主流的NoSQL库,比如MongoDB等,而且也有很多关系型数据库也开始支持JSON存储,比如MySQL。
使用JSON的好处是,「维护整棵树比较方便」,直接整存整取就好了,不用去管中间是怎么修改的,怎么映射到数据库的。但缺点是不太高效,比如想要编辑某个叶子节点,查询和更新都没有纯关系型数据那么方便。所以如果你的业务足够简单,数据量也很小,可以使用JSON。否则,还是推荐使用关系型数据来实现。
那如何在关系型数据应该如何设计,才能高效地存储和操作树形结构呢?我们用下图来作为例子:
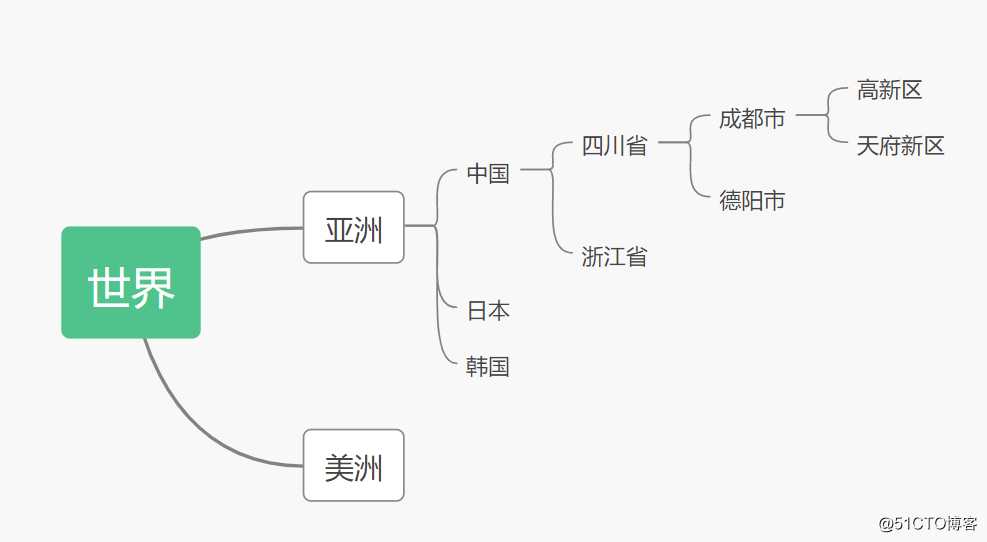
区域关系
?
ps:这里假设有多棵树,根节点是亚洲、美洲等
?
我们首先想到的是用parent_id, 这个字段用来存储“父节点”,根节点的parent_id为0,这样就可以通过递归查询得到一棵树。
很明显,如果只是一个parent_id,我们如果想获得一棵树,当这棵树的深度比较深时,我们需要查询很多次数据库,效率非常低。那有没有什么办法可以一次性把整棵树都查出来呢?我们尝试加一个root_id,用来表示这棵树的根节点。
id parent_id root_id name
1 0 0 亚洲
2 0 0 美洲
3 1 1 中国
4 1 1 日本
5 1 1 韩国
6 3 1 四川省那么问题来了,如果是想查询某一个节点的子树,该怎么做呢?是不是觉得不太方便?下面我们推荐另外一种表示方式:「full id path」,每个节点记录下从根节点到自己的id路径,如下:
id full_id_path name
1 /1 亚洲
2 /2 美洲
3 /1/3 中国
4 /1/4 日本
5 /1/5 韩国
6 /1/3/6 四川省
7 /1/3/6/7 成都市这样如果我们想查询一棵树,只需要使用like语句前缀匹配就行了。比如想查询“四川省”下面有哪些市:
SELECT * FROM table
WHERE full_id_path like "/1/3/6%";如果是更新了一棵树中节点的关系,只需要维护好这个节点及其子节点的full_id_path字段就行了。一般来讲,这种full id path设计能够满足绝大多数树形结构的业务要求。
但如果你的id是「UUID」类型的,如果深度比较高,那full_id_path字段就会比较长,且并不易读。这个时候我们建议使用一个唯一的,有业务意义的code来表示路径,字段名改为叫full_path。比如要表示成都市:
‘/Asian/China/SiChuan/Chengdu‘数据库的设计还是要根据业务来,没有绝对的银弹。有时候,我们会加上level字段表示每个节点在树中的层级位置,用于「在应用代码层面更方便、高效地拼接树」。
接下来我们介绍在代码层面,如何去优雅地使用树形结构。其实前辈们已经为我们总结出了一种非常优秀的设计模式——组合模式,又称为“部分整体模式”,专门针对树形结构。
组合模式的精髓在于,你不用把一棵树“树”的概念和一个单独的“节点”分开处理,而是都视为同一种对象来处理。下面我们依然以上面的区域关系为例,来介绍组合模式如何使用。
首先我们来看一个经典的组合模式中的三个概念:
下面上Java代码实现:
/**
* 组合模式抽象接口
*/
public interface LocationComponent {
String getPath();
void display();
void add(LocationComponent component);
void remove(LocationComponent component);
Map<String, LocationComponent> getChildren();
}/**
* 容器对象,表示有孩子的节点
*/
public class LocationComposite implements LocationComponent {
private Long id;
private String name;
private String fullPath;
private Map<String, LocationComponent> children = new HashMap<>();
@Override
public String getPath() {
return fullPath;
}
@Override
public void display() {
System.out.println(name);
}
@Override
public void add(LocationComponent component) {
component.fullPath = this.fullPath + "/" + component.id;
children.put(component.getPath(), component);
}
@Override
public void remove(LocationComponent component) {
children.remove(component.getPath());
}
@Override
public Map<String, LocationComponent> getChildren() {
return children;
}
}/**
* 叶子节点
*/
public class LocationLeaf implements LocationComponent {
private Long id;
private String name;
private String fullPath;
@Override
public String getPath() {
return fullPath;
}
@Override
public void display() {
System.out.println(name);
}
@Override
public void add(LocationComponent component) {
throw new UnsupportedOperationException();
}
@Override
public void remove(LocationComponent component) {
throw new UnsupportedOperationException();
}
@Override
public Map<String, LocationComponent> getChildren() {
throw new UnsupportedOperationException();
}
}那么问题来了,我有必要把节点分成Leaf和Composite吗?Leaf也实现Component接口,但抛那么多UnsupportedOperationException意义何在?我为什么不用同一个对象来表示Composite和Leaf?
其实从这里我们就可以看到,经典的设计模式也不是银弹。「我们学设计模式,学的是思想,而不是固定的套路,最终还是要结合业务」。比如上面的代码,明显就不适合我们的“区域”业务,比如我想在高新区下面再细分“街道”,这个代码就很难扩展了。
但如果你的业务是做一个「文件系统」,我们可以很明显的知道,文件和文件夹的区别。文件就是一个Leaf,它必然不支持add、remove、getChildren等操作,而文件夹是必须有这些操作的,是一个Composite。这个时候就可以用上面的代码设计了。同时,上面的Map也可以换成List等其它容器类型。
所以我们要活学活用,针对我们的区域业务,可以直接用一个Component来表示:
/**
* 区域接口,可扩展成无限深度
*/
public class AreaComponent {
private Long id;
private String name;
private String fullPath;
private Map<String, AreaComponent> children = new HashMap<>();
public String getPath() {
return fullPath;
}
public void display() {
System.out.println(name);
}
public void add(AreaComponent component) {
component.fullPath = this.fullPath + "/" + component.id;
children.put(component.getPath(), component);
}
public void remove(AreaComponent component) {
children.remove(component.getPath());
}
public Map<String, AreaComponent> getChildren() {
return children;
}
}作为一个有志向的全栈工程师,当然不能只满足于数据库和后端层面。前端组件代码也要自己上手~
相信现在的前端小伙伴们都应该熟悉一种或多种令人闻风丧胆的“三大”前端主流框架。现在的前端框架都推荐“组件化”开发,把页面分成一个一个小的组件。很明显,组件层层嵌套,其实本质上也是一个树的形式,最终也会渲染出一个DOM树对象。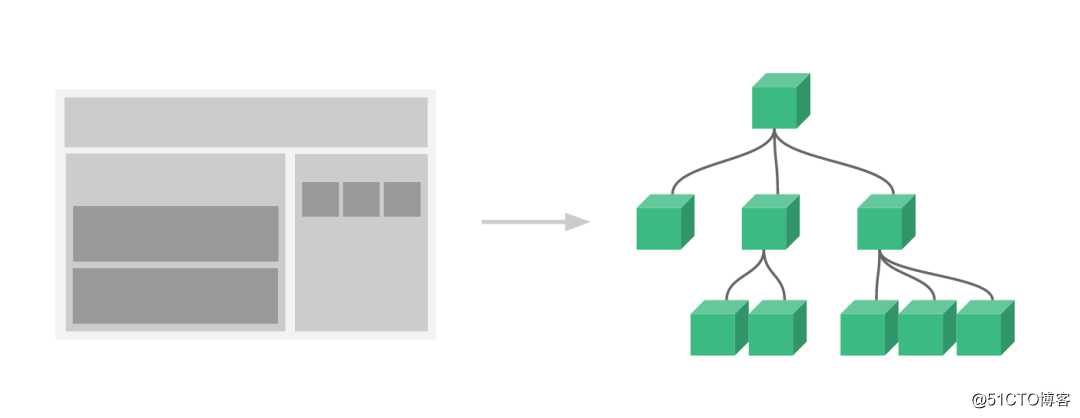
组件树
我们以Vue为例,对于上文提到的区域划分业务,如果后端返回的是一条条带有full_path的扁平数据,前端应该如何优雅地构建基于业务的树形结构呢?答案就是使用「递归组件」。
递归组件,简单来说就是「在组件中内使用组件本身」, 对于Vue来说,其核心就在于使用name字段。效果大概是这样:

请忽略我的审美
还是按照惯例,上代码。先来一个表示“区域”的组件:
<template>
<div class="node" :style="{paddingLeft: self.level * 20 + ‘px‘}">
<p>{{self.name}}</p>
<div v-for="child in children" :key="child.id">
<Area v-if="`children.length != 0`" :self="child" :all="all"/>
</div>
</div>
</template>
<script>
export default {
name: ‘Area‘,
props: {
self: Object,
all: Array
},
computed: {
children() {
// 根据full_path和level,过滤出子组件
return this.all.filter(item => item.full_path.startsWith(this.self.full_path) && item.level == this.self.level + 1);
}
}
}
</script>入口:
<template>
<div id="app">
<Area :self="all[0]" :all="all" />
</div>
</template>
<script>
import Area from ‘./components/Area.vue‘
export default {
name: ‘App‘,
components: {
Area
},
data() {
return {
// 所有数据
all: [
{ id: 1, level: 1, full_path: ‘/1‘, name: ‘亚洲‘ },
{ id: 2, level: 1, full_path: ‘/2‘, name: ‘美洲‘ },
{ id: 3, level: 2, full_path: ‘/1/3‘, name: ‘中国‘ },
{ id: 4, level: 2, full_path: ‘/1/4‘, name: ‘日本‘ },
{ id: 5, level: 3, full_path: ‘/1/3/5‘, name: ‘四川省‘ },
{ id: 6, level: 3, full_path: ‘/1/3/6‘, name: ‘浙江省‘ },
{ id: 7, level: 4, full_path: ‘/1/3/5/7‘, name: ‘成都市‘ }
]
}
}
}
</script>当然了,这只是其中一种写法,你也可以在外面组装好一个带children的对象传进去。
又到了我们一天一度的前后端撕逼环节。作为一个假装是全栈的后端同学来说,笔者认为针对这个问题,我有必要说一句公道话:在前端组装比较好。
众所周知,在当今前端越来越繁荣的大环境下,前端承担着越来越重要的角色,有很多数据的计算也会放在前端。针对于这种树状结构的拼装来说,放在前后端其实都可以的。但是放在前端有一个好处,那就是「可以将计算消耗的时间和资源从服务端转移到客户端」。
现在的后端架构也越来越倾向于读写分离,所以在读的时候,多半不会进行太多的操作,不需要组装整棵树。这种情况下,建议直接把数据返回前端,由前端来组装成整棵树。
当然,这只是一个建议,具体在什么时机组装,还是由业务规则以及团队商量决定~
好了,以上就是从数据库到前端的树形结构实现,有任何问题欢迎留言讨论~
都看到这里了,说明你认可我的文章。
如果对你有帮助,不妨支持我一下:
你的一个小小的阅读、关注、留言、转发、在看,
都是我写作路上最大的鼓励。
猛戳下面那个二维码关注:

标签:原创文章 写法 也会 long 成都 工程 关于 需要 splay
原文地址:https://blog.51cto.com/14890694/2518871