标签:grep -n art 链接 计算 主机 全局替换 dig pre 自定义
10 文本处理工具和正则表达式文本编辑种类
? ? 全屏编辑器:nano (字符工具),gedit(图形化工具),vi,vim
? ? 行编辑器: sed
#进入一个练习文档或者vim自带的练习册vimtutor
[root@centos82s ~]$vimtutor
===============================================================================
= W e l c o m e t o t h e V I M T u t o r - Version 1.7 =
===============================================================================
Vim is a very powerful editor that has many commands, too many to
explain in a tutor such as this. This tutor is designed to describe
enough of the commands that you will be able to easily use Vim as
an all-purpose editor.
#练习开始,用vim进入文档是命令模式
i 按i键进入插入模式,即可编辑,按Esc回到命令模式
:wq 保存退出(:w 保存,:q 退出)
:w 保存不退出
:q 退出
:q! 不保存,退出
:!command 执行命令
:r!command 读入命令的输出
:w!command 将当前文件内容写入到另一个文件
#光标移动
hjkl 左下上右移动光标,同↑↓←→
w,b 以单词词首为单位移动光标
e 以单词词尾为单位移动光标
0,^ 以行为单位,移动光标至行首
$ 一行为单位,移动光标至行尾
gg 以文章行号为单位,移动光标到第一行
G 以文章行号为单位;num+G:移动光标到num行
H 以当前屏幕为单位,移动光标到第一行
M 以当前屏幕为单位,移动光标到中间
L 以当前屏幕为单位,移动光标到最后一行
( 以句子为单位,移动光标到上一句
) 以句子为单位,移动光标到下一句
{ 以段落为单位,移动光标到上一段落
} 以段落为单位,移动光标到下一段落
Ctrl+f 以当前屏幕为单位,下移一屏幕
Ctrl+b 以当前屏幕为单位,上移一屏幕
Ctrl+d 以当前屏幕为单位,下移半屏幕
Ctrl+u 以当前屏幕为单位,上移半屏幕
#复制
y$ 复制当前光标到行尾的所有字符
y0 复制当前光标到行首的所有字符
y^ 复制当前光标到非空行的行首
ye 复制当前光标到单词的词尾
yw 复制当前光标到单词的词尾
yb 复制光标之前的所有字符,除光标位置的字符
yy 复制当前光标所在行所有内容
Y 复制当前光标所在行所有内容,不含换行符
#删除
x 删除当前光标所在的一个字符
dd 删除当前行,并把删除的行保存到剪切板
db 删除光标之前的所有字符,除光标位置的字符,并把删除的行保存到剪切板(cb功能一样)
c$ 删除当前光标到行尾的所有内容,进入插入模式
c^ 删除当前光标到非空行首的所有内容,进入插入模式
c0 删除当前光标到行首的所有内容,进入插入模式
ce 删除当前光标到词尾的内容,进入插入模式
cw 删除当前光标到词尾的内容,进入插入模式
cc 删除当前光标所在行;num+cc:删除num行;进入插入模式
C 删除当前光标到行尾的所有内容,进入插入模式
#插入
a 进入插入模式并在光标后插入数据
o 进入插入模式并在当前行下面插入一个新行(小o)
O 进入插入模式并在当前行上面插入一个新行(大O)
#粘贴
p 粘贴剪切板内容,和dd键、yy键配合使用
#撤销更改
u 撤销最近的修改
num+u 撤销之前num次的修改
U 撤销光标落在此行后的所有修改
Ctrl+r 撤销之前的撤销,相对于Windows中Ctrl+y
num. 重复前一个操作num次
#高级用法
0y$ 复制行首到行尾
10iroot 粘贴10次root,按Esc退出
di" 光标在符号之间,删除符号之间的内容,注意符号成对,如""
yi" 光标在符号之间,复制符号之间内容,注意符号成对,如""
vi" 光标在符号之间,选中符号之间内容,注意符号成对,如""
dt+x 删除字符直至遇到第一个x字符,x可为其它
yt+x 复制字符直至遇到第一个x字符,x可为其它#格式::start_pos,end_pos CMD
num 光标定位到num行
num,num1 从num行到num1行
num,+num1 从num行到num+num1行
. 当前行
$ 最后一行
.,$-1 当前行到倒数第二行
% 全文,相对于1,$
#匹配到后续操作才有效
/param/ 匹配param值
/param/,/param1/ 匹配param值到param1值结束
num,/param/ 从num行开始,匹配到param值结束
/param/,$ 从匹配到param开始到最后一行#格式:s/param/param1/修饰符
i 忽略大小写
g 全局替换
gc 全局替换,每次替换前询问
若出现/param,可以使用@,#代替/,比如s#/etc#param#g查找参数明明存在,若出现下图情况使用: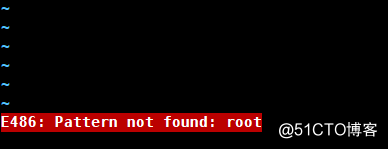
? 扩展命令模式的配置只对当前vim进程有效,可将配置存放在文件永久保存
#配置文件
/etc/vimrc 全局
~/.vimrc 个人
#行号
启用:set number,简写:set nu
关闭:set nonumber,简写:set nonu
#忽略字符大小写
启用:set ignorecase,简写:set ic
关闭:set noignorecase,简写set noic
#自动缩进
启用:set autoindent,简写:set ai
关闭:set noautoindent,简写:set noai
#复制保留格式
启用:set paste
关闭:set nopaste
#显示Tab和换行符(^I和$)
启用:set list
关闭:set nolist
#高亮搜索
启用:set hlsearch
关闭:set nohlsearch 简写:set nohl
#语法高亮
启用:syntax on
关闭:syntax off
#文件格式
启用Windows格式: set fileformat=dos
启用Unix格式: set fileformat=unix
简写: set ff=dos|unix
#tab 用空格代替
启用:set expandtab 默认为8个空格
禁用:set noexpandtab 简写:set et
#设置tab空格个数
启用:set tabstop=num num空格个数
简写:set ts=4
#设置文本宽度
启用:set textwidth=80 简写:set tw=80
#设置光标所在行的标示线
启用:set cursorline, 简写:set cul
关闭:set nocursorline
#加密
启用:set key=password 禁用:set key=
#set帮助
:help option-list
:set or :set all? 在末行有“-- VISUAL ...-- ”指示,表示可视化模式
? 允许选择的文本块
? ? v 面向字符,-- VISUAL --
? ? V 面向整行,-- VISUAL LINE --
? ? Ctrl+v 面向块,-- VISUAL BLOCK --
? 可视化可结合箭头,h,j,k,l等使用。选中的文字可被删除,复制,修改,过来,搜索,替换等
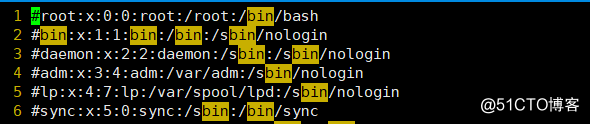
? 如下所示,在每行行首插入#字符
? 1、先将光标移到第一行行首
? 2、按Ctrl+v键,进入可视化模式
? 3、输入G键到最后一行
? 4、输入I到插入模式
? 5、输入#
? 6、按Esc键退出插入模式,完成
? 如下所示,在指定块位置插入相同内容
? 1、光标定位到要操作的位置
? 2、Ctrl+v,进入可视化模式
? 3、按I键,进入插入模式
? 4、输入@
? 5、按Esc键退出,完成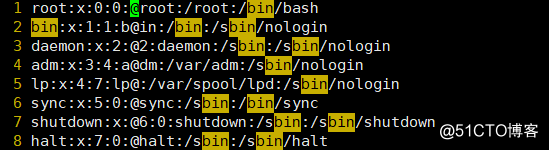
#vim file1 file2 file3 或 vim file[1-3]
:next 切换到下一个文件
:prev 切换到上一个文件
:first 切换到第一个文件
:last 切换到最后一个文件
:wall 保存所有
:qall 不保存退出所有
:wqall 保存退出所有? vim -o|-O file1 file2
? -o: 上下分割
? -O: 左右分割
? 窗口切换:Ctrl+w
? 10.4.1 单文件窗口分割
? Ctrl+w,s 水平分割,上下分屏
? Ctrl+w,v 垂直分割,左右分屏
? Ctrl+w,q 取消相邻窗口
? Ctrl+w,o 取消全部分屏窗口
? :wqall 退出
? vim有26个命名寄存器和1个无命名寄存器,存放不同的剪切板内容,可以在同一个主机的不同会话(终端窗口)间共享
? 寄存器名称a..z格式 格式:"寄存器+命令 ,放在数字和命令之间
? 寄存器的主要功能就是缓存操作过程中删除、复制、搜索等的文本内容
? ma 将当前位置标记为a,26个字母均可做标记,mb、mc等等
? ‘a 跳转到a标记的位置,实用的文档内标记方法,文档中跳跃编辑时很有用
? qa 录制宏a,a为宏的名称,末行提示:recording @a
? q 停止录制宏
? @a 执行宏a
? @@ 重新执行上次执行的宏
#以二进制方式打开文件
vim -b file
#扩展命令模式下,利用xxd命令转换为可读的十六进制
:%!xxd
#切换至插入模式,编辑二进制文件
#切换至扩展命令模式下,利用xxd命令转换回二进制
:%!xxd -r
#保存退出? 命令常用选项
? ? -E 显示行结束符$
? ? -A 显示所有控制符
? ? -n 对显示出的行编号
? ? -b 对非空行编号
? ? -s 压缩连续的空行成一行
#-E
[root@centos82s data]$cat -E f1.txt
1$
$
2$
3$
#-A
[root@centos82s data]$cat -A f1.txt
1$
^I$
2$
3$
#-n
[root@centos82s data]$cat -n f1.txt
1 1
2
3 2
4 3
5 4
6 5
#-b
[root@centos82s data]$cat -b f1.txt
1 1
2 此行存在tab字符,所以不为空
3 2
4 3
5 4
6 5
7 6
#-s
[root@centos82s data]$cat -s f1.txt
1
2
3
4
5
6#逆向显示文本内容
[root@centos82s data]$tac f1.txt
9
8
6
5
4
3
2
1
[root@centos82s data]$tac
a
b
c
d 按Ctrl+d
d
c
b
a
[root@centos82s data]$seq 5
1
2
3
4
5
[root@centos82s data]$seq 5|tac
5
4
3
2
1? 显示行号,相对于cat -b
[root@centos82s data]$nl f1.txt
1 1
2
3 2
4 3
5 4
6 5
7 6? 将同一行的内容逆向显示
[root@centos82s data]$cat f2.txt
1 2 3 4 5
a b c
[root@centos82s data]$rev f2.txt
5 4 3 2 1
c b a
#手动输入,按enter键,逆向显示
[root@centos82s data]$rev
1 2 3 4 5 6
6 5 4 3 2 1
[root@centos82s data]$echo {1..5}
1 2 3 4 5
[root@centos82s data]$echo {1..5}|rev
5 4 3 2 1[root@centos82s data]$hexdump -C -n 512 sda
00000000 eb 63 90 10 8e d0 bc 00 b0 b8 00 00 8e d8 8e c0 |.c..............|
[root@centos82s data]$echo {a..z}|tr -d ‘ ‘|hexdump -C
00000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 |abcdefghijklmnop|
00000010 71 72 73 74 75 76 77 78 79 7a 0a |qrstuvwxyz.|
0000001b
? od即dump files in octal and other formats(转储文件的八进制和其他格式)
#十六进制
[root@centos82s data]$echo {a..z}|tr -d ‘ ‘|od -t x
0000000 64636261 68676665 6c6b6a69 706f6e6d
0000020 74737271 78777675 000a7a79
0000033
[root@centos82s data]$echo {a..z}|tr -d ‘ ‘|od -t x1
0000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70
0000020 71 72 73 74 75 76 77 78 79 7a 0a
0000033
[root@centos82s data]$echo {a..z}|tr -d ‘ ‘|od -t x1z
0000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 >abcdefghijklmnop<
0000020 71 72 73 74 75 76 77 78 79 7a 0a >qrstuvwxyz.<
0000033
[root@centos82s data]$echo {a..z}|tr -d ‘ ‘|xxd
00000000: 6162 6364 6566 6768 696a 6b6c 6d6e 6f70 abcdefghijklmnop
00000010: 7172 7374 7576 7778 797a 0a qrstuvwxyz.? 可以实现分页查看文件,可以配合管道实现输出信息的分页
? 常用快捷键
? ? enter 文件下移一行
? ? space 文件下翻一页
? ? b 文件上翻一页
? 当下移到最后一行时,将退出more命令,如果想查看前面内容,只能重新执行一遍more命令
[root@centos82s data]$more /etc/init.d/functions? 基本功能和more类似
? 常用快捷键
? ? ↑↓ 上移和下移一行
? ? enter 文件下移一行
? ? space 文件下翻一页
? ? b 文件上翻一页
? ? g 光标定位到文件开始
? ? G 光标定位到文件最后
? ? /param 搜索匹配param的字符串
? ? n/N 跳到下一个或上一个匹配
#分页显示 /etc下的文件列表
[root@centos82s ~]$ls -R /etc/|more
/etc/:
adjtime
aliases
alternatives
anacrontab
audit
authselect
bash_completion.d
....
#分页显示系统启动信息
[root@centos82s ~]$dmesg|less
[ 0.000000] Linux version 4.18.0-193.el8.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC)) #1 SMP Fri May 8 10:59:10 UTC 2020
[ 0.000000] Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-193.el8.x86_64 root=UUID=5e437624-9610-4d5d-804b-ec9054e9f46d ro crashkernel=auto resume=UUID=9c230f26-8349-4153-b1d6-742a6a7b7088 rhgb quiet
....? 可以显示文件或标准输入的前面行
? 常用命令选项
? ? -c num 指定获取前num字节
? ? -n num 指定获取前num行
? ? -num 同上
#默认获取文件前10行
[root@centos82s data]$head passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
#指定获取文件前10个字符
[root@centos82s data]$head -c 10 passwd
root:x:0:0
#指定获取文件前5行
[root@centos82s data]$head -n 5 passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
#显示第一行到倒数第八行的内容
[root@centos82s data]$seq 10|head -n -8
1
2? tail和head相反,可以显示文件或标准输入的倒数行
? 常用命令选项
? ? -c num 指定获取后num字节
? ? -n num 指定获取后num行
? ? -num 同上
? ? -f 跟踪显示文件fd新追加的内容,常用日志监控,相对于--follow=descriptor,当文件删 除再新建同名文件,将无法进行跟踪文件
? ? -F 跟踪文件名,相对于--follow=name --retry,当文件删除再新建同名文件,将可以继 续跟踪文件
? ? tailf 类似tail -f,当文件不增长时并不访问文件
? ? -fn0/-0f -Fn0/-0F 只查看最新发生的日志
#默认获取文件后10行
[root@centos82s data]$tail passwd
polkitd:x:998:996:User for polkitd:/:/sbin/nologin
unbound:x:997:995:Unbound DNS resolver:/etc/unbound:/sbin/nologin
sssd:x:996:993:User for sssd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
rngd:x:995:992:Random Number Generator Daemon:/var/lib/rngd:/sbin/nologin
dou:x:1000:1000:dou:/home/dou:/bin/bash
apache:x:48:48:Apache:/var/www:/sbin/nologin
admins:x:1001:1001::/home/admins:/bin/bash
honghong:x:1002:1002::/home/honghong:/bin/bash
lanlan:x:1003:1003::/home/lanlan:/bin/bash
#指定获取文件后5行内容
[root@centos82s data]$tail -n 5 passwd
dou:x:1000:1000:dou:/home/dou:/bin/bash
apache:x:48:48:Apache:/var/www:/sbin/nologin
admins:x:1001:1001::/home/admins:/bin/bash
honghong:x:1002:1002::/home/honghong:/bin/bash
lanlan:x:1003:1003::/home/lanlan:/bin/bash
#指定获取文件后5个字节
[root@centos82s data]$tail -c 5 passwd
bash
#特殊用法
[root@centos82s data]$seq 10|tail -n 5
6
7
8
9
10
#显示倒数第一行到倒数第八行的内容
[root@centos82s data]$seq 10|tail -n -8
3
4
5
6
7
8
9
10
#新建ping.log文件,打开一个终端执行下面的命令,将返回结果重定向到ping.log
[root@centos82s data]$touch ping.log
[root@centos82s data]$echo hello >> ping.log
#在打开一个终端,使用命令tail -f ping.log查看,tail程序会持续地显示出ping.log文件后续增加的内容
[root@centos82s data]$tail -fn0 ping.log
hell
hello
#把文件删除,重新创建ping.log,再使用tail命令追踪,
[root@centos82s data]$rm -rf ping.log
[root@centos82s data]$tail -f ping.log
tail: cannot open ‘ping.log‘ for reading: No such file or directory
tail: no files remaining
[root@centos82s data]$touch ping.log
#小f不再生效
[root@centos82s data]$tail -f ping.log
#大F继续追踪
[root@centos82s data]$tail -Fn0 ping.log
hello
hello
tail: ‘ping.log‘ has become inaccessible: No such file or directory
tail: ‘ping.log‘ has appeared; following new file
hello? cut命令可以提取文本文件或STDIN数据的指定列
? 命令常用选项
? ? -d 指明分隔符,默认tab
? ? -f fileds:
? #: 第#个字段,例如:3
? #,#[,#]: 离散多个字段,例如:1,3,5
? #-#: 连续的多个字段,例如:1-6
? 混合使用:1-3,7
? ? -c 按字符切割
? ? --output-delimiter=STRING指定输出分隔符
#以:为分隔符,抽取
[root@centos82s data]$cut -d: -f1,3-4,7 passwd
root:0:0:/bin/bash
bin:1:1:/sbin/nologin
daemon:2:2:/sbin/nologin
adm:3:4:/sbin/nologin
lp:4:7:/sbin/nologin
sync:5:0:/bin/sync
shutdown:6:0:/sbin/shutdown
[root@centos82s data]$df|tr -s ‘ ‘|cut -d ‘ ‘ -f5|tr -dc "[0-9]\n"
0
0
2
0
3
15
15
0
[root@centos82s data]$df|tr -s ‘ ‘ %|cut -d% -f5|tr -d ‘[:alpha:]‘
0
0
2
0
3
15
15
0
[root@centos82s data]$df|tr -s ‘ ‘|cut -d ‘ ‘ -f5|tr -d %|tail -n +2
0
0
2
0
3
15
15
0
? paste合并多个文件同行号的列到一行
? 命令常用选项
? ? -d 分隔符:指定分隔符,默认用tab
? ? -s 所有行合成一行显示
#列显示
[root@centos82s data]$cat alpha.log seq.log
a
b
c
d
e
f
g
h
1
2
3
4
5
[root@centos82s data]$paste alpha.log seq.log
a 1
b 2
c 3
d 4
e 5
f
g
h
[root@centos82s data]$paste -d: alpha.log seq.log
a:1
b:2
c:3
d:4
e:5
f:
g:
h:
#行显示
[root@centos82s data]$paste -s alpha.log seq.log
a b c d e f g h
1 2 3 4 5? 文本数据统计:wc
? 整理文本: sort
? 比较文件: diff和patch
? wc命令可用于统计文件的行总数、单词总数、字节总数和字符总数,可以对文件或STDIN中的 数据统计
? 命令常用选项
? ? -l 只计算行数
? ? -w 只计算单词总数
? ? -c 只计算字节总数
? ? -m 只计算字符总数
? ? -L 显示文件中最长行的长度
[root@centos82s data]$wc seq.log
5 5 10 seq.log
行数 单词数 字节数
[root@centos82s data]$wc -l seq.log
5 seq.log
#取倒数第一行到倒数第八行
[root@centos82s ~]$df|tail -n $(echo `df|wc -l` -1|bc)
devtmpfs 905156 0 905156 0% /dev
tmpfs 921932 0 921932 0% /dev/shm
tmpfs 921932 17092 904840 2% /run
tmpfs 921932 0 921932 0% /sys/fs/cgroup
/dev/sda2 104806400 2196452 102609948 3% /
/dev/sda5 52403200 7799112 44604088 15% /data
/dev/sda1 999320 137604 792904 15% /boot
tmpfs 184384 0 184384 0% /run/user/0
? 把整理过的文本显示在STDOUT,不改变原始文件
? 命令常用选项
? ? -r 执行反方向(由上至下)整理
? ? -R 随机排序
? ? -n 执行按数字大小整理
? ? -h 人类可读排序,如:2k 1G
? ? -f 选项忽略(fold)字符串中的字符大小写
? ? -u 选项(独特,unique),合并重复项,即去重
? ? -t c 选项使用c做为字段界定符
? ? -k 选项按照使用c字符分隔的#列来整理能够使用多次
[root@centos82s data]$cut -d: -f1,3 passwd|sort -t: -k2 -nr|head -n 3
nobody:65534
lanlan:1003
honghong:1002
#统计日志同一个ip访问的数量
[root@centos82s data]$cut -d" " -f1 access_log|sort -u|wc -l
201
#统计分区利用率
[root@centos82s data]$df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 905156 0 905156 0% /dev
tmpfs 921932 0 921932 0% /dev/shm
tmpfs 921932 17092 904840 2% /run
tmpfs 921932 0 921932 0% /sys/fs/cgroup
/dev/sda2 104806400 2196416 102609984 3% /
/dev/sda5 52403200 7831184 44572016 15% /data
/dev/sda1 999320 137604 792904 15% /boot
tmpfs 184384 0 184384 0% /run/user/0
#查看分区利用率最高值
[root@centos82s data]$df|tr -s ‘ ‘ ‘%‘|cut -d% -f5|sort -nr|head -1
15
[root@centos82s data]$df|tr -s ‘ ‘ %|cut -d% -f5|tr -d ‘[:alpha:]‘|sort -nr|head -1
15
[root@centos82s data]$df|tr -s ‘ ‘ %|cut -d% -f5|tr -d ‘[:alpha:]‘|sort -n|tail -1
15
[root@centos82s data]$df|tr -s ‘ ‘ %|cut -d% -f5|tr -d ‘[:alpha:]‘|sort -nr|head -n1
15
#对指定的列数字排序
[root@centos82s data]$sort passwd
admins:x:1001:1001::/home/admins:/bin/bash
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/var/www:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
...
#以:为分隔符,对第三列即UNID按字母次序排序,取前三行
[root@centos82s data]$sort -t: -k3 passwd|head -n 3
root:x:0:0:root:/root:/bin/bash
dou:x:1000:1000:dou:/home/dou:/bin/bash
admins:x:1001:1001::/home/admins:/bin/bash
#以:为分隔符,对第3列即UNID按数字大小倒序排序,取前三行
[root@centos82s data]$sort -t: -k3 -nr passwd|head -n 3
nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin
lanlan:x:1003:1003::/home/lanlan:/bin/bash
honghong:x:1002:1002::/home/honghong:/bin/bash
#-R,随机排序
[root@centos82s data]$seq 5|sort -R
3
5
1
2
4
[root@centos82s data]$seq 5|sort -R
1
4
3
5
2
#-u去除重复的行
[root@centos82s data]$cut -d: -f7 passwd|sort
/bin/bash
/bin/bash
/bin/bash
/bin/bash
/bin/bash
/bin/sync
/sbin/halt
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
...
[root@centos82s data]$cut -d: -f7 passwd|sort -u
/bin/bash
/bin/sync
/sbin/halt
/sbin/nologin
/sbin/shutdown
? 去除相邻重复的行
? 命令常用选项
? ? -c 显示重复次数
? ? -d 显示重复过的行
? ? -u 显示没有重复过的行
#原文件输出
[root@centos82s data]$cat num1.txt
123
123
43
200
3321
3321
345
456
200
#去重
[root@centos82s data]$uniq num1.txt
123
43
200
3321
345
456
200
#-c
[root@centos82s data]$uniq -c num1.txt
2 123
1 43
1 200
2 3321
1 345
1 456
1 200
#-d
[root@centos82s data]$uniq -d num1.txt
123
3321
#-u
[root@centos82s data]$uniq -u num1.txt
43
200
345
456
200
#统计日志访问量最多的请求,取前三行
[root@centos82s data]$cut -d" " -f1 access_log|sort|uniq -c|sort -nr|head -n 3
4870 172.20.116.228
3429 172.20.116.208
2834 172.20.0.222
? diff命令可以对比两个文件的不同之处,方便查看改动过的内容
? 命令常用选项
? ? -y 选择并排对比
? ? -W 指定行宽度
? ? -u 以unified格式显示
[root@centos82s data]$cat num1.txt
1
2
3
4
5
6
7
8
9
[root@centos82s data]$cat num2.txt
1
2
33
4
55
6
#比较两个文件
[root@centos82s data]$diff num1.txt num2.txt
3c3
< 3
---
> 33
5c5
< 5
---
> 55
7,9d6
< 7
< 8
< 9
#说明:上面的3c3,5c5表示两个文件在第3行和第5行内容不同,7,9d6表示第一个文件比第二个文件多了7到9行
#-y,-W并排对比
[root@centos82s data]$diff num1.txt num2.txt -y -W 30
1 1
2 2
3 | 33
4 4
5 | 55
6 6
7 <
8 <
9 <
[root@centos82s data]$diff num2.txt num1.txt -y -W 30
1 1
2 2
33 | 3
4 4
55 | 5
6 6
> 7
> 8
> 9
"|" 表示两个文件内容的不同
"<" 表示后面文件比前面文件少了一行内容
">" 表示后面文件比前面文件多了一行内容
#-u 以unified格式显示
[root@centos82s data]$diff -u num1.txt num2.txt
--- num1.txt 2020-08-07 00:40:40.191763464 +0800
+++ num2.txt 2020-08-07 00:44:14.331778309 +0800
@@ -1,9 +1,6 @@
1
2
-3
+33
4
-5
+55
6
-7
-8
-9
"-":表示第一个文件,
"+":表示第二个文件,
"-1,9":表示第一个文件的第一行到第九行,
"+1,6":表示第二个文件的第一行到第六行,
"-3/-5/-7/-8/-9":表示第一个文件删除此行,可以和第二个文件行相同
"+33/+55":表示第一个文件添加此行,可以和第二个文件行相同? 利用patch命令,结合diff输出的unified格式信息和两个文件任意一个,可以生成另一个文件
? 命令常用选项
? ? -b 备份参考文档,文件名称后缀加.orig
#对比生成unified格式信息
[root@centos82s data]$diff -u num1.txt num2.txt > diff.txt
[root@centos82s data]$ll
total 7432632
-rw-r--r-- 1 root root 149 Aug 7 01:08 diff.txt
#删除一个文件
[root@centos82s data]$rm -f num2.txt
[root@centos82s data]$ll
total 7432628
-rw-r--r-- 1 root root 149 Aug 7 01:08 diff.txt
-rw-r--r-- 1 root root 18 Aug 7 00:40 num1.txt
#-b表示先备份num1.txt为num1.txt.orig,num1.txt内容是恢复的原num2.txt的数据,把num1.txt重命名为num2.txt,把num1.txt.orig重命名为num1.txt,搞定
[root@centos82s data]$patch -b num1.txt diff.txt
patching file num1.txt
[root@centos82s data]$ls
num1.txt.orig diff.txt num1.txt
? 命令常用选项,param代表正则表达式
? ? -color=auto 对匹配到的文本着色显示
? ? -m num 匹配num次后停止
? ? -v 显示不被param匹配到的行
? ? -i 忽略大小写
? ? -n 显示匹配的行号
? ? -c 统计匹配的行数
? ? -o 仅显示匹配到的字符串
? ? -q 静默模式,不输出任何信息,使用$?查看,0:匹配,1:没有匹配
? ? -A num after,后num行
? ? -B num before,前num行
? ? -C num context,前后各num行
? ? -e 实现多个选项间的逻辑 or 关系,如:grep -e ‘cat‘ -e ‘dog‘ file
? ? -w 匹配整个单词
? ? -E 使用ERE
? ? -F 相当于fgrep,不支持正则表达式
? ? -f file 根据模式文件处理
? ? -r 递归目录,不处理软链接
? ? -R 递归目录,处理软链接
#列出passwd文件中匹配到root的行
[root@centos82s data]$grep root passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#默认会对搜索到的内容着色显示
[root@centos82s data]$alias grep
alias grep=‘grep --color=auto‘
#-v,排除过滤,列出没有匹配到root的行
[root@centos82s data]$grep -v root passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
...
#-i,忽略大小写
[root@centos82s data]$grep ROOT passwd
[root@centos82s data]$grep -i ROOT passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#显示行号
[root@centos82s data]$grep -n root passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
#显示匹配到行的次数
[root@centos82s data]$grep -c root passwd
2
#只显示匹配到的内容,行的其它内容不显示
[root@centos82s data]$grep -o root passwd
root
root
root
root
#-q,静默模式,不输出信息,使用$?查看是否匹配
[root@centos82s data]$grep -q root passwd
[root@centos82s data]$echo $?
0
#
[root@centos82s data]$grep -n root passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
#匹配到行的后三行,和匹配行内容一起输出
[root@centos82s data]$grep -nA3 root passwd
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
4-adm:x:3:4:adm:/var/adm:/sbin/nologin
--
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13-nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin
#匹配到行的前三行,和匹配行内容一起输出
[root@centos82s data]$grep -nB3 root passwd
1:root:x:0:0:root:/root:/bin/bash
--
7-shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8-halt:x:7:0:halt:/sbin:/sbin/halt
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
#匹配到行的前后三行,和匹配行内容一起输出
[root@centos82s data]$grep -nC3 root passwd
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
3-daemon:x:2:2:daemon:/sbin:/sbin/nologin
4-adm:x:3:4:adm:/var/adm:/sbin/nologin
--
7-shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8-halt:x:7:0:halt:/sbin:/sbin/halt
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13-nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin
#-e,多次过滤,多个条件“或”的关系
[root@centos82s data]$grep -e root -e dou passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
dou:x:1000:1000:dou:/home/dou:/bin/bash
#"|"下面是与的关系
[root@centos82s data]$grep dou passwd|grep bin
dou:x:1000:1000:dou:/home/dou:/bin/bash
#-w,匹配单词,不模糊匹配
[root@centos82s data]$grep adm passwd
adm:x:3:4:adm:/var/adm:/sbin/nologin
admins:x:1001:1001::/home/admins:/bin/bash
[root@centos82s data]$grep -w adm passwd
adm:x:3:4:adm:/var/adm:/sbin/nologin
#-f,用文件存放过滤条件
[root@centos82s data]$cat f1.txt
root
dou
[root@centos82s data]$grep -f f1.txt passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
dou:x:1000:1000:dou:/home/dou:/bin/bash
? sed即Stream EDitor,和vi不同,sed是行编辑器
? sed是从文件或管道中读取一行,处理一行,直到最后一行。每当处理一行时,把当前处理的行存储在 临时缓冲区,称为模式空间,接着用sed命令处理缓冲区中的内容,处理完后,把缓冲区的内容送往屏 幕。接着处理下一行,这样不断重复,直到文件末尾。
? 常用选项
? ? -n 不输出模式空间内容到屏幕,即不自动打印
? ? -e 多点编辑
? ? -f FILE 从指定文件中读取编辑脚本
? ? -i。bak 备份文件并原处编辑
? script格式:’地址命令‘
? 地址格式
? ? 不给地址:对全文进行处理
? ? 单地址:
? #:指定的行,$:最后一行
? /pattern/:被此处模式所能够匹配到的每一行
? ? 地址范围:
? #,# 从#行到第#行
? #,+# 从#行到+#行
? /pat1/,/pat2/
? #,/pat/
? ? 步进:~,1~2 奇数行,2~2 偶数行
? 命令
? ? p 打印当前模式空间内容,追加到默认输出之后
? ? Ip 忽略大小写输出
? ? d 删除模式空间匹配的行,并立即启用下一轮循环
? ? a [\\]text 在指定行后面追加文本,支持使用\n实现多行追加
? ? i [\\]text 在行前面插入文本
? ? c [\\]text 替换行为单行或多行文本
? ? w file 保存模式匹配的行至指定文件
? ? r file 读取指定文件的文本至模式空间中匹配到的行后
? ? = 为模式空间中的行打印行号
? ? ! 模式空间中匹配行取反处理
? ? s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
? 替换修饰符:
? g 行内全局替换
? p 显示替换成功的行
? w /PATH/FILE 将替换成功的行保存至文件中
? I,i 忽略大小写
#-a,向匹配行后追加
[root@centos82s ~]$cat test.txt
dou123douo456dou789
13579dou
a246dou810
#方法一:指定行
[root@centos82s ~]$sed "2ahello" test.txt
dou123douo456dou789
13579dou
hello
a246dou810
#方法二:模糊匹配,可多行追加
[root@centos82s ~]$sed "/13579/ahello" test.txt
dou123douo456dou789
13579dou
hello
a246dou810
#向最后一行追加
[root@centos82s ~]$sed ‘$ahello‘ test.txt
dou123douo456dou789
13579dou
a246dou810
hello
#-i
[root@centos82s ~]$sed "2ihello" test.txt
dou123douo456dou789
hello
13579dou
a246dou810
[root@centos82s ~]$sed ‘/13/ihello‘ test.txt
dou123douo456dou789
hello
13579dou
a246dou810
[root@centos82s ~]$sed ‘$ihello‘ test.txt
dou123douo456dou789
13579dou
hello
a246dou810
#替换指定行
[root@centos82s ~]$sed ‘1chello‘ test.txt
hello
13579dou
a246dou810
#替换匹配行
[root@centos82s ~]$sed ‘/dou/chello‘ test.txt
hello
hello
hello
#替换最后一行
[root@centos82s ~]$sed ‘$chello‘ test.txt
dou123douo456dou789
13579dou
hello
#删除指定行
[root@centos82s ~]$sed ‘1d‘ test.txt
13579dou
a246dou810
#删除奇数行
[root@centos82s ~]$sed ‘1~2d‘ test.txt
13579dou
#删除1到2行
[root@centos82s ~]$sed ‘1,2d‘ test.txt
a246dou810
#删除1到2之外的行
[root@centos82s ~]$sed ‘1,2!d‘ test.txt
dou123douo456dou789
13579dou
#删除最后一行
[root@centos82s ~]$sed ‘$d‘ test.txt
dou123douo456dou789
13579dou
#删除模糊匹配行
[root@centos82s ~]$sed ‘/135/d‘ test.txt
dou123douo456dou789
a246dou810
#删除匹配行到最后一行
[root@centos82s ~]$sed ‘/135/,$d‘ test.txt
dou123douo456dou789
#删除匹配行及其下面一行
[root@centos82s ~]$sed ‘/135/,+1d‘ test.txt
dou123douo456dou789
#删除空行
[root@centos82s ~]$sed ‘/^$/d‘ test.txt
dou123douo456dou789
13579dou
a246dou810
#删除匹配行之外的行
[root@centos82s ~]$sed ‘/123\|135/!d‘ test.txt
dou123douo456dou789
13579dou
#删除指定行范围内匹配的行
[root@centos82s ~]$sed ‘1,3{/123/d}‘ test.txt
13579dou
a246dou810
#替换文件中的内容,默认只替换行中匹配的第一个
[root@centos82s ~]$sed ‘s/dou/xiaobai/‘ test.txt
xiaobai123douo456dou789
13579xiaobai
a246xiaobai810
#替换内容,g,全局替换
[root@centos82s ~]$sed ‘s/dou/xiaobai/g‘ test.txt
xiaobai123xiaobaio456xiaobai789
13579xiaobai
a246xiaobai810
#将每行中匹配到内容的第二个替换
[root@centos82s ~]$sed ‘s/dou/xiaobai/2‘ test.txt
dou123xiaobaio456dou789
13579dou
a246dou810
#将每行匹配到内容的第二行替换,并将替换过的内容保存到文件
[root@centos82s ~]$sed -n ‘s/dou/xiaobai/2pw test1.txt‘ test.txt
dou123xiaobaio456dou789
#将每一行行首匹配到的内容替换为空
[root@centos82s ~]$sed ‘/^#.*/s/#/‘‘/‘ test.txt
dou123douo456,dou789
sds,%sdjsdo#@
,13579dou
,sakjdlsad
234cac2,46dou810
#将每一行行首匹配到的内容替换为@
[root@centos82s ~]$sed ‘/^#.*/s/#/@/‘ test.txt
@dou123douo456,dou789
@sds,%sdjsdo#@
@,13579dou
,sakjdlsad
@234cac2,46dou810
#匹配行首为#的行,替换,逗号后面的内容为空
[root@centos82s ~]$sed ‘/^#.*/s/,.*//g‘ test.txt
#dou123d#ouo456
#sds
#
,sakjdlsad
#234ca#c2
#替换每行最后两个字符为空
[root@centos82s ~]$sed ‘s/..$//g‘ test.txt
#dou123d#ouo456,dou7
#sds,#%sdjsdo
#,13579d
,sakjdls
#234ca#c2,46dou8、
#将行首为#的行替换为空
[root@centos82s ~]$sed ‘s/^#.*//‘ test.txt
,sakjdlsad
#将行首为#的替换为空,然后删除为空的行
[root@centos82s ~]$sed ‘s/^#.*//;/^$/d‘ test.txt
,sakjdlsad
#将所有数字行首加上()
[root@centos82s ~]$cat test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
,sakjdlsad
4.#234ca#c2,46dou810
#方法一
[root@centos82s ~]$sed ‘s/^[0-9]/(&)/‘ test.txt
(1).#dou123d#ouo456,dou789
(2).#sds,#%sdjsdo#@
(3).#,13579dou
,sakjdlsad
(4).#234ca#c2,46dou810
#方法二
[root@centos82s ~]$sed ‘s/\([0-9]\)/(\1)/‘ test.txt
(1).#dou123d#ouo456,dou789
(2).#sds,#%sdjsdo#@
(3).#,13579dou
,sakjdlsad
(4).#234ca#c2,46dou810
#在每一行行尾添加内容
[root@centos82s ~]$sed ‘s/$/& ‘xiaobai‘/‘ test.txt
1.#dou123d#ouo456,dou789 xiaobai
2.#sds,#%sdjsdo#@ xiaobai
3.#,13579dou xiaobai
,sakjdlsad xiaobai
4.#234ca#c2,46dou810 xiaobai
#打印文件第三行内容
[root@centos82s ~]$sed -n ‘3p‘ test.txt
3.#,13579dou
#从第二行开始每隔二行打印一行
[root@centos82s ~]$sed -n ‘2~2p‘ test.txt
2.#sds,#%sdjsdo#@
,sakjdlsad
#打印第一行到第三行
[root@centos82s ~]$sed -n ‘1,3p‘ test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
#打印最后一行
[root@centos82s ~]$sed -n ‘$p‘ test.txt
4.#234ca#c2,46dou810
#打印第二行到最后一行
[root@centos82s ~]$sed -n ‘2,$p‘ test.txt
2.#sds,#%sdjsdo#@
3.#,13579dou
,sakjdlsad
4.#234ca#c2,46dou810
#打印匹配到的行
[root@centos82s ~]$sed -n ‘/dou/p‘ test.txt
1.#dou123d#ouo456,dou789
3.#,13579dou
4.#234ca#c2,46dou810
#打印从匹配s行匹配到dou的行
[root@centos82s ~]$sed -n ‘/s/,/dou/p‘ test.txt
2.#sds,#%sdjsdo#@
3.#,13579dou
,sakjdlsad
4.#234ca#c2,46dou810
#打印行号,和wc -l类似
[root@centos82s ~]$sed -n ‘$=‘ test.txt
5
#打印匹配行的行号
[root@centos82s ~]$sed -n ‘/dou/=‘ test.txt
1
3
5
#打印匹配行的行号和内容
[root@centos82s ~]$sed -n ‘/dou/{=;p}‘ test.txt
1
1.#dou123d#ouo456,dou789
3
3.#,13579dou
5
4.#234ca#c2,46dou810
#将一个文件的内容读取到另一个文件,在另一个文件的每一行追加显示
[root@centos82s ~]$sed ‘r test1.txt‘ test.txt
1.#dou123d#ouo456,dou789
dou123xiaobaio456dou789
2.#sds,#%sdjsdo#@
dou123xiaobaio456dou789
3.#,13579dou
dou123xiaobaio456dou789
,sakjdlsad
dou123xiaobaio456dou789
4.#234ca#c2,46dou810
dou123xiaobaio456dou789
#将一个文件内容读取到另一个文件的第三行后面追加显示
[root@centos82s ~]$sed ‘3r test1.txt‘ test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
dou123xiaobaio456dou789
,sakjdlsad
4.#234ca#c2,46dou810
#将一个文件内容读取到另一个文件匹配内容行的后面追加显示
[root@centos82s ~]$sed ‘/135/r test1.txt‘ test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
dou123xiaobaio456dou789
,sakjdlsad
4.#234ca#c2,46dou810
#将一个文件内容读取到另一个文件内容的最后一行
[root@centos82s ~]$sed ‘$r test1.txt‘ test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
,sakjdlsad
4.#234ca#c2,46dou810
dou123xiaobaio456dou789
#将一个test文件内容读取到另一个test1文件,文件不存在则创建,文件存在则覆盖
[root@centos82s ~]$sed ‘w test1.txt‘ test.txt
1.#dou123d#ouo456,dou789
2.#sds,#%sdjsdo#@
3.#,13579dou
dou123xiaobaio456dou789
,sakjdlsad
4.#234ca#c2,46dou810
#将文件test的第一行和最后一行写入test1
[root@centos82s ~]$sed -n -e ‘1w test1.txt‘ -e ‘$w test1.txt‘ test.txt
[root@centos82s ~]$cat test1.txt
1.#dou123d#ouo456,dou789
4.#234ca#c2,46dou810
#将test文件的第一行和第二行分别写入test1和test2
[root@centos82s ~]$sed -n -e ‘1w test1.txt‘ -e ‘$w test2.txt‘ test.txt 正则表达式分为两类:
? ? 基本正则表达式:BRE
? ? 扩展正则表达式:ERE
? 一般使用正则表达式用""将其包裹起来,避免特殊字符的影响
? 正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组和逻辑组合
? 字符元字符列表
? ? . 任意单个字符
? ? [] 指定范围内的字符,如[dou],表示匹配d,o,u这三个字符中的任何一个
? ? [^] 排除[]中的字符,如[dou],表示匹配d,o,u 这个三个字符除外的任何一个
? ? [:alnum:] 字母和数字
? ? [:alpha:] 字母
? ? [:lower:] 小写字母
? ? [:upper:] 大写字母
? ? [:blank:] 空格和tab
? ? [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
? ? [:digit:] 十进制数字,即0-9
? ? [:xdigit:] 十六进制数字
? ? [:cntrl:] 不可打印的控制字符(退格、删除...)
? ? [:graph:] 可打印的非空白字符
? ? [:print:] 可打印的字符
? ? [:punct:] 标点符号
#.匹配单个字符
[root@centos82s data]$grep "r..t" passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
#匹配文件中的数字
[root@centos82s data]$grep "[0-9]" passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
...
#过滤指定的字符
[root@centos82s data]$cat f1.txt
dou1
dou3
dou5
dou7
[root@centos82s data]$grep "dou[1-3]" f1.txt
dou1
dou3
#过滤指定的字符(取反)
[root@centos82s data]$grep "dou[^1-3]" f1.txt
dou5
dou7? 用在要指定次数的字符后面,代表字符要出现的次数
? 次数匹配规则元字符
? ? * 匹配前面字符N次,包括0次
? ? \? 匹配前面字符0次或1次
? ? \+ 匹配前面字符至少1次
? ? \{n\} 匹配前面字符连续n次,n为数字
? ? \{m,n\} 匹配前面字符次数要大于等于m,小于等于n
? ? \{m,} 匹配前面字符次数大于等于m
? ? \{,n} 匹配前面字符次数小于等于n
[root@centos82s data]$cat f1.txt
dou111
dou333333
dou555555555
dou7
dou
# *,匹配“1”任意次
[root@centos82s data]$grep "dou1*" f1.txt
dou111
dou333333
dou555555555
dou7
dou
# \?,匹配1,0次或1次
[root@centos82s data]$grep "dou1\?" f1.txt
dou111
dou333333
dou555555555
dou7
dou
# \+,至少匹配1,1次
[root@centos82s data]$grep "dou1\+" f1.txt
dou111
# \{n\},匹配1,n次
[root@centos82s data]$grep "dou1\{4\}" f1.txt
[root@centos82s data]$grep "dou1\{2\}" f1.txt
dou111
# \{m,n\},匹配1,大于等于3次,小于等于7次
[root@centos82s data]$grep "dou1\{3,7\}" f1.txt
dou111
# \{m,\},匹配1,大于等于3次
[root@centos82s data]$grep "dou1\{3,\}" f1.txt
dou111
[root@centos82s data]$grep "dou1\{4,\}" f1.txt
[root@centos82s data]$? 位置锚定可以用于定位出现的位置
? ? ^ 行首锚定,用于模式的最左侧
? ? $ 行尾锚定,用于模式的最右侧
? ? ^PATTERN$ 用于模式匹配整行
? ? ^$ 空行
? ? ^[[:space:]] 空白行
? ? \< 或 \b 词首锚定,用于单词模式的左侧
? ? \> 或 \b 词尾锚定,用于单词模式的右侧
? ? \<PATTERN\> 匹配整个单词
[root@centos82s data]$grep root passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#查找以root为行首的行
[root@centos82s data]$grep "^root" passwd
root:x:0:0:root:/root:/bin/bash
#查找非#开头的行
[root@centos82s data]$grep "^[^#].*" fstab
UUID=5e437624-9610-4d5d-804b-ec9054e9f46d / xfs defaults 0 0
UUID=e54fe5be-10b7-456b-b297-cf28faf5aab6 /boot ext4 defaults 1 2
UUID=7faf9f94-f218-4497-9fa2-030c11f8d577 /data xfs defaults 0 0
UUID=9c230f26-8349-4153-b1d6-742a6a7b7088 swap swap defaults 0 0
#查询以bash结尾的行
[root@centos82s data]$grep "bash$" passwd
root:x:0:0:root:/root:/bin/bash
dou:x:1000:1000:dou:/home/dou:/bin/bash
admins:x:1001:1001::/home/admins:/bin/bash
honghong:x:1002:1002::/home/honghong:/bin/bash
lanlan:x:1003:1003::/home/lanlan:/bin/bash
#位置匹配行
[root@centos82s data]$grep "^dou111$" f1.txt
dou111
#词首词尾锚定
[root@centos82s data]$grep -n "\bdo" f1.txt
1:dou111
2:dou333333
3:dou555555555
4:dou7
5:dou
[root@centos82s data]$grep -n "\bdou1" f1.txt
1:dou111
[root@centos82s data]$grep -n "\<dou1" f1.txt
1:dou111
[root@centos82s data]$grep -n "1\b" f1.txt
1:dou111
[root@centos82s data]$grep -n "1\>" f1.txt
1:dou111? ? () 分组
? ? 后向引用:\1,\2,...
? ? \| 或者
? ? a\|b a或b
? ? C\|cat C或cat
? ? \(C\|c\)at Cat或cat
[root@centos82s data]$cat f1.txt
doudoudoudou
dououdououou
oudoudoudoud
#查看包含dou连续出现3次的行
[root@centos82s data]$grep "\(dou\)\{3\}" f1.txt
doudoudoudou
oudoudoudoud
[root@centos82s data]$cat f1.txt
cat
c
tomCat
Tom
dou
Cat
#查询包含大写C和cat的行
[root@centos82s data]$grep "C\|cat" f1.txt
cat
tomCat
Cat
#查询Cat和cat的行
[root@centos82s data]$grep "\(C\|c\)at" f1.txt
cat
tomCat
Cat
[root@centos82s data]$grep "\(C\|c\)At" f1.txt
[root@centos82s data]$? 去掉了普通正则表达式的"\"转义字符
? ? . 任意单个字符
? ? [] 指定范围内的字符,如[dou],表示匹配d,o,u这三个字符中的任何一个
? ? [^] 排除[]中的字符,如[dou],表示匹配d,o,u 这个三个字符除外的任何一个
? ? [:alnum:] 字母和数字
? ? [:alpha:] 字母
? ? [:lower:] 小写字母
? ? [:upper:] 大写字母
? ? [:blank:] 空格和tab
? ? [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
? ? [:digit:] 十进制数字,即0-9
? ? [:xdigit:] 十六进制数字
? ? [:cntrl:] 不可打印的控制字符(退格、删除...)
? ? [:graph:] 可打印的非空白字符
? ? [:print:] 可打印的字符
? ? [:punct:] 标点符号
? 用在要指定次数的字符后面,代表字符要出现的次数
? 次数匹配规则元字符
? ? * 匹配前面字符N次,包括0次
? ? ? 匹配前面字符0次或1次
? ? + 匹配前面字符至少1次
? ? {n} 匹配前面字符连续n次,n为数字
? ? {m,n} 匹配前面字符次数要大于等于m,小于等于n
? ? ^ 行首锚定,用于模式的最左侧
? ? $ 行尾锚定,用于模式的最右侧
? ? \< 或 \b 词首锚定,用于单词模式的左侧
? ? \> 或 \b 词尾锚定,用于单词模式的右侧
? ? () 分组
? ? 后向引用:\1,\2,...
? ? | 或者
? ? a|b a或b
? ? C|cat C或cat
? ? (C|c)at Cat或cat
[root@centos82s data]$vim hello.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-07
#FileName: hello.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#经典写法
echo "hello,world"
#流行写法
echo "Hello,world!"
#执行方法1
[root@centos82s data]$bash hello.sh
hello,world
Hello,world!
#执行方法2
[root@centos82s data]$cat hello.sh|bash
hello,world
Hello,world!
#执行方法3
[root@centos82s data]$bash < hello.sh
hello,world
Hello,world!
#执行方法4,指定执行权限给hello.sh
[root@centos82s data]$/data/hello.sh
-bash: /data/hello.sh: Permission denied
[root@centos82s data]$chmod +x hello.sh
[root@centos82s data]$/data/hello.sh #绝对路径
hello,world
Hello,world!
[root@centos82s data]$./hello.sh #相对路径
hello,world
Hello,world!
#执行方法5,本方法可以实现执行远程主机的shell脚本
[root@centos82s ~]$cp /data/hello.sh /var/www/html
[root@centos82s ~]$curl http://10.0.0.115/hello.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-07
#FileName: hello.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#经典写法
echo "hello,world"
#流行写法
eco "Hello,world!"
echo "哈喽我怎么显示了呢"
? 只检测脚本中的语法错误,但无法检查出命令错误,不真正执行脚本
[root@centos82s data]$cat hello.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-07
#FileName: hello.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#经典写法
echo "hello,world #缺少"
#流行写法
echo "Hello,world!"
#-n,语法错误,命令不继续执行
[root@centos82s data]$bash -n hello.sh
hello.sh: line 16: unexpected EOF while looking for matching `"‘
hello.sh: line 17: syntax error: unexpected end of file
#命令错误,命令继续执行
[root@centos82s data]$./hello.sh
hello,world
./hello.sh: line 16: eco: command not found
哈喽我怎么显示了呢
#-x,检查出错的命令
[root@centos82s data]$bash -x hello.sh
+ echo hello,world
hello,world
+ eco ‘Hello,world!‘
hello.sh: line 16: eco: command not found
+ echo 哈喽我怎么显示了呢
哈喽我怎么显示了呢总结:脚本常见错误有三种
? ? 语法错误,会导致后续的命令不继续执行,可以用bash -n检查错误,提示的出错行数不一定准确
? ? 命令错误,默认后续的命令还继续执行,用bash -n 无法检查出来,可以使用bash -x 进行观察
? ? 逻辑错误,只能使用 bash -x 进行观察
? 变量表示命名的内存空间,将数据放在内存空间中,通过变量名引用获取数据
? 变量类型:
? ? 内置变量,如:PS1,PATH,UID,HOSTNAME,$$,BASHPID,$?,HISTSIZE
? ? 用户自定义变量
? 变量数据类型:
? ? 字符
? ? 数值:整型、浮点型、bash不支持浮点数
? ? 不能使用程序中的保留字和内置变量
? ? 只能使用数字、字母、下划线,且不能以数字开头,不支持“-”
? ? 统一命名规则:驼峰命名,studentname,大驼峰,StudengName,小驼峰,studentName
? ? 变量名大写
? ? 局部变量小写
、 ? 函数名小写
? 标准划分变量类型的生效范围
? ? 普通变量:生效范围为当前shell进程;对当前shell之外的其它shell进程和其子shell进程均无效
? ? 环境变量:生效范围为当前shell进程及其子进程
? ? 本地变量:生效范围为当前shell进程中的某代码片段,通常指函数
? 变量赋值:
? 直接字符串: name="root"
? 变量引用: name="$USER"
? 命令引用: name=`COMMAND`` 或者 name=$(COMMADN)
? 注意:变量赋值是临时生效,退出终端后,变量会自动删除,脚本中的变量会随着脚本结束
? 变量引用:$name 或 ${name}
? 弱引用和强引用
? ? "$name" 弱引用,其中变量会被替换为变量值
? ? ‘$name‘ 强引用,变量不会替换为变量值,保持原字符串
#赋值字符串
[root@centos82s ~]$NAME="小白"
[root@centos82s ~]$echo $NAME
小白
[root@centos82s ~]$echo hello $NAME
hello 小白
[root@centos82s ~]$echo "hello,$NAME"
hello,小白
[root@centos82s ~]$echo ‘hello,$NAME‘
hello,$NAME
#变量引用
[root@centos82s ~]$USERNAME="$NAME"
[root@centos82s ~]$echo $USERNAME
小白
#给变量赋值命令
[root@centos82s ~]$HOST=`hostname`
[root@centos82s ~]$echo $HOST
centos82s
#显示定义的所有变量
HOST=centos82s
NAME=小白
USERNAME=小白
#删除变量
[root@centos82s ~]$unset USERNAME? ? 可以使子进程或子子进程继承父进程的变量,但父进程无法使用子进程变量
? ? 子进程修改从父进程继承的变量,新的值会传递给子子进程
? ? 一般使用在系统配置文件,脚本中很少使用
#声明并赋值
[root@centos82s ~]$export name=小白
[root@centos82s ~]$echo $name
小白
[root@centos82s ~]$declare -x name=小黑
[root@centos82s ~]$echo $name
小黑
#先赋值,后设置为环境变量
[root@centos82s ~]$name=小分
[root@centos82s ~]$export name
[root@centos82s ~]$echo $name
小分
#显示所有环境变量
[root@centos82s ~]$env
[root@centos82s ~]$printenv
[root@centos82s ~]$export
[root@centos82s ~]$declare -x
#删除变量
[root@centos82s ~]$unset name
? bash内建的环境变量
[root@centos82s ~]$echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@centos82s ~]$echo $SHELL
/bin/bash
[root@centos82s ~]$echo $USER
root
[root@centos82s ~]$echo $UID
0
[root@centos82s ~]$echo $HOME
/root
[root@centos82s ~]$echo $PWD
/root
[root@centos82s ~]$echo $SHLVL
1
[root@centos82s ~]$echo $LANG
en_US.UTF-8
[root@centos82s ~]$echo $MAIL
/var/spool/mail/root
[root@centos82s ~]$echo $HOSTNAME
centos82s
[root@centos82s ~]$echo $HISTSIZE
1000? 只读变量:只能声明定义,后续不能修改和删除,即常量
#声明变量并赋值
[root@centos82s ~]$readonly name="小明"
[root@centos82s ~]$declare -r age="20"
#不能修改和删除
[root@centos82s ~]$name="小黑"
-bash: name: readonly variable
[root@centos82s ~]$unset name
-bash: unset: name: cannot unset: readonly variable? 位置变量:在bash shell中内置的变量,在脚本代码中调用通过命令行传递给脚本的参数
? ? $0 命令本身,包括路径
? ? $1,$2... 对应第一个,第二个参数,shint [n]换位置
? ? $* 传递给脚本的所有参数,所有参数合并为一个字符串
? ? $@ 传递给脚本的所有参数,每个参数为独立字符串
? ? $# 传递给脚本的参数个数
? 注意:$@ ,$* 只在被双引号包裹起来的时候才有差异
? ? set -- 清空所有位置变量
[root@centos82s data]$cat wz.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-08
#FileName: wz.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#内置变量
echo "1var is $1"
echo "2var is $2"
echo "3var is $3"
echo "10var is ${10}"
echo "11var is ${11}"
echo "The number of vaer is $#"
echo "All vars are $*"
echo "All vars are $@"
echo "The scriptname is `basename $0`"
[root@centos82s data]$bash wz.sh {a..z}
1var is a
2var is b
3var is c
10var is j
11var is k
The number of vaer is 26
All vars are a b c d e f g h i j k l m n o p q r s t u v w x y z
All vars are a b c d e f g h i j k l m n o p q r s t u v w x y z
The scriptname is wz.sh
[root@centos82s data]$bash < . wz.sh {a..z}
1var is a
2var is b
3var is c
10var is j
11var is k
The number of vaer is 26
All vars are a b c d e f g h i j k l m n o p q r s t u v w x y z
All vars are a b c d e f g h i j k l m n o p q r s t u v w x y z
The scriptname is wz.sh
#$*和$@的区别
[root@centos82s data]$cat f1.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-08
#FileName: f1.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#
echo "f1.sh:all args are $@"
echo "f1.sh:all args are $*"
bash file.sh "$*"
[root@centos82s data]$cat f2.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-08
#FileName: f2.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#
echo "f2.sh:all args are $@"
echo "f2.sh.all args are $*"
bash file.sh "$@"
[root@centos82s data]$cat file.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-08
#FileName: file.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#
echo "file.sh:1st arg is $1"
[root@centos82s data]$bash f1.sh a b c
f1.sh:all args are a b c
f1.sh:all args are a b c
file.sh:1st arg is a b c #把所有参数合并作为一个字符串
[root@centos82s data]$bash f2.sh a b c
f2.sh:all args are a b c
f2.sh.all args are a b c
file.sh:1st arg is a #还是独立的字符串参数
#创建一个脚本,输出信息为命令本身包括路径
[root@centos82s data]$cat lin.sh
#!/bin/bash
#
#*************************************************************************
#Author: dadoudou
#QQ:
#Date: 2020-08-08
#FileName: lin.sh
#URL:
#Description: The test script
#Copyright (C) 2020All rights reserved
#*************************************************************************
#
#
echo $0
#指定lin.sh文件的两个软连接
[root@centos82s data]$ln -s lin.sh lina.sh
[root@centos82s data]$ln -s lin.sh linb.sh
#同一文件的软连接,执行的脚本相同,可以实现不同的功能
[root@centos82s data]$bash lina.sh
lina.sh
[root@centos82s data]$bash linb.sh
linb.sh? 15.2.9 退出状态码
? 浏览网页时会有表示网页错误信息的数字,称为状态码,在shell脚本中也有相应状态,进程执行 后,将使用变量$?保存执行后状态码的相关数字,不同的值反应成功或失败,$?取值0-255
? ? 脚本中遇到exit命令,脚本会立即终止;终止退出状态码取决于exit命令后面的数字,可自己定义
? ? 如果没有给脚本指定退出状态码,状态码取决于最后一条命令的状态码
? ? $?=0 #代表成功
? ? $?=[1-255] #代表失败
[root@centos82s data]$echo $?
0
[root@centos82s data]$hostnamee
-bash: hostnamee: command not found
[root@centos82s data]$echo $?
127标签:grep -n art 链接 计算 主机 全局替换 dig pre 自定义
原文地址:https://blog.51cto.com/13812780/2519744