标签:方法 不能 使用 开始 sock 情况下 code 注意 inf
首先我们知道进程是无法直接操作I/O设备的,其必须通过系统调用请求内核来协助完成I/O动作,而内核会为每个I/O设备维护一个buffer。
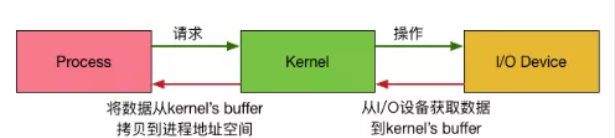
这里数据的两次拷贝都需要时间,而这两端时间中进程和内核的状态不一样就产生了下面五种i/o模型:
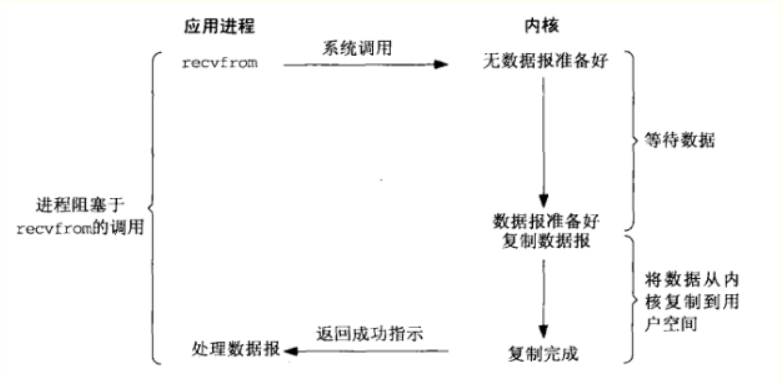
阻塞I/O
对于内核而言,网络中的数据并不一定马上可读,所以内核要等到数据准备好了往内核读。然后再将读取完成的内核数据拷贝给用户。而这期间用户线程也是一直在等待读取数据,不能够做其他事。
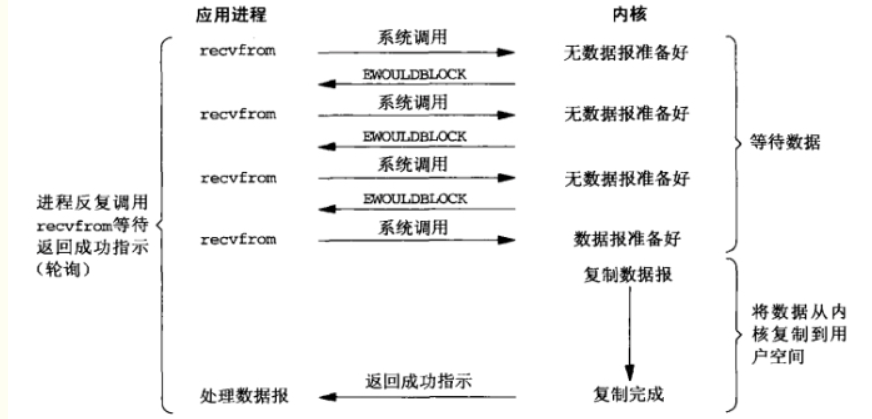
非阻塞I/O
所以我们就想,能不能让用户线程不要那么傻,一直在哪里等。当用户发送时,内核缓存数据准备好没有给个准话,当时就直接返回信息0或者1.要是0的用户就做其他事,然后再来问。要是1的话就直接开始将数据拷贝到用户缓存区。
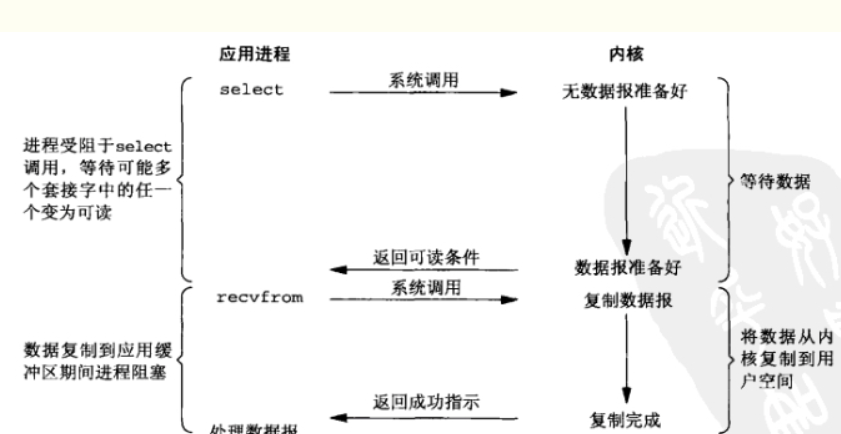
I/O复用
在上面的模型中,我们针对的是一个process对应一个i/o。那如果用户进程调用了多个i/o呢?当然我们可以采用前面两种方式一个接一个的完成i/o操作。那能不能有一种方式对这多个i/o进行选择呢?比如谁准备好了就先调用谁?这里就是我们的i/o复用了。用户通过select这个函数不断轮询所有它负责的socket连接。这里需要注意的是,虽然第一阶段都是阻塞,但是阻塞式I/O如果要接收更多的连接,就必须创建更多的线程。I/O复用模式下在第一个阶段大量的连接统统都可以过来直接注册到Selector复用器上面,同时只要单个或者少量的线程来循环处理这些连接事件就可以了,一旦达到“就绪”的条件,就可以立即执行真正的I/O操作。而且并不是说性能方面复用就一定优于阻塞,前者只是更加适合于需要大量连接的场景。
信号驱动的I/O
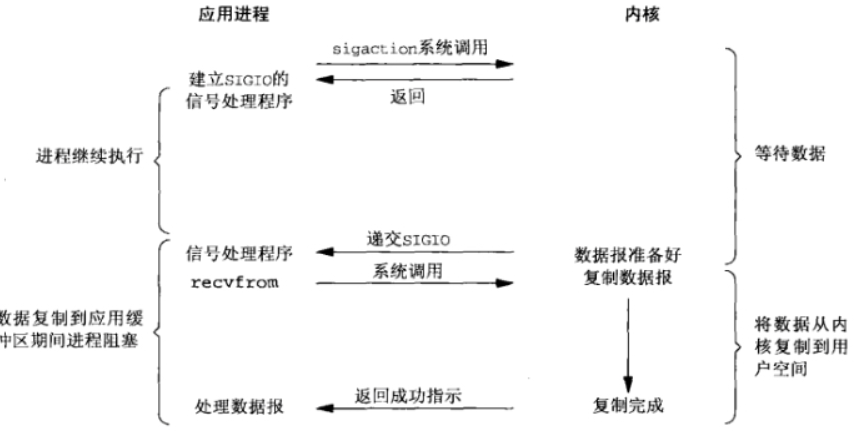
首先用户进程建立SIGIO信号处理程序,并通过系统调用sigaction执行一个信号处理函数,这时用户进程便可以做其他的事了,一旦数据准备好,系统便为该进程生成一个SIGIO信号,去通知它数据已经准备好了,于是用户进程便调用recvfrom把数据从内核拷贝出来,并返回结果。
异步I/O
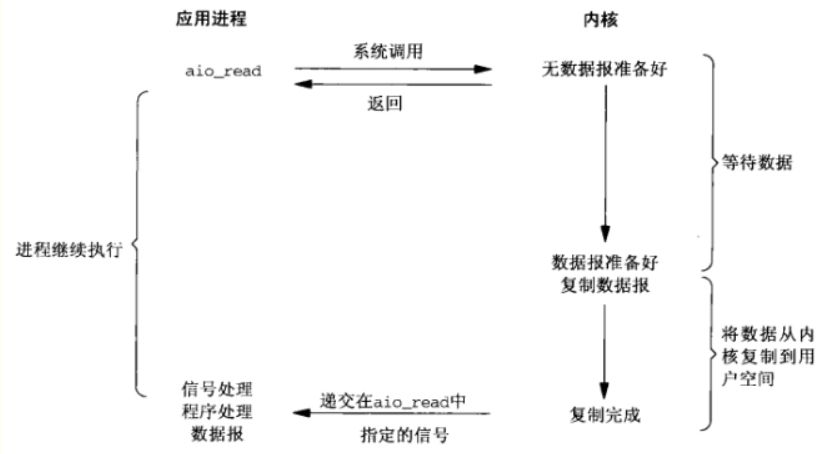
前面四种模型在最后一步真正的I/O操作是同步阻塞(拷贝数据)。但是异步I/O中当用户进程向内核发起某个操作后,会立刻得到返回,并把所有的任务都交给内核去完成(包括将数据从内核拷贝到用户自己的缓冲区),内核完成之后,只需返回一个信号告诉用户进程已经完成就可以了。
换种方式理解,最初的io模型中,关注的信息是->我要读写了。这种情况下,等待数据准备好和拷贝数据都阻塞,然后进一步的nio模型中,关注的信息是->我可以读写了。这种情况下socket主要的读、写、注册和接收函数在等待的时候都是非阻塞的,只是在最后的拷贝阶段是同步阻塞的。但性能非常高。然后最新的aio中,最后一步操作都是非阻塞的。完成后直接给线程一条数据准备完成的信号就可以了。
CPU不执行数据从一个存储区域到另一个存储区域的拷贝任务,这通常用于在网络上传输文件时节省CPU周期和内存带宽。
首先我们需要知道的大多数文件系统的默认 IO 操作都是缓存 IO。也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。也就是说在一次网络传输过程中,数据大概会经历四次copy:
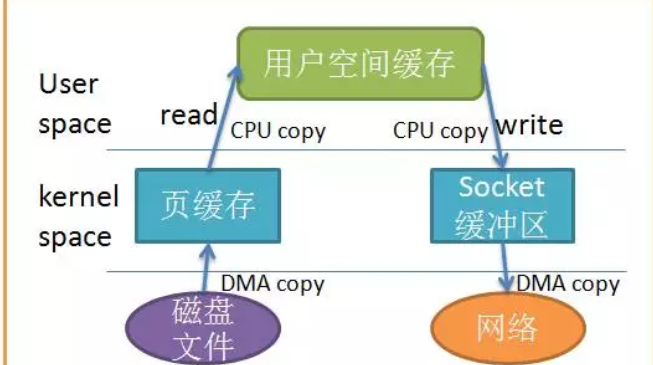
其中还发生了多次上下文切换,这样确实加大了cpu的负担,我们可以怎样优化呢?
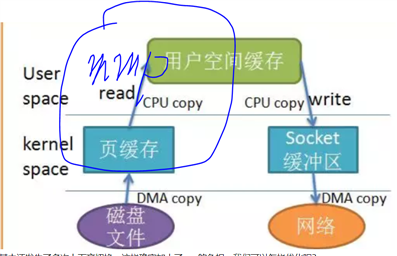
非直接缓冲区是直接通过拷贝的形式传递的,如从磁盘读取文件到物流空间,然后拷贝到jvm,再读取数据。直接缓冲区是通过物流内存映射文件直接传递的
正常情况下,JVM创建一个缓冲区的时候,实际上做了如下几件事:
所有的IO操作都需要操作系统进入内核态才行,而JVM进程属于用户态进程, 当JVM需要把一个缓冲区写到某个Channel或Socket的时候,需要切换到内核态.
而内核态由于并不知道JVM里面这个缓冲区存储在物理内存的什么地址,并且这些物理地址并不一定是连续的(或者说不一定是IO操作需要的块结构),所以在切换之前JVM需要把缓冲区复制到物理内存一块连续的内存上, 然后由内核去读取这块物理内存,整合成连续的、分块的内存.
也就是说如果我们这个时候用的是非直接缓存的话,我们还要进行“复制”这么一个操作,而当我们申请了一个直接缓存的话,因为他本是就是一大块连续地址,我们就可以直接在它上面进行IO操作,省去了“复制”这个步骤
当然缺点也是有的,他的分配和释放都比较昂贵,而且容易发生内存泄露。
标签:方法 不能 使用 开始 sock 情况下 code 注意 inf
原文地址:https://www.cnblogs.com/jiezao/p/13511501.html