标签:== fixed obj gate 多线程 rman 传输 boolean 编辑
前言如果按照用途与特性进行粗略的划分,JUC 包中包含的工具大体可以分为 6 类:
在【并发系列】中,主要讲解了 执行者与线程池,同步工具,锁 , 在分析源码时,或多或少的提及到了「队列」,队列在 JUC 中也是多种多样存在,所以本文就以「远看」视角,帮助大家快速了解与区分这些看似「杂乱」的队列
Java 并发队列按照实现方式来进行划分可以分为 2 种:
如果你已经看完并发系列锁的实现,你已经能够知道他们实现的区别:
前者就是基于锁实现的,后者则是基于 CAS 非阻塞算法实现的
常见的队列有下面这几种:
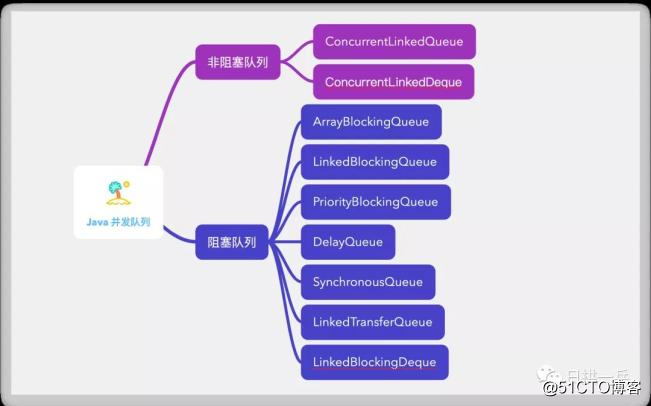
瞬间懵逼?看到这个没有人性的图想直接走人?客观先别急,一会就柳暗花明了
当下你也许有个问题:
锁有应对各种情形的锁,队列也自然有应对各种情形的队列了, 是不是也有点单一职责原则的意思呢?
所以我们要了解这些队列到底是怎么设计的?以及用在了哪些地方?
先来看下图
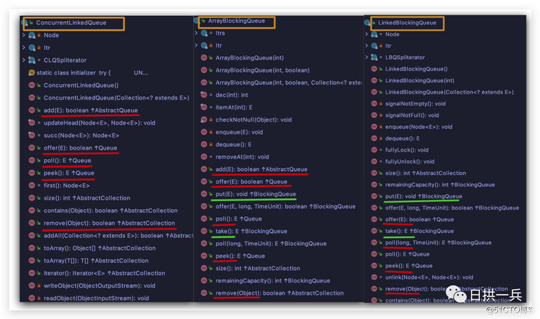
如果你在 IDE 中打开以上非阻塞队列和阻塞队列,查看其实现方法,你就会发现,阻塞队列较非阻塞队列 额外支持两种操作:
当队列满时,队列会阻塞插入元素的线程,直到队列不满
当队列为空时,获取元素的线程会阻塞,直到队列变为非空
综合说明入队/出队操作,看似杂乱的方法,用一个表格就能概括了

关于阻塞,我们其实早在 并发编程之等待通知机制 就已经充分说明过了,你还记得下面这张图吗?原理其实是一样一样滴
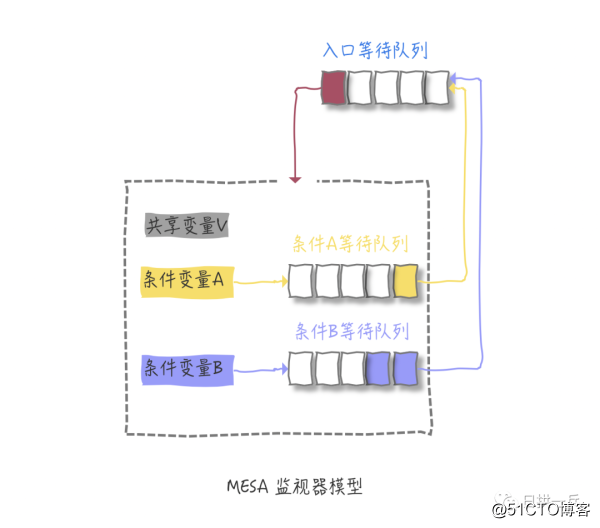
和锁一样,因为有阻塞,为了灵活使用,就一定支持超时退出,阻塞时间达到超时时间,就会直接返回
至于为啥插入和移除这么多种单词表示形式,我也不知道,为了方便记忆,只需要记住阻塞的方法形式即可:
单词 put 和 take 字母 t 首位相连,一个放,一个拿
到这里你应该对 Java 并发队列有了个初步的认识了,原来看似杂乱的方法貌似也有了规律。接下来就到了疯狂串知识点的时刻了,借助前序章节的知识,分分钟就理解全部队列了
之前也说过,JDK中的命名还是很讲究滴,一看这名字,底层就是数组实现了,是否有界,那就看在构造的时候是否需要指定 capacity 值了
填鸭式的说明也容易忘,这些都是哪看到的呢?在所有队列的 Java docs 的第一段,一句话就概括了该队列的主要特性,所以强烈建议大家自己在看源码时,简单瞄一眼 docs 开头,心中就有多半个数了
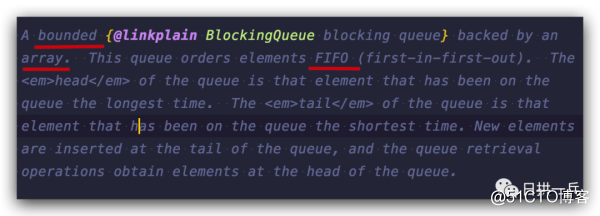
在讲 Java AQS队列同步器以及ReentrantLock的应用 时我们介绍了公平锁与非公平锁的概念,ArrayBlockingQueue 也有同样的概念,看它的构造方法,就有 ReentrantLock 来辅助实现
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
} 默认情况下,依旧是不保证线程公平访问队列(公平与否是指阻塞的线程能否按照阻塞的先后顺序访问队列,先阻塞线访问,后阻塞后访问)
到这我也要临时问一个说过多次的面试送分题了:
为什么默认采用非公平锁的方式?它较公平锁方式有什么好处,又可能带来哪些问题?
知道了以上内容,结合上面表格中的方法,ArrayBlockingQueue 就可以轻松过关了
和数组相对的自然是链表了
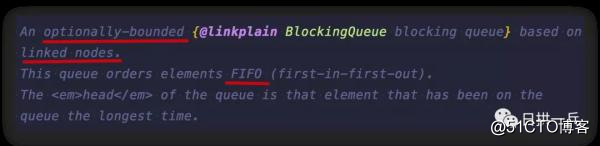
LinkedBlockingQueue 也算是一个有界阻塞队列 ,从下面的构造函数中你也可以看出,该队列的默认和最大长度为 Integer.MAX_VALUE ,这也就 docs 说 optionally-bounded 的原因了
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
} 正如 Java 集合一样,链表形式的队列,其存取效率要比数组形式的队列高。但是在一些并发程序中,数组形式的队列由于具有一定的可预测性,因此可以在某些场景中获得更高的效率
看到 LinkedBlockingQueue 是不是也有些熟悉呢?为什么要使用线程池? 就已经和它多次照面了
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
} public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
} 面试送分题又来了
使用 Executors 创建线程池很简单,为什么大厂严格要求禁用这种创建方式呢?
PriorityBlockingQueue 是一个支持优先级的***的阻塞队列,默认情况下采用自然顺序升序排列,当然也有非默认情况自定义优先级,需要排序,那自然要用到 Comparator 来定义排序规则了
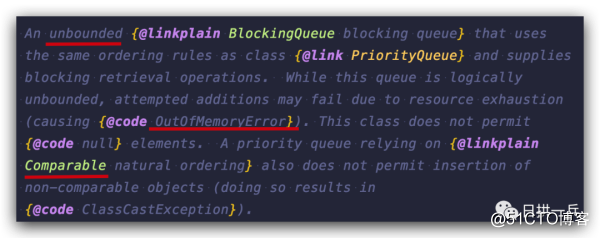
可以定义优先级,自然也就有相应的限制,以及使用的注意事项
class FIFOEntry<E extends Comparable<? super E>>
implements Comparable<FIFOEntry<E>> {
static final AtomicLong seq = new AtomicLong(0);
final long seqNum;
final E entry;
public FIFOEntry(E entry) {
seqNum = seq.getAndIncrement();
this.entry = entry;
}
public E getEntry() { return entry; }
public int compareTo(FIFOEntry<E> other) {
int res = entry.compareTo(other.entry);
if (res == 0 && other.entry != this.entry)
res = (seqNum < other.seqNum ? -1 : 1);
return res;
}
} public void put(E e) {
offer(e); // never need to block 请自行对照上面表格
} 可以给定初始容量,这个容量会按照一定的算法自动扩充
// Default array capacity.
private static final int DEFAULT_INITIAL_CAPACITY = 11;
public PriorityBlockingQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
} 这里默认的容量是 11,由于也是基于数组,那面试送分题又来了
你通常是怎样定义容器/集合初始容量的?有哪些依据?
DelayQueue 是一个支持延时获取元素的***阻塞队列
看到这也许觉得这有点和 PriorityBlockingQueue 很像,没错,DelayQueue 的内部也是使用 PriorityQueue
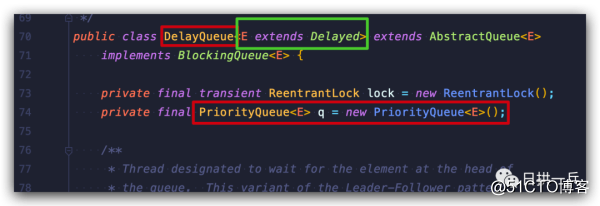
上图绿色框线也告诉你,DelayQueue 队列的元素必须要实现 Depayed 接口:

所以从上图可以看出使用 DelayQueue 非常简单,只需要两步:
实现 getDelay() 方法,返回元素要延时多长时间
public long getDelay(TimeUnit unit) {
// 最好采用纳秒形式,这样更精确
return unit.convert(time - now(), NANOSECONDS);
} 实现 compareTo() 方法,比较元素顺序
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
} 上面的代码哪来的呢?如果你打开 ScheduledThreadPoolExecutor 里的 ScheduledFutureTask,你就看到了 (ScheduledThreadPoolExecutor 内部就是应用 DelayQueue)
所以综合来说,下面两种情况非常适合使用 DelayQueue
缓存系统的设计:用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询 DelayQueue,如果能从 DelayQueue 中获取元素,说明缓存有效期到了
定时任务调度:用 DelayQueue 保存当天会执行的任务以及时间,如果能从 DelayQueue 中获取元素,任务就可以开始执行了。比如 TimerQueue 就是这样实现的
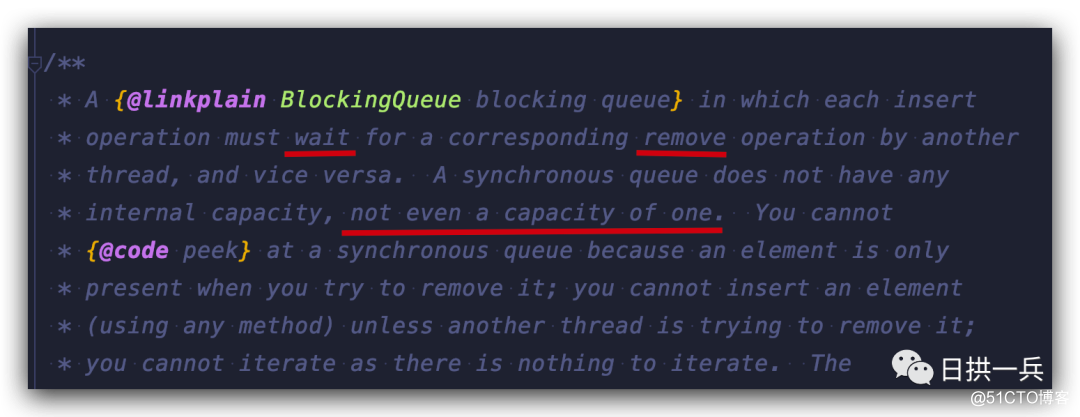
这是一个不存储元素的阻塞队列,不存储元素还叫队列?
没错,SynchronousQueue 直译过来叫同步队列,如果在队列里面呆久了应该就算是“异步”了吧
所以使用它,每个put() 操作必须要等待一个 take() 操作,反之亦然,否则不能继续添加元素
实际中怎么用呢?假如你需要两个线程之间同步共享变量,如果不用 SynchronousQueue 你可能会选择用 CountDownLatch 来完成,就像这样:
ExecutorService executor = Executors.newFixedThreadPool(2);
AtomicInteger sharedState = new AtomicInteger();
CountDownLatch countDownLatch = new CountDownLatch(1);
Runnable producer = () -> {
Integer producedElement = ThreadLocalRandom
.current()
.nextInt();
sharedState.set(producedElement);
countDownLatch.countDown();
};
Runnable consumer = () -> {
try {
countDownLatch.await();
Integer consumedElement = sharedState.get();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}; 这点小事就用计数器来实现,显然很不合适,用 SynchronousQueue 改造一下,感觉瞬间就不一样了
ExecutorService executor = Executors.newFixedThreadPool(2);
SynchronousQueue<Integer> queue = new SynchronousQueue<>();
Runnable producer = () -> {
Integer producedElement = ThreadLocalRandom
.current()
.nextInt();
try {
queue.put(producedElement);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
};
Runnable consumer = () -> {
try {
Integer consumedElement = queue.take();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}; 其实 Executors.newCachedThreadPool() 方法里面使用的就是 SynchronousQueue
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
} 看到前面 LinkedBlockingQueue 用在 newSingleThreadExecutor 和newFixedThreadPool 上,而newCachedThreadPool 却用 SynchronousQueue,这是为什么呢?
因为单线程池和固定线程池中,线程数量是有限的,因此提交的任务需要在LinkedBlockingQueue队列中等待空余的线程;
而缓存线程池中,线程数量几乎无限(上限为Integer.MAX_VALUE),因此提交的任务只需要在SynchronousQueue 队列中同步移交给空余线程即可, 所以有时也会说SynchronousQueue 的吞吐量要高于 LinkedBlockingQueue 和 ArrayBlockingQueue
简单来说,TransferQueue提供了一个场所,生产者线程使用 transfer 方法传入一些对象并阻塞,直至这些对象被消费者线程全部取出。
你有没有觉得,刚刚介绍的 SynchronousQueue 是否很像一个容量为 0 的 TransferQueue。
但 LinkedTransferQueue 相比其他阻塞队列多了三个方法
transfer(E e)如果当前有消费者正在等待消费元素,transfer 方法就可以直接将生产者传入的元素立刻 transfer (传输) 给消费者;如果没有消费者等待消费元素,那么 transfer 方法会把元素放到队列的 tail(尾部)
节点,一直阻塞,直到该元素被消费者消费才返回
tryTransfer,很显然是一种尝试,如果没有消费者等待消费元素,则马上返回 false ,程序不会阻塞
带有超时限制,尝试将生产者传入的元素 transfer 给消费者,如果超时时间到,还没有消费者消费元素,则返回 false
你瞧,所有阻塞的方法都是一个套路:
看到这你也许感觉 LinkedTransferQueue 没啥特点,其实它和其他阻塞队列的差别还挺大的:
BlockingQueue 是如果队列满了,线程才会阻塞;但是 TransferQueue 是如果没有消费元素,则会阻塞 (transfer 方法)
这也就应了 Doug Lea 说的那句话:
LinkedTransferQueue is actually a superset of ConcurrentLinkedQueue, SynchronousQueue (in “fair” mode), and unboundedLinkedBlockingQueues. And it’s made better by allowing you to mix and match those features as well as take advantage of higher-performance i mplementation techniques.
简单翻译:LinkedTransferQueue 是ConcurrentLinkedQueue, SynchronousQueue (在公平模式下), ***的LinkedBlockingQueues等的超集; 允许你混合使用阻塞队列的多种特性
所以,在合适的场景中,请尽量使用LinkedTransferQueue上面都看的是单向队列 FIFO,接下来我们看看双向队列
LinkedBlockingDeque 是一个由链表结构组成的双向阻塞队列,凡是后缀为 Deque 的都是双向队列意思,后缀的发音为deck——/dek/, 刚接触它时我以为是这个冰激凌的发音

所谓双向队列值得就是可以从队列的两端插入和移除元素。所以:
双向队列因为多了一个操作队列的入口,在多线程同时入队是,也就会减少一半的竞争
队列有头,有尾,因此它又比其他阻塞队列多了几个特殊的方法

这么一看,双向阻塞队列确实很高效,
那双向阻塞队列应用在什么地方了呢?
不知道你是否听过 “工作窃取”模式,看似不太厚道的一种方法,实则是高效利用线程的好办法。下一篇文章,我们就来看看 ForkJoinPool 是如何应用 “工作窃取”模式的
到这关于 Java 队列(其实主要介绍了阻塞队列)就快速的区分完了,将看似杂乱的方法做了分类整理,方便快速理解其用途,同时也说明了这些队列的实际用途。相信你带着更高的视角来阅读源码会更加轻松,最后也希望大家认真看两个队列的源码实现,在遇到队列的问题,脑海中的画面分分钟就可以搞定了
本文转载自微信公众号「 日拱一兵」,可以通过以下二维码关注。转载本文请联系 日拱一兵公众号。

【编辑推荐】
如何理解JavaScript中的对象?
JavaScript:为什么命名参数比位置参数更好
2021编程语言「后浪」趋势预测:JavaScript、Python热度不减,但崛起最快的却是它
分析网页 JavaScript Bundles 的几种方法
微服务,Java目前很火热的系统架构
【责任编辑:武晓燕 TEL:(010)68476606】
标签:== fixed obj gate 多线程 rman 传输 boolean 编辑
原文地址:https://blog.51cto.com/14887308/2524122