标签:and png const 特定 方差 核心 整理 状态 为我
之前说到了贝叶斯滤波的原理和计算,最终我们发现,贝叶斯滤波在预测步和更新步,每一轮都需要进行多次无穷积分,这就要求我们清楚的知道每一步需要的概率密度函数,这样实在难以求解甚至无解析解,于是人们想了一些办法来解决。
为了求解贝叶斯滤波,人们的方法主要分成两种:
智力派:核心思想是做出假设,在一些特定情况下,是可以让贝叶斯滤波的计算大大简化的,回顾一下我们在之前贝叶斯滤波内容里的起点:
如果我们的状态方程的f(Xk-1),观测方程中的h(Xk)都是线性方程,Qk和Rk依旧是正态分布的噪声,那么我们就可以把它改写成这种形式:
这种假设下,我们就得到了卡尔曼滤波(KF)。
但是这种假设太强了,很多情况下我们的f(Xk-1),h(Xk)都是非线性的,但是依旧有办法,将其近似为线性计算,这样我们就得到了非线性的卡尔曼滤波:扩展卡尔曼滤波(EKF)和无迹卡尔曼滤波(UKF)。
莽夫派:核心思想是硬算,直接对无穷积分作数值积分。比如高斯积分,蒙特卡洛积分(粒子滤波),直方图滤波(将密度函数转为直方图进行积分)。
这里我们要说的是卡尔曼滤波,就先不管莽夫派的算法啦。
回顾一下贝叶斯滤波的思想,我们为了解决随机过程中的状态估计问题,首先需要两个方程:
然后我们通过两步来进行状态估计,首先是预测步,我们通过初值,或前一时刻的后验,来求出这一时刻的先验:
之后是更新步,我们通过这一时刻的先验,以及观测方程,计算出这一时刻的后验,来作为此时的估计结果:
在卡尔曼滤波中,我们假设:
f(Xk-1),h(Xk)是线性函数,即 f(Xk-1) = F·Xk-1,h(Xk) = H·Xk
Qk和Rk服从正态分布,Qk ~ N(0, Q),Rk ~ N(0, R)
我们假设Xk-1 ~ N(μk-1+, σk-1+)那么预测步:
看起来有些复杂,实际上它还是一个正态分布,且服从:
这就是先验的概率分布情况了,我们记它为N(μk-, σk-),那么更新步:
看起来还是很复杂的一坨,实际上它依旧是一个正态分布,且服从:
我们将它记为N(μk+, σk+),整理一下:
我们发现他们都有相同的部分,于是我们定义一个K:
这就是卡尔曼增益。这里我们可能发现了一些卡尔曼滤波之所以比贝叶斯滤波简化了运算的原因:
最后我们再整理一下卡尔曼滤波的过程:
预测步:
更新步:
这里我们把卡尔曼增益K写了两种写法,我们看一下第二种写法:
当R>>σk-时,K趋近于0,这时我们的期望:
意味着我们更倾向于相信预测。
当R<<σk-时,K趋近于 1/H,这时我们的期望:
意味着我们更倾向于相信观测。
可以看到它也很好地保留了贝叶斯滤波的“滤波”特性。
但是我们在实际使用中,最长使用的是矩阵形式的卡尔曼滤波,接下来由上面的公式改写成矩阵形式吧~
在矩阵形式的计算中,我们的期望将不再是一个数字标量,而是一个向量。方差也将变成协方差矩阵,状态方程与观测方程中的F和H,也将变成矩阵F和H,我们加粗表示。
那么预测步:
更新步:
接下来我们写一个小demo,来演示一下,对于一个含有正态噪声的型号,卡尔曼滤波如何处理。
我们来手撸一个简单的卡尔曼滤波器,这次滤波器的Demo里,我们的真实值取:
我们假设它是一个随时间二次增长的值,因为是模拟,观测部分我们直接在真实值上添加一个正态噪声,来进行模拟,由于我们的观测值就是类似温度计直接测量温度那样,所以我们的观测方程:
我们的状态方程,我们先粗糙的建立一个模型(虽然上面我们为了模拟,给出了真实值,但实际上我们是不知道状态是如何变化的):
思考一下我们需要计算的内容:
预测步:
我们需要计算这两项内容,其中F我们在上面已经设置为1,第一次的先验分布我们自己设置初值,后续均由递推获得:
后验的均值:X_k_minus = F * X_pre_plus
方差:P_k_minus = F*F * P_pre_plus
更新步:
我们需要计算这三项内容:
卡尔曼增益:K = P_k_minus * H / (H*H * P_k_minus + R)
先验的均值:X_k_plus = X_k_minus + K*(Y_k - H * X_k_minus)
方差: P_k_plus = (1 - K*H) * P_k_minus */
其中H我们也已经设置为1,状态方程与观测方程的噪声Q,R我们在程序中设置,后验由更新步计算得出。
接下来是完整代码(C++):
#include <iostream>
#include <random>
#include <vector>
using namespace std;
void kalmanFilter(const vector<float>& srcX,const vector<float>& Y, vector<float>& plusX){
/* 观测方程Y(X_k) = H(X_k) + R:
* 由于提供模拟观测数据,这里直接使用模拟数据, 由于模拟观测是直接由真值加噪声获得,取H = 1,R是均值为0,方差为1的正态噪声
* 状态方程:X_k = F * X_k-1 + Q
* 我们设状态方程为线性方程,且F = 1, Q是均值为0,方差为1的正态噪声 */
float F = 1.0, Q = 1.0, H = 1.0, R= 1.0;
// 初始值,假设X0~N(0.01, 0.01^2)
plusX[0] = 0.01;
float plusP = 0.0001;
/* 后验的均值:X_k_minus = F * X_pre_plus
* 方差:P_k_minus = F*F * P_pre_plus
* 卡尔曼增益:K = P_k_minus * H / (H*H * P_k_minus + R)
* 先验的均值:X_k_plus = X_k_minus + K*(Y_k - H * X_k_minus)
* 方差: P_k_plus = (1 - K*H) * P_k_minus */
float minusX, minusP, K; // plusX在数组更新,plusP已经在初始值处定义
for(size_t i = 1; i < srcX.size(); i++){
minusX = F * plusX[i-1];
minusP = F*F * plusP + Q;
K = minusP * H / (H*H * minusP + R);
plusX[i] = minusX + K * (Y[i] - H * minusX);
plusP = (1 - K * H) * minusP;
}
}
int main() {
/* 真实数据X = n^2,保存到srcX
* 在真实数据上添加正态噪声,保存到Y,作为模拟观测
* 共 50 个数据 */
vector<float> srcX;
vector<float> Y;
float n = 0.02;
default_random_engine gen;
//观测噪声的均值与方差
normal_distribution<float> dis(0,0.1);
while(n <= 1.0){
srcX.push_back(n*n);
Y.push_back(n*n + dis(gen));
n += 0.02;
}
// 保存滤波结果的数组
vector<float> plusX(srcX.size(), 0);
kalmanFilter(srcX, Y, plusX);
/*
* Do something with ur srcX, Y ,pulsX.
*/
return 0;
}
在上面的程序里,我们的观测方程与状态方程的噪声均设置为N(0,1),我们来看一下结果:
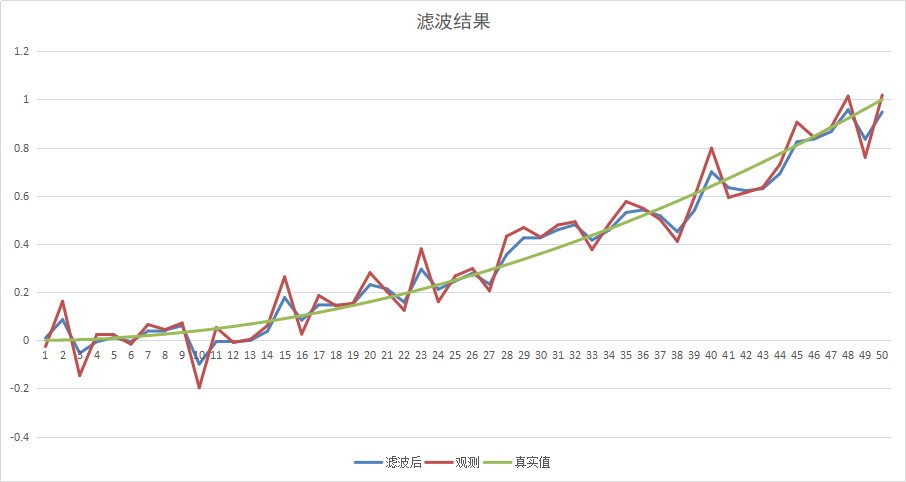
呃…… 似乎效果不怎么好,因为我们对于状态方程的建模太过粗糙了,并且我们的状态方程的噪声设置与观测方程一样,我们试一试将状态方程的噪声Q设置为N(0,0.01),再来试一下:
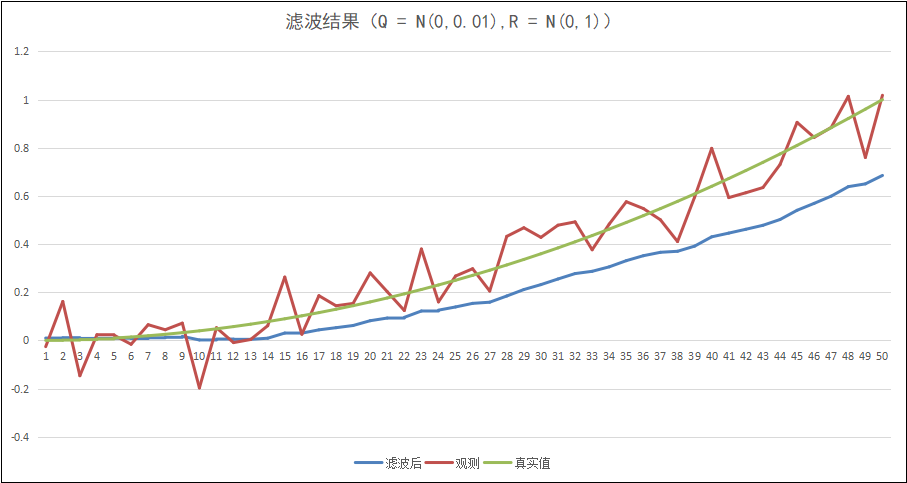
似乎平滑了很多,但是在曲线结尾,偏差越来越大。这是由于我们给Q设置了较小的方差,导致滤波器更偏向于相信预测值,然而真实值是一个平方函数,这就不是我们目前,粗糙建模的状态方程能预测的准的了。
而相对的,如果我们把R设置为N(0,0.01),那么:
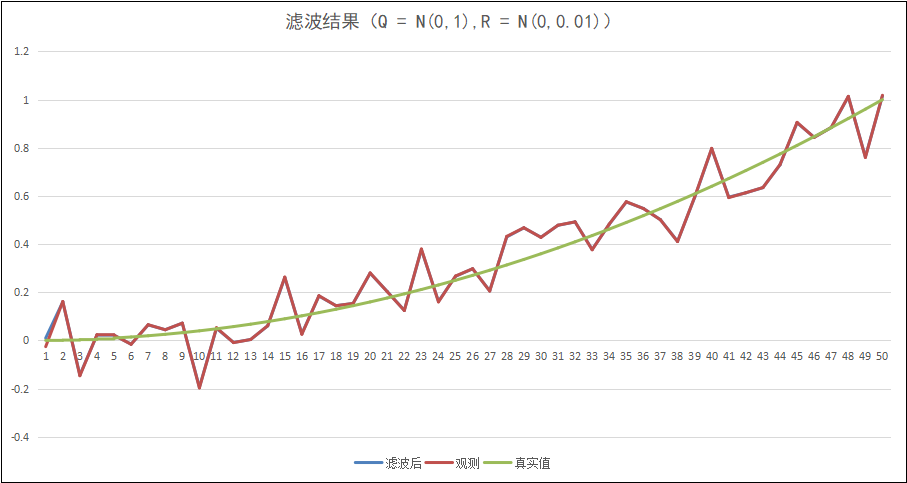
滤波器将非常倾向于观测值,滤波后的结果几乎与观测值一致了。
之前在贝叶斯滤波那里就曾经说过,初值的选择对滤波结果的影响不大,假设我们的初值定为5,那么:
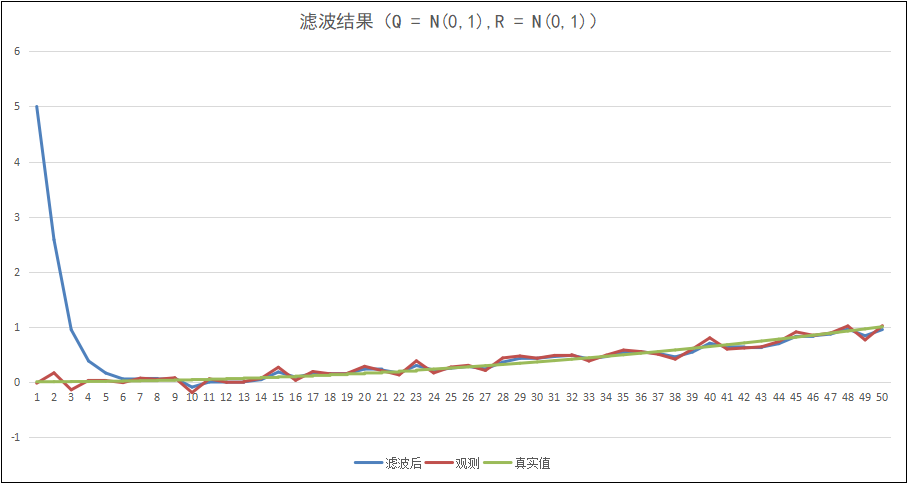
可以看出,实际上在三四轮计算后,我们的滤波结果又趋近于真实值了,可能这就是贝叶斯滤波的强大之处了吧。
不过在开头处,我们说过,很多情况下,状态方程与观测方程其实是非线性的,也就无法简单的使用卡尔曼滤波,那么,就需要扩展卡尔曼滤波的登场啦!
忠厚老实的王大头,https://space.bilibili.com/287989852
(宝藏up,强烈推荐)
滤波算法02. 卡尔曼滤波 —— 贝叶斯滤波太难算了我们简化一下吧
标签:and png const 特定 方差 核心 整理 状态 为我
原文地址:https://www.cnblogs.com/blb0803/p/13564846.html