标签:之间 异步执行 opera 设置 扩展名 txt 文件处理 err 特定
处理文件是我们每天最常见的任务之一。Python具有几个用于执行文件操作的内置模块,例如读取文件,移动文件,获取文件属性等。本文总结了您需要了解的许多功能,以涵盖Python中最常见的文件操作和良好做法。
这是您将在本文中看到的模块/功能图。 要了解有关每个操作的更多信息,请继续阅读。
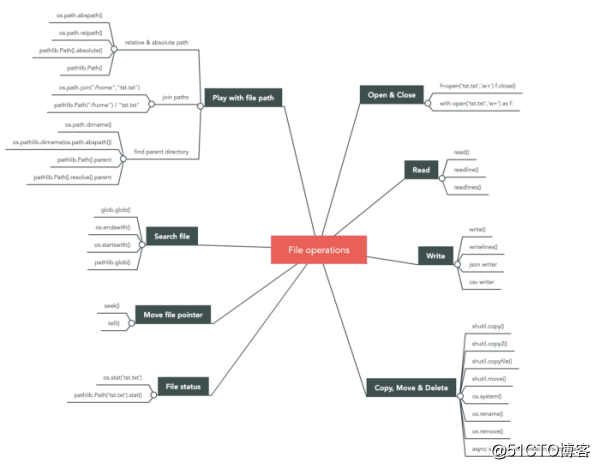
图1. 由xiaoxu guo 提供
一、打开和关闭文件
当您要读取或写入文件时,首先要做的就是打开文件。 Python具有打开的内置函数,该函数打开文件并返回文件对象。 文件对象的类型取决于打开文件的模式。 它可以是文本文件对象,原始二进制文件和缓冲的二进制文件。 每个文件对象都有诸如read()和write()之类的方法。
该代码块中有问题,您能识别出来吗? 我们将在后面讨论。
file = open("test_file.txt","w+")
file.read()
file.write("a new line")Python文档列出了所有可能的文件模式。 表中列出了最常见的模式。 一个重要的规则是,任何与w相关的模式都将首先截断该文件(如果存在),然后创建一个新文件。 如果您不想覆盖文件,请谨慎使用此模式,并尽可能使用附加模式
mode meaning
r 打开以供阅读(默认)
r+ 为读取和写入打开(文件指针位于文件的开头)
w 打开进行写入(如果存在则截断文件)
w+ 可以同时进行读写(截断文件,如果存在的话)
a 开放写操作(如果存在,追加到文件末尾,并且文件指针位于文件末尾)上一个代码块中的问题是我们只打开了文件,但没有关闭文件。 在处理文件时始终关闭文件很重要。 拥有打开的文件对象可能会导致不可预测的行为,例如资源泄漏。 有两种方法可以确保正确关闭文件。
****1. 使用close()
第一种方法是显式使用close()。 一个好的做法是将其放入最后,以便我们可以确保在任何情况下都将关闭该文件。 它使代码更加清晰,但另一方面,开发人员应该承担责任,不要忘记关闭它。
try:
file = open("test_file.txt","w+")
file.write("a new line")
exception Exception as e:
logging.exception(e)
finally:
file.close() 2. 使用上下文管理器,将open(...)设置为f
第二种方法是使用上下文管理器。 如果您不熟悉上下文管理器,那么请查阅Dan Bader用Python编写的上下文管理器和“ with”语句。 与open()一起使用,因为f语句实现enter和exit方法来打开和关闭文件。 此外,它将try / finally语句封装在上下文管理器中,这意味着我们将永远不会忘记关闭文件。
with open("test_file","w+") as file:
file.write("a new line") 这个上下文管理器解决方案是否总是比close()更好? 这取决于您在哪里使用它。 以下示例实现了将50,000条记录写入文件的3种不同方式。 从输出中可以看到,use_context_manager_2()函数与其他函数相比性能极低。 这是因为with语句在单独的函数中,它基本上为每个记录打开和关闭文件。 这种昂贵的I / O操作会极大地影响性能。
def _write_to_file(file, line):
with open(file, "a") as f:
f.write(line)
def _valid_records():
for i in range(100000):
if i % 2 == 0:
yield i
def use_context_manager_2(file):
for line in _valid_records():
_write_to_file(file, str(line))
def use_context_manager_1(file):
with open(file, "a") as f:
for line in _valid_records():
f.write(str(line))
def use_close_method(file):
f = open(file, "a")
for line in _valid_records():
f.write(str(line))
f.close()
use_close_method("test.txt")
use_context_manager_1("test.txt")
use_context_manager_2("test.txt")
# Finished ‘use_close_method‘ in 0.0253 secs
# Finished ‘use_context_manager_1‘ in 0.0231 secs
# Finished ‘use_context_manager_2‘ in 4.6302 secs打开文件后,您必须要读取或写入文件。文件对象提供了三种读取文件的方法,分别是read(),readline()和readlines()。
默认情况下,read(size = -1)返回文件的全部内容。如果文件大于内存,则可选参数size可以帮助您限制返回的字符(文本模式)或字节(二进制模式)的大小。
readline(size = -1)返回整行,最后包括字符\ n。如果size大于0,它将从该行返回最大字符数。
readlines(hint = -1)返回列表中文件的所有行。可选参数hint表示如果返回的字符数超过了hint,则将不返回任何行。
在这三种方法中,read()和readlines()的内存效率较低,因为默认情况下,它们以字符串或列表形式返回完整的文件。一种更有效的内存迭代方式是使用readline()并使其停止读取,直到返回空字符串。空字符串“”表示指针到达文件末尾。
with open(‘test.txt‘, ‘r‘) as reader:
line = reader.readline()
while line != "":
line = reader.readline()
print(line)在编写方面,有两种方法write()和writelines()。 顾名思义,write()是写一个字符串,而writelines()是写一个字符串列表。 开发人员有责任在末尾添加\ n。
with open("test.txt", "w+") as f:
f.write("hi\n")
f.writelines(["this is a line\n", "this is another line\n"])
# >>> cat test.txt
# hi
# this is a line
# this is another line 如果您将文本写入特殊的文件类型(例如JSON或csv),则应在文件对象顶部使用Python内置模块json或csv。
import csv
import json
with open("cities.csv", "w+") as file:
writer = csv.DictWriter(file, fieldnames=["city", "country"])
writer.writeheader()
writer.writerow({"city": "Amsterdam", "country": "Netherlands"})
writer.writerows(
[
{"city": "Berlin", "country": "Germany"},
{"city": "Shanghai", "country": "China"},
]
)
# >>> cat cities.csv
# city,country
# Amsterdam,Netherlands
# Berlin,Germany
# Shanghai,China
with open("cities.json", "w+") as file:
json.dump({"city": "Amsterdam", "country": "Netherlands"}, file)
# >>> cat cities.json
# { "city": "Amsterdam", "country": "Netherlands" } 1. 在文件内移动指针
当我们打开文件时,我们得到一个指向特定位置的文件处理程序。 在r和w模式下,处理程序指向文件的开头。 在一种模式下,处理程序指向文件的末尾。
(1) tell()和seek()
当我们从文件中读取时,指针将移动到下一个读取将开始的位置,除非我们告诉指针移动。 您可以使用2种方法来做到这一点:tell()和seek()。
tell()以文件开头的字节数/字符数的形式返回指针的当前位置。 seek(offset,whence = 0)将处理程序移到一个位置,offset字符距离wherece。 地点可以是:
在文本模式下,wherece仅应为0,偏移应≥0。
with open("text.txt", "w+") as f:
f.write("0123456789abcdef")
f.seek(9)
print(f.tell()) # 9 (pointer moves to 9, next read starts from 9)
print(f.read()) # 9abcdef 2. 了解文件状态
操作系统上的文件系统可以告诉您许多有关文件的实用信息。 例如,文件的大小,创建和修改的时间。 要在Python中获取此信息,可以使用os或pathlib模块。 实际上,os和pathlib之间有很多共同之处。 pathlib是比os更面向对象的模块。
3. 操作系统
获取完整状态的一种方法是使用os.stat(“ test.txt”)。 它返回具有许多统计信息的结果对象,例如st_size(文件大小,以字节为单位),st_atime(最新访问的时间戳),st_mtime(最新修改的时间戳)等。
print(os.stat("text.txt"))
>>> os.stat_result(st_mode=33188, st_ino=8618932538,
st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=16, st_atime=1597527409,
st_mtime=1597527409, st_ctime=1597527409) 您也可以使用os.path单独获取统计信息。
os.path.getatime()
os.path.getctime()
os.path.getmtime()
os.path.getsize() 获取完整状态的另一种方法是使用pathlib.Path(“ text.txt”)。stat()。 它返回与os.stat()相同的对象。
print(pathlib.Path("text.txt").stat())
>>> os.stat_result(st_mode=33188, st_ino=8618932538, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=16, st_atime=1597528703, st_mtime=1597528703, st_ctime=1597528703)
>>> 在以下各节中,我们将比较os和pathlib的更多方面。
Python有许多内置模块来处理文件移动。 在您信任Google返回的第一个答案之前,您应该意识到,不同的模块选择会导致不同的性能。 一些模块将阻塞线程,直到文件移动完成,而其他模块则可能异步执行。
1. 关闭
shutil是用于移动,复制和删除文件和文件夹的最著名的模块。 它提供了4种仅复制文件的方法。 copy(),copy2()和copyfile()。
copy()与 copy2():copy2()与copy()非常相似。 不同之处在于copy2()还复制文件的元数据,例如最近的访问时间,最近的修改时间。 但是根据Python文档,由于操作系统的限制,即使copy2()也无法复制所有元数据。
shutil.copy("1.csv", "copy.csv")
shutil.copy2("1.csv", "copy2.csv")
print(pathlib.Path("1.csv").stat())
print(pathlib.Path("copy.csv").stat())
print(pathlib.Path("copy2.csv").stat())
# 1.csv
# os.stat_result(st_mode=33152, st_ino=8618884732, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570395, st_mtime=1597259421, st_ctime=1597570360)
# copy.csv
# os.stat_result(st_mode=33152, st_ino=8618983930, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570387, st_mtime=1597570395, st_ctime=1597570395)
# copy2.csv
# os.stat_result(st_mode=33152, st_ino=8618983989, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570395, st_mtime=1597259421, st_ctime=1597570395)
2. 367/5000
copy()与 copyfile():copy()将新文件的权限设置为与原始文件相同,但是copyfile()不会复制其权限模式。 其次,copy()的目标可以是目录。 如果存在同名文件,则将其覆盖,否则,将创建一个新文件。 但是,copyfile()的目的地必须是目标文件名。
shutil.copy("1.csv", "copy.csv")
shutil.copyfile("1.csv", "copyfile.csv")
print(pathlib.Path("1.csv").stat())
print(pathlib.Path("copy.csv").stat())
print(pathlib.Path("copyfile.csv").stat())
# 1.csv
# os.stat_result(st_mode=33152, st_ino=8618884732, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570395, st_mtime=1597259421, st_ctime=1597570360)
# copy.csv
# os.stat_result(st_mode=33152, st_ino=8618983930, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570387, st_mtime=1597570395, st_ctime=1597570395)
# copyfile.csv
# permission (st_mode) is changed
# os.stat_result(st_mode=33188, st_ino=8618984694, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=11, st_atime=1597570387, st_mtime=1597570395, st_ctime=1597570395)
shutil.copyfile("1.csv", "./source")
# IsADirectoryError: [Errno 21] Is a directory: ‘./source‘ 3. os
os模块具有一个system()函数,允许您在子shell中执行命令。 您需要将该命令作为参数传递给system()。 这与在操作系统上执行的命令具有相同的效果。 为了移动和删除文件,您还可以在os模块中使用专用功能。
# copy
os.system("cp 1.csv copy.csv")
# rename/move
os.system("mv 1.csv move.csv")
os.rename("1.csv", "move.csv")
# delete
os.system("rm move.csv") 4. 异步复制/移动文件
到目前为止,解决方案始终是同步的,这意味着如果文件很大并且需要更多时间移动,则程序可能会被阻止。 如果要使程序异步,则可以使用threading,multiprocessing或subprocess模块使文件操作在单独的线程或单独的进程中运行。
import threading
import subprocess
import multiprocessing
src = "1.csv"
dst = "dst_thread.csv"
thread = threading.Thread(target=shutil.copy, args=[src, dst])
thread.start()
thread.join()
dst = "dst_multiprocessing.csv"
process = multiprocessing.Process(target=shutil.copy, args=[src, dst])
process.start()
process.join()
cmd = "cp 1.csv dst_subprocess.csv"
status = subprocess.call(cmd, shell=True) 复制和移动文件后,您可能需要搜索与特定模式匹配的文件名。 Python提供了许多内置函数供您选择。
1. glob
glob模块根据Unix shell使用的规则查找与指定模式匹配的所有路径名。 它支持通配符,例如*?。 []。
glob.glob(“ *。csv”)搜索当前目录中所有具有csv扩展名的文件。 使用glob模块,还可以在子目录中搜索文件。
>>> import glob
>>> glob.glob("*.csv")
[‘1.csv‘, ‘2.csv‘]
>>> glob.glob("**/*.csv",recursive=True)
[‘1.csv‘, ‘2.csv‘, ‘source/3.csv‘] 2. os
os模块是如此强大,以至于它基本上可以执行文件操作。 我们可以简单地使用os.listdir()列出目录中的所有文件,并使用file.endswith()和file.startswith()来检测模式。 如果要遍历目录,请使用os.walk()。
import os
for file in os.listdir("."):
if file.endswith(".csv"):
print(file)
for root, dirs, files in os.walk("."):
for file in files:
if file.endswith(".csv"):
print(file) 3. pathlib
pathlib具有与glob模块类似的功能。 也可以递归搜索文件名。 与以前的基于os的解决方案相比,pathlib具有更少的代码,并且提供了更多的面向对象的解决方案。
使用文件路径是我们执行的另一项常见任务。 它可以获取文件的相对路径和绝对路径。 它也可以连接多个路径并找到父目录等。
os和pathlib都提供了获取文件或目录的相对路径和绝对路径的功能。
import os
import pathlib
print(os.path.abspath("1.txt")) # absolute
print(os.path.relpath("1.txt")) # relative
print(pathlib.Path("1.txt").absolute()) # absolute
print(pathlib.Path("1.txt")) # relative 这是我们可以独立于环境连接os和pathlib中的路径的方式。 pathlib使用斜杠创建子路径。
import os
import pathlib
print(os.path.join("/home", "file.txt"))
print(pathlib.Path("/home") / "file.txt")dirname()是在os中获取父目录的函数,而在pathlib中,您可以仅使用Path()。parent来获取父文件夹。
import os
import pathlib
# relative path
print(os.path.dirname("source/2.csv"))
# source
print(pathlib.Path("source/2.csv").parent)
# source
# absolute path
print(pathlib.Path("source/2.csv").resolve().parent)
# /Users/<...>/project/source
print(os.path.dirname(os.path.abspath("source/2.csv")))
# /Users/<...>/project/source最后但并非最不重要的一点是,我想简要介绍一下os和pathlib。 如Python文档所述,pathlib是比os更面向对象的解决方案。 它将每个文件路径表示为适当的对象,而不是字符串。 这给开发人员带来了很多好处,例如,使连接多个路径变得更加容易,在不同的操作系统上更加一致,并且可以直接从对象访问方法。
我希望本文可以提高您处理文件的效率。
原英文链接:
【编辑推荐】
【责任编辑:赵宁宁 TEL:(010)68476606】
标签:之间 异步执行 opera 设置 扩展名 txt 文件处理 err 特定
原文地址:https://blog.51cto.com/14887308/2523017