标签:返回 图片 正是 重要 redo logs 合并 normal 免费
【摘要】 升级后的华为云GaussDB,如何用技术服人?数据存储、迁移和容灾备份,这些技术窍门你必须知道!
相信很多人都有整理C盘的经历,C盘作为电脑的系统盘,系统运行所需的关键数据都存储在其中。但如果使用不当,C盘就特别容易变红,然后电脑变卡,恶性循环,最差的结局就是系统崩溃,所有数据丢失。
对于企业来说,数据存储和管理更是关乎生存的大事。
如今的企业数据量大、数据来源多样、数据形态复杂,原有的存储模式已经无法满足需求,反而会加重存储负担。
所以,磨刀不误砍柴工,你们企业的数据存储做好了吗?巧妇难为无米之炊,你们业务的瓶颈是不是可以从数据存储管理的维度打破?
从最早的穿孔卡片、关系数据库、非关系数据库到如今的云数据库,Gartner研究报告称到2023年,全球75%的数据都会出现在云平台上。
数据上云四个字打出来容易,但真正落实下来却存在各种困难。
第一重要的环节便是数据存储,就像建高楼一样,打好地基是关键,只有把数据存储这个环节做到极致,业务才能快马加鞭跑起来。
目前,不少云服务厂商都推出了数据库产品,在去IOE的路上一路狂奔。
而一个优秀的数据存储产品,既要给足安全感,还要够便宜,让数据存储不再是负担,而是业务的催化剂。
目前,从结构化/非结构化数据的存储、到数据的复制迁移、灾备以及预处理,华为云给数据上云的每个环节,都填满了相应的产品。
无论什么业务场景,都可以在短时内完成数据库的部署,实现云端完全托管。
而之所以能做到又快又全又便宜,华为云的这些技术绝招功不可没,且听我们慢慢道来。
如果将数据库比喻成“城市”,我们可以理解DRS(数据复制服务)便是城市之间的“地底光纤”,确保将“始发地”源库的数据安全、快速、高效地运输到“目的地”目标库。
为了保障数据库迁移过程中数据的一致性,一种方式是需要停掉业务,进行一次性迁移(也称离线迁移),这就造成了数据量越大,迁移时间越长,也就意味着停机时间越久。
那么是否有一种方式既能保障数据库迁移过程中数据的一致性,又能做到业务持续运行?
DRS通过全量迁移+增量同步的方式(也称在线迁移),在全量迁移完成后,启动增量同步过程。
增量同步是将源库先进行日志解析,日志可以很形象的看成是“录像带”,记录了源库的所有操作,我们将日志“回放”出来,源库做了什么数据操作,目标库就做什么样的操作,最终这部分增量数据被并行复制到目标库,来保证数据的一致性。整个过程可以理解为在业务运行的过程中,潜移默化地完成了源库与目标库之间的数据迁移,业务无感知。
原本只能是数据库迁移专家才能完成的复杂数据库迁移如今在云上变得轻松简单,普通的从业者也能完成云上数据库高效迁移,极大便利了客户、一线运维人员和开发者。
但也有人会极度缺乏安全,一旦数据没有放在自己的眼皮底下,担忧总是无尽的。
在迁移上云后,数据备份和恢复的问题一直困扰中型企业。老板总是会担心,我的数据都放在你们服务器里,哪天你们机房发生地震,我的数据怎么办?
首先,华为云数据库很早便推出了双AZ高可用灾备方案,即“同城两中心”,也就是在同城建立两个数据库,当其中一个数据库突发异常或被破坏时,可以从另一个数据库获取数据,以保证系统的持续稳定。
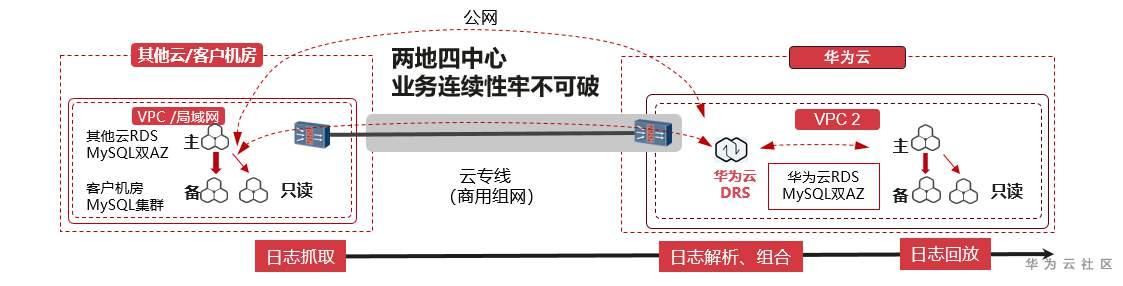
华为云数据库在“同城两中心”的基础上提出了异地保护的方案,DRS推出了异地多活灾备,即“两地四中心”。
该灾备方案支持搭建主备高可用架构,当主实例所在区域突发自然灾害等状况,主备节点均无法连接时,可将异地灾备实例切换为主实例,即可快速恢复应用的业务访问,而且可以实现主实例和跨区域的灾备实例之间的实时同步。
华为云数据库产品不得不提的一个特点就是弹性扩容,业务无感知。
以GaussDB(for MySQL)为例,其基于华为最新一代DFV分布式存储,采用计算存储分离架构。
当计算和存储解耦,再利用云架构弹性的优势,存储和计算均可单独按需扩缩容,且在分钟内完成,资源利用率达到最大化。
GaussDB(for MySQL)还支持1写15读的只读节点的极速扩展,最高支持128TB的海量存储,可实现超百万级QPS吞吐,单节点相比原生MySQL性能提升7倍,而且兼容MySQL,无需分库分表,应用无需改造即可轻松迁移上云。
另外,GaussDB(for MySQL)数据库在写入性能上,在业界同类产品中是最好的,这主要得益于它在MySQL内核方面的诸多优化,其中有一项便是从“送快递”得来灵感的优化——事务异步提交。
快递的配送过程中,最耗时的,不是装货、卸货,而是电话和等待。快递驿站可以很大程度解决这个问题。
同样,事务处理过程中,存储的IO就是一个较长的等待。
数据库使用经验丰富的开发人员来都知道,等待redo日志写入存储的磁盘IO性能,很大程度上决定了数据库的写入性能。
对于GaussDB(for MySQL)这样存算分离的数据库,存储的IO耗时在事务处理的总耗时中占据不小比例,虽然有log buffer的合并写入,提升并发情况下的整体吞吐,但如果在等待IO时间内,这些线程能够去做别的事情(例如处理等待中的其他事务),那么将会有进一步的性能提升。
既然找到了等待的点,那么我们就可以像快递配送的优化方法,为数据库创造一个“快递驿站”。
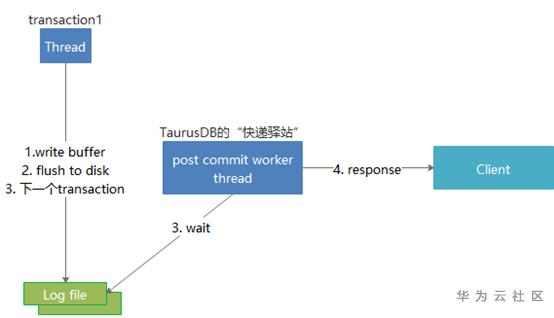
图: GaussDB(for MySQL)的“快递驿站”
如图所示,当redo日志的flush to disk动作完成后,即可进行事务提交,但是此时并不应答客户端,而是直接处理下一个事务。同时使用少量post comit worker线程,来批量等待日志写入完成(等待的过程其实并不占用CPU),并应答客户端,这就可以让“等待”和“下一个事务的处理”并行化,让CPU“闲不下来”。
在标准的sysbench写入模型下,没有使用Post Commit时极限性能是35万QPS左右,而使用Post commit后可以到大42万以上的QPS,提升了20%的写入性能。
数据上云后,企业对云上数据库的要求也越来越高,尤其是数据的完整可靠。
有的云厂商为了保证事务不丢失,选择增加一个数据库结点的方式,但成本也相应提高。
有没有一种两全其美的方法,既能保证数据零丢失,还能降低成本?
华为云数据库MySQL高可靠的应用机制可以做到:主备模式下,在最大程度保证主库效率的同时,保证主库崩溃时快速恢复服务,并且做到事务零丢失,进而保证企业业务的稳定持续。
华为云数据库MySQL半同步复制基于状态通道和时间戳的高可靠特性,总体上是管控节点(HA)保存主库最后的复制状态和时间戳,备实例保存主库最后的复制状态和时间戳,然后通过比较它们来精准判断主库崩溃时的复制状态。
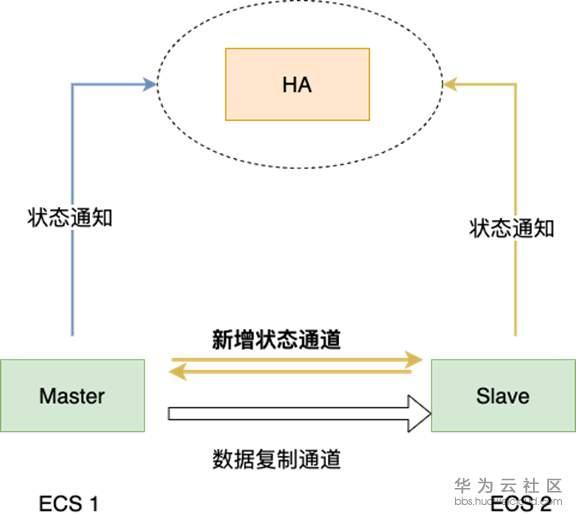
在自行恢复方面,它可以根据主库崩溃时的复制状态按照以下四种情况准确恢复服务,保证不丢失事务,并且秒级恢复服务:
华为云数据库MySQL半同步复制高可靠特性能最大程度保证主库效率,是因为主库的事务提交只依赖于备库,而备库把这个事务写入中继日志后立即返回一个ACK(即确认字符),没有强同步复制备库回放事务带来的延迟。
举个例子,如果用户买了华为云数据库MySQL,当半同步复制主库正在执行大事务,并且复制状态从同步复制转换到异步复制时,主库突然挂掉,用户服务被迫中断,华为云数据库MySQL主库会在秒级内被拉起对外提供服务,用户可以重新连接上华为云数据库,并且与中断前的数据视图完全一致,没有事务丢失。
水是万物之源,数据就是互联网之源。作为计算机的三驾马车之一,数据库是承载互联网之源的关键。
828企业上云节期间,华为云的数据存储产品也推出了优惠活动,正是企业入手云数据库的最佳时机。
如果要存储处理结构化数据,有云数据库 MySQL、云数据库 PostgreSQL和GaussDB(for MySQL);
如果是非结构化数据,有OBS对象存储服务、文档数据库DDS以及MapReduce服务,还有Redis、Kafka等中间件,从数据存储、数据入湖、灾备到分析,无论什么业务场景,总有一款产品最适合你。
标签:返回 图片 正是 重要 redo logs 合并 normal 免费
原文地址:https://www.cnblogs.com/huaweiyun/p/13569850.html