标签:时间复杂度 htm 验证 null byte ret code ram 分区
UTF8编码转换为GB2312编码字符集时,需要明确以下两点:
UTF8是编码格式,而GB2312是字符集,UTF8可以动态的表示1到6字节的编码范围,其还原后可以是双字节Unicode UTF16(USC2)字符集,也可以是四字节Unicode UTF32(USC4)字符集,四字节以上的很少用到可以不做兼容处理。
这两种编码是完全不兼容的,因此他们之间的转换无法通过既有规则形成公式之间计算,仅能通过LUT(look up table)查找表模式实现;这也就意味着必须先准备一张包含UTF8编码下的字符对应GB2312字符集下字符的表。
GB2312字符集概述:
GB2312字符集通常指GB2312-80格式,使用2字节(16bit)表示一个字符,分区码和位码两部分,区码在高字节,位码在低字节,在解析时需要注意。GB2312-80共编码7445个字符,其中汉字有6763个,全字符集编码范围A1A1-F7FE;其中中文字符编码范围B0A1-F7FE,可见该编码能与单字节的ASCII编码0x00~0x7F做出很好的区分。
官方资料请移步“GB2312 80信息交换用汉字编码字符集 基本集”http://www.moe.gov.cn/s78/A19/yxs_left/moe_810/s230/201206/t20120601_136847.html
但该文档仅2页,几乎没有参考价值:(
UTF8编码方式概述:
| Unicode码 (hex) | UTF8码 (hex) |
|---|---|
| 0000 0000 0000 007F | 0xxxxxxx |
| 0000 0080 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
单字节情况:UTF8编码中单字节最高位为0,UTF8兼容ASCII编码0x00~0x7F。
多字节情况:第一个字节从高位开始连续的1的个数(这里1的个数计算方法为从最高位开始计数,直至遇到当前字节的10结束)表示后续还有多少位是连续位;后续数据字节高两位固定 10,由于第一字节自身可以携带部分数据;所以也受数据字节高两位固定的规则限制。
举个栗子:
双字节的Unicode编码为UTF8格式,110xxxxx 10xxxxxx,阅读方向从左往右依次为第一字节、第二字节,字节计数基准点为0;第一字节最高位为1表示该字节后还有一个字节的数据;第6,5位为10表示本字节数据段开始,第4,0位为xxxxx表示可以携带5比特的数据;第二字节就非常简单了,高位10打头,直接取剩下的6比特数据即可。
因此2字节的UTF8编码仅有11比特的有效数据区,比起直接使用UTF16(USC2)编码还少了5比特信息范围,但是UTF8的优势在于可变长的设计,从解码规则也可以看出,对于西方国家的ASCII码,仅需一个字节就能表示,在网络传输方面能省点带宽;但对于东亚文字,就不那么友好了,两个字节能表示的数据范围,编码到UTF8格式需要3个字节才能表示,可以说有利有弊。
UTF8编码转换为GB2312编码字符集转换思路:
1.解码UTF8,还原成Unicode字符集
2.使用Unicode到GB2312字符集映射表找到对应的GB2312字符集编码
3.对于点阵字体,使用GB2312字符集编码在字库中查找字模进行显示;对于TTF字体,使用GB2312字符集编码找到字体的绘制path,进行绘制渲染。
值得庆幸的是GB2312字符集所表示的汉字/符号刚好在双字节的Unicode16(USC2)编码范围内,一对Unicode16转GB2312正好是4个字节,非常方便32位的系统进行对齐寻址,尤其是ARM这种不支持非对其访问的平台。
代码实现:
/*
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
*/
/**
* @brief utf8编码转unicode字符集(usc4),最大支持4字节utf8编码,(4字节以上在中日韩文中为生僻字)
* @param *utf8 utf8变长编码字节集1~4个字节
* @param *unicode utf8编码转unicode字符集结果,最大4个字节,返回的字节序与utf8编码序一致
* @return length 0:utf8解码异常,others:本次utf8编码长度
*/
uint8_t UTF8ToUnicode(uint8_t *utf8, uint32_t *unicode) {
const uint8_t lut_size = 3;
const uint8_t length_lut[] = {2, 3, 4};
const uint8_t range_lut[] = {0xE0, 0xF0, 0xF8};
const uint8_t mask_lut[] = {0x1F, 0x0F, 0x07};
uint8_t length = 0;
byte b = *(utf8 + 0);
uint32_t i = 0;
if(utf8 == NULL) {
*unicode = 0;
return PARSE_ERROR;
}
// utf8编码兼容ASCII编码,使用0xxxxxx 表示00~7F
if(b < 0x80) {
*unicode = b;
return 1;
}
// utf8不兼容ISO8859-1 ASCII拓展字符集
// 同时最大支持编码6个字节即1111110X
if(b < 0xC0 || b > 0xFD) {
*unicode = 0;
return PARSE_ERROR;
}
for(i = 0; i < lut_size; i++) {
if(b < range_lut[i]) {
*unicode = b & mask_lut[i];
length = length_lut[i];
break;
}
}
// 超过四字节的utf8编码不进行解析
if(length == 0) {
*unicode = 0;
return PARSE_ERROR;
}
// 取后续字节数据
for(i = 1; i < length; i++ ) {
b = *(utf8 + i);
// 多字节utf8编码后续字节范围10xxxxxx?~?10111111?
if( b < 0x80 || b > 0xBF ) {
break;
}
*unicode <<= 6;
// ?00111111?
*unicode |= (b & 0x3F);
}
// 长度校验
return (i < length) ? PARSE_ERROR : length;
}
/**
* @brief 4字节unicode(usc4)字符集转utf16编码
* @param unicode unicode字符值
* @param *utf16 utf16编码结果
* @return utf16长度,(2字节)单位
*/
uint8_t UnicodeToUTF16(uint32_t unicode, uint16_t *utf16) {
// Unicode范围 U+000~U+FFFF
// utf16编码方式:2 Byte存储,编码后等于Unicode值
if(unicode <= 0xFFFF) {
if(utf16 != NULL) {
*utf16 = (unicode & 0xFFFF);
}
return 1;
}else if( unicode <= 0xEFFFF ) {
if( utf16 != NULL ) {
// 高10位
*(utf16 + 0) = 0xD800 + (unicode >> 10) - 0x40;
// 低10位
*(utf16 + 1) = 0xDC00 + (unicode &0x03FF);
}
return 2;
}
return 0;
}
测试样例
int main() {
// 严 utf8 E4 B8 A5
printf("Hello world!\n");
uint32_t buffer;
uint8_t utf8[] = "\xE4\xB8\xA5";
uint16_t utf16[2] = {0};
uint8_t len = UTF8ToUnicode(utf8, &buffer);
printf("len:%d\n", len);
printf("buffer:%x\n", buffer);
len = UnicodeToUTF16(buffer, utf16);
printf("len:%d\n", len);
printf("utf16[0]:%x\n", utf16[0]);
printf("utf16[0]:%x\n", utf16[1]);
return 0;
}
输出:
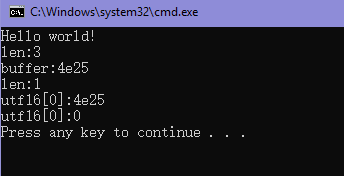
验证:
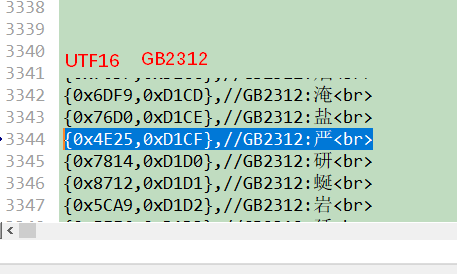
tips:
Unicode 16与GB2312-80的查找表可以使Unicode 16字符集编码按照升序排列,(即Unicode 16从小到大排,GB2312与之对应,但GB2312是乱的)这样程序中使用二分法查表,时间复杂度是O(log(n)),比线性查找最坏情况的O(n)要快上许多。
附件:
utf16.bin
utf16->gb2312查找表,其中utf16字符集升序排序,二进制格式
gb2312.bin
gb2312->utf16查找表,其中gb2312字符集升序排序,二进制格式
RawFile.txt
文本格式的UTF16到GB2312对照表,其中gb2312字符集升序排序
https://files.cnblogs.com/files/yanye0xff/fontmap.zip
标签:时间复杂度 htm 验证 null byte ret code ram 分区
原文地址:https://www.cnblogs.com/yanye0xff/p/13547150.html