标签:地址 灵活 http 官方 计算机 creat Kubernete 作用 架构
关于KubernetesKubernetes 源自于 Google 内部的服务编排系统 - Borg,诞生于2014年。它汲取了Google 十五年生产环境的经验积累,并融合了社区优秀的idea和实践经验。
Kubernetes这个单词起源于古希腊是舵手的意思,所以它的logo是一个渔网状的七边形,里面还有一个罗盘。Google选择这样一个名字也是有一定的深意:既然docker把自己比作一只鲸鱼托着集装箱在大海中遨游,Google就要用Kubernetes去掌握去掌握大航海时代的话语权,去捕获和指引着这条鲸鱼按照主人设定的路线去巡游。
得益于 Docker 的特性,服务的创建和销毁变得非常快速、简单。Kubernetes 正是以此为基础,实现了集群规模的管理、编排方案,使应用的发布、重启、扩缩容能够自动化。
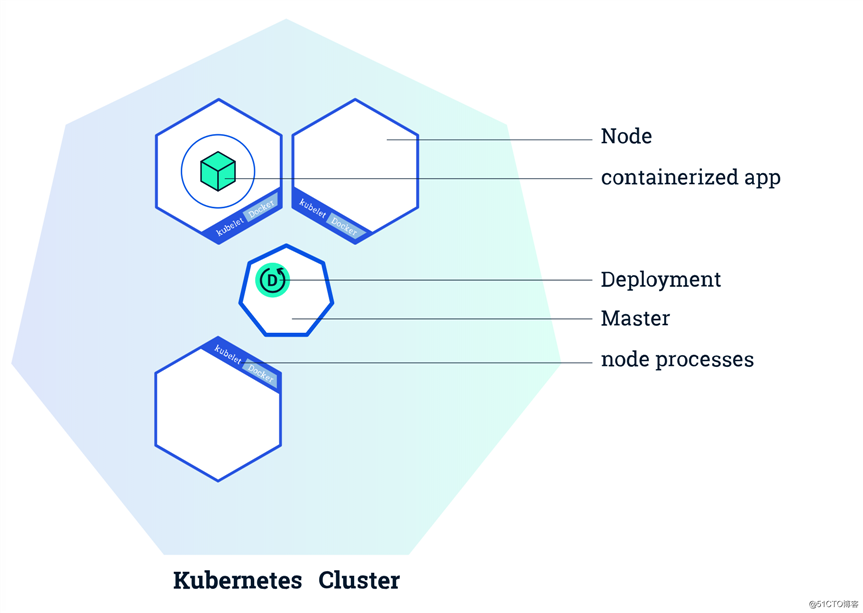
Kubernetes 可以管理大规模的集群,使集群中的每一个节点彼此连接,能够像控制一台单一的计算机一样控制整个集群。
在k8s集群中有两种角色,一种是 Master ,一种是 Node(也叫worker):
如下图: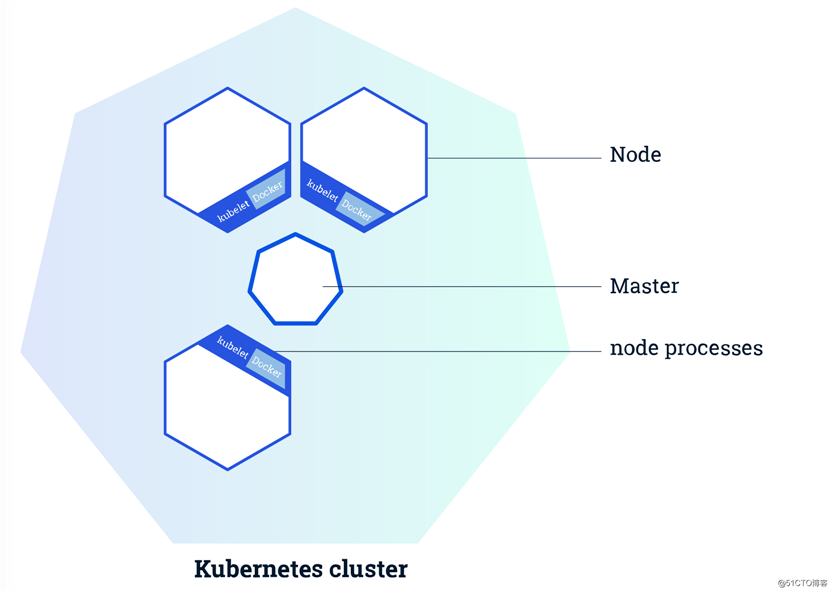
了解了集群中的两大角色后,我们再看看Kubenetes的架构示意图: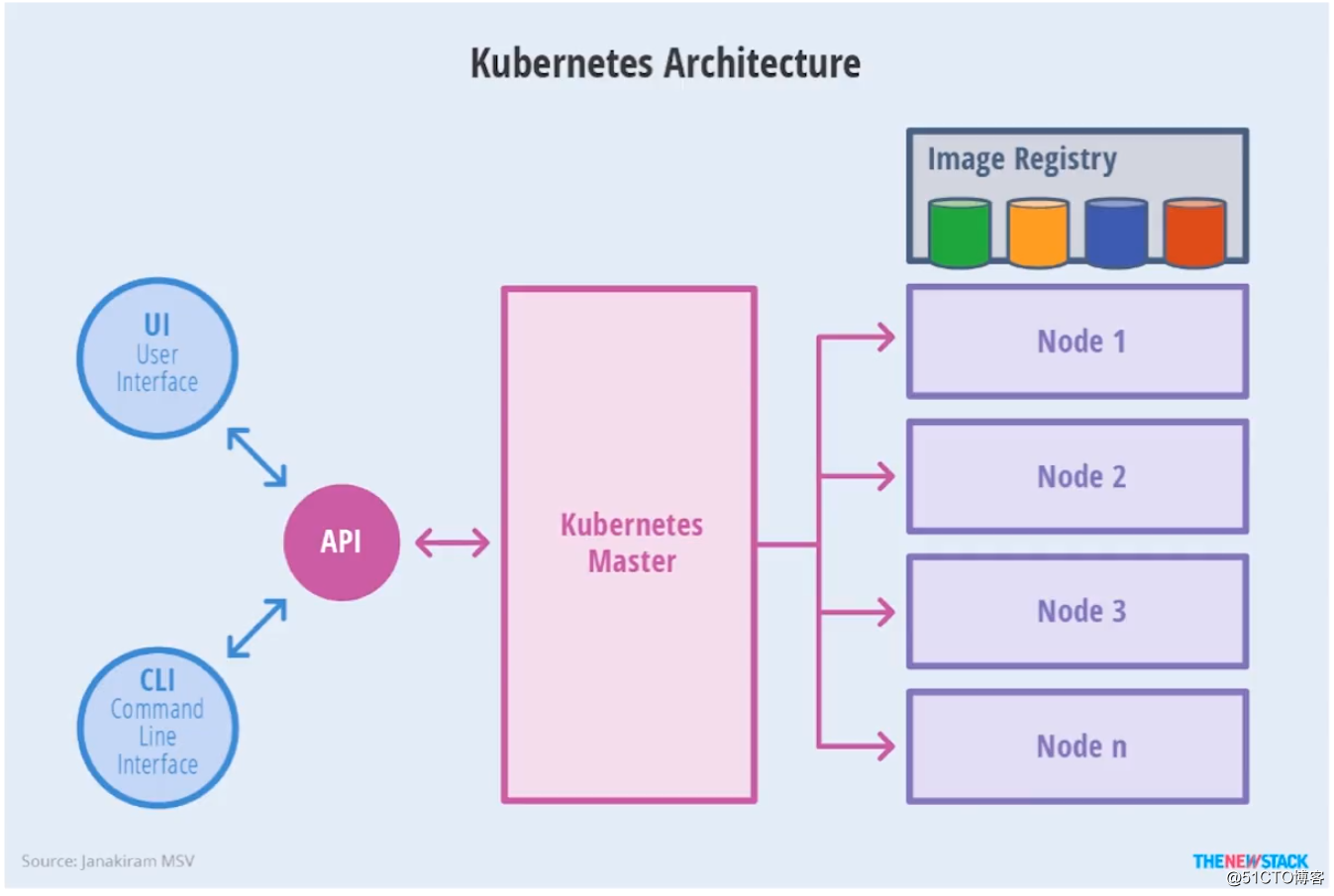
Kubenetes Master节点剖析图: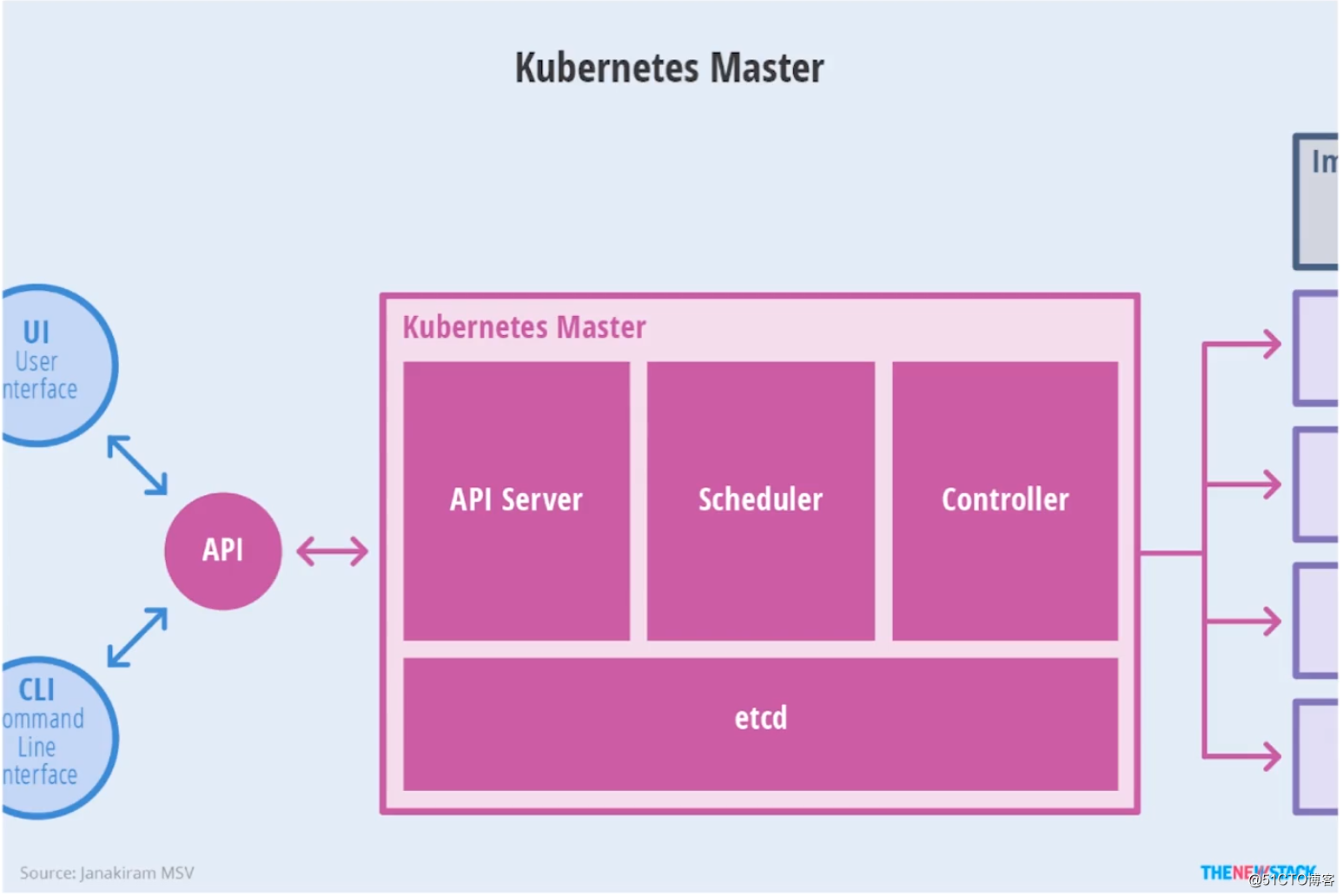
在上文也说了Master节点相当于Kubenetes集群中的大脑,在Master节点具备四个主要模块:
kubectl)与Kubenetes集群进行交互Kubenetes Node节点剖析图: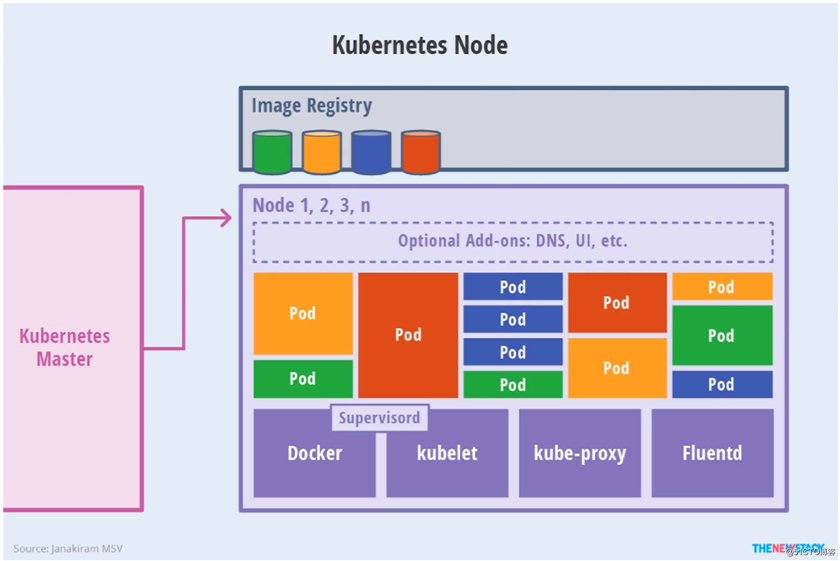
Kubernetes 的 Node 做的事情也并不是简单的 docker run 一个容器。出于像易用性、灵活性、稳定性等的考虑,Kubernetes 提出了一个叫做 Pod 的东西,作为 Kubernetes 的最小调度单位。所以我们的应用在每个 Node 上运行的其实是一个 Pod。Pod 也只能运行在 Node 上。如下图:
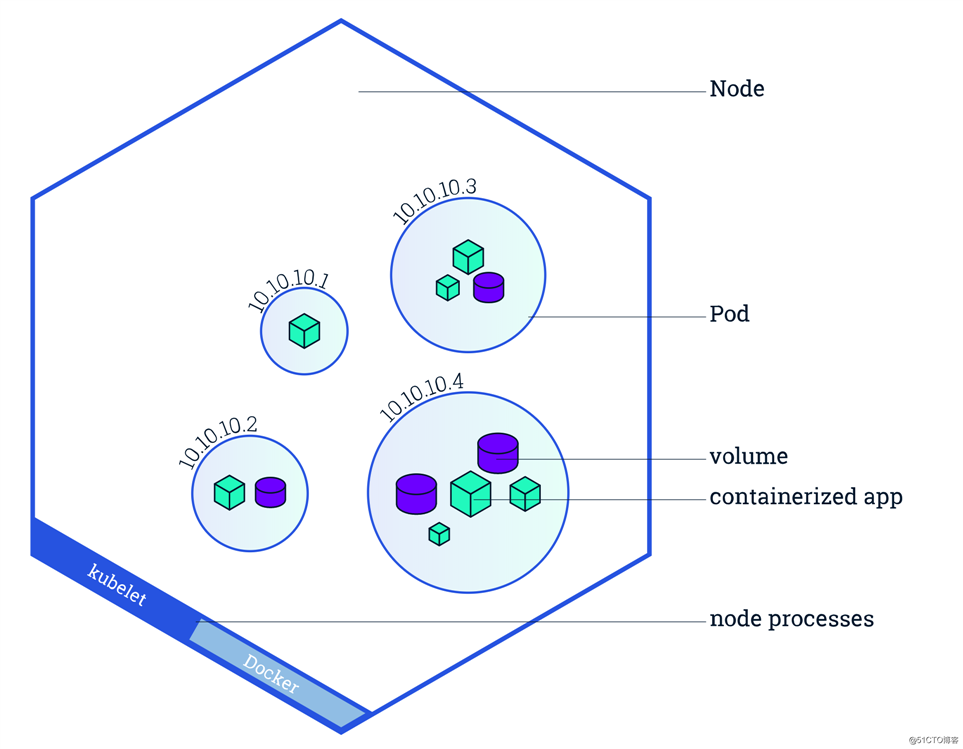
Pod中会包含一个或多个容器。容器本身就是一个小盒子了,Pod 相当于在容器上又包了一层小盒子。这个盒子里面的容器有什么特点呢?
127.0.0.1:8080就可以访问到B容器的服务,反之亦然。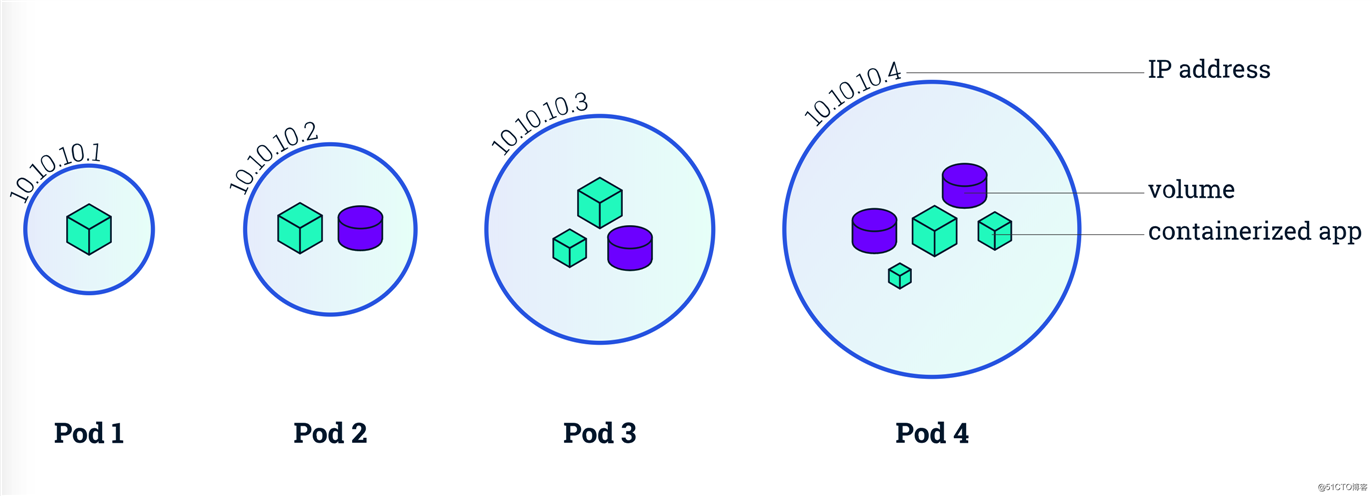
每个Pod里都会有一个特殊的Pause容器有时候也称为Infra容器,它与用户容器”捆绑“运行在同一个 Pod 中,最大的作用是维护 Pod 网络协议栈,将用户容器link到一起。这也是为什么同一个Pod里的容器之间仅需通过localhost就能互相通信的原因。除此以外,Pause容器还会负责Pod的健康检查,然后汇报给k8s。
Pause容器主要为每个用户容器提供以下功能:
关于Pause容器更多的内容可以参考:
Pod的上一层是ReplicaSet(副本集),简称RS。ReplicaSet负责维护应用的实例副本,所以ReplicaSet里的每一个Replica就是一个Pod而不是容器,因为Pod是最小调度单位。例如某个应用的ReplicaSet数量是2,当某一个节点上的Pod挂掉了,那么ReplicaSet就会检测到副本数量不满足2,此时k8s就会重新根据调度算法在其他节点创建并运行一个新的Pod,通俗来说就是再拉起一个Pod。
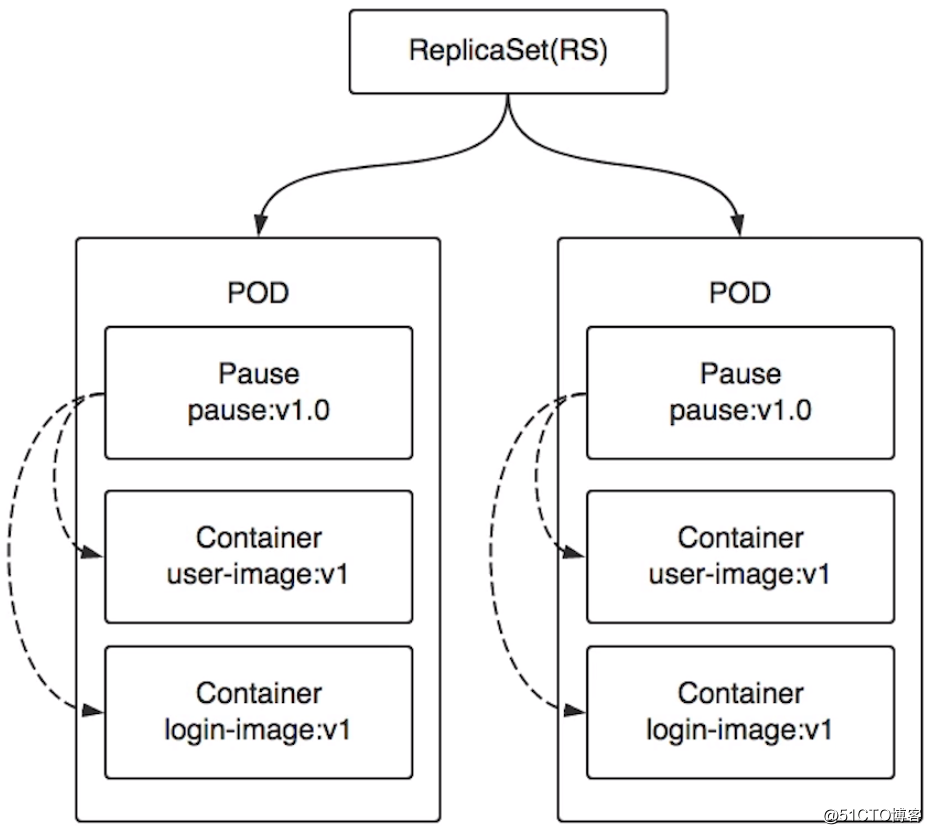
当我们拥有一个 Kubernetes 集群后,就可以在上面跑我们的应用了,前提是我们的应用必须支持在 Docker 中运行,也就是我们要事先准备好Docker镜像。
有了镜像之后,一般我们会通过Kubernetes的 Deployment 的配置文件去描述应用,比如应用叫什么名字、使用的镜像名字、要运行几个实例、需要多少的内存资源、cpu 资源等等。
有了配置文件就可以通过Kubernetes提供的命令行客户端 - kubectl 去管理这个应用了。kubectl 会跟 Kubernetes 的 master 通过RestAPI通信,最终完成应用的管理。
比如我们创建并配置好的 Deployment 配置文件叫 app.yaml,我们就可以通过"kubectl create -f app.yaml" 命令来创建这个应用,之后就由 Kubernetes 来保证我们的应用处于运行状态,当某个实例运行失败了或者运行着应用的 Node 突然宕机了,Kubernetes 会自动发现并在新的 Node 上调度一个新的实例,保证我们的应用始终达到我们预期的结果。
滚动升级是Kubernetes中最典型的服务升级方案,主要思路是一边增加新版本应用的实例数,一边减少旧版本应用的实例数,直到新版本的实例数达到预期,旧版本的实例数减少为0,滚动升级结束。在整个升级过程中,服务一直处于可用状态。并且可以在任意时刻回滚到旧版本。
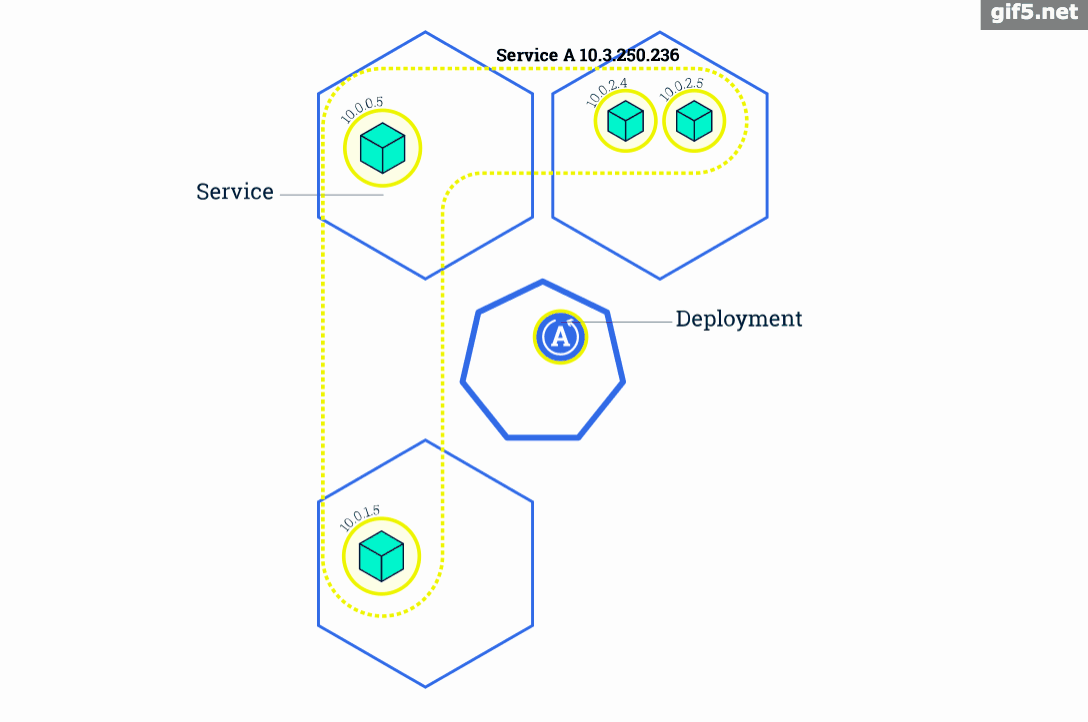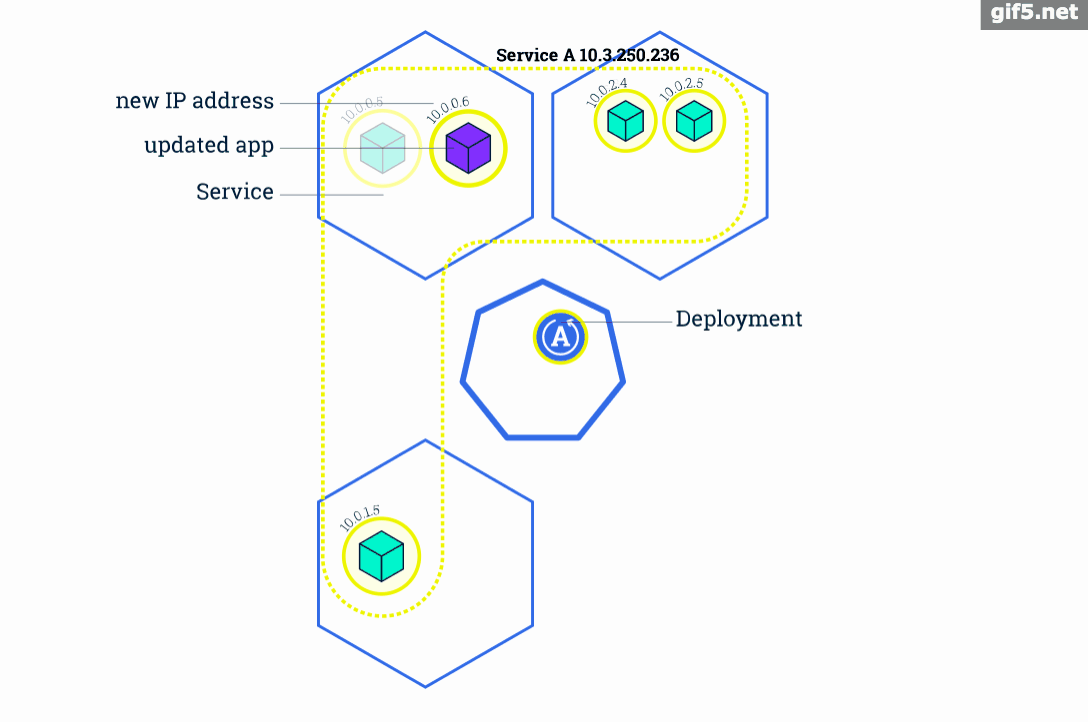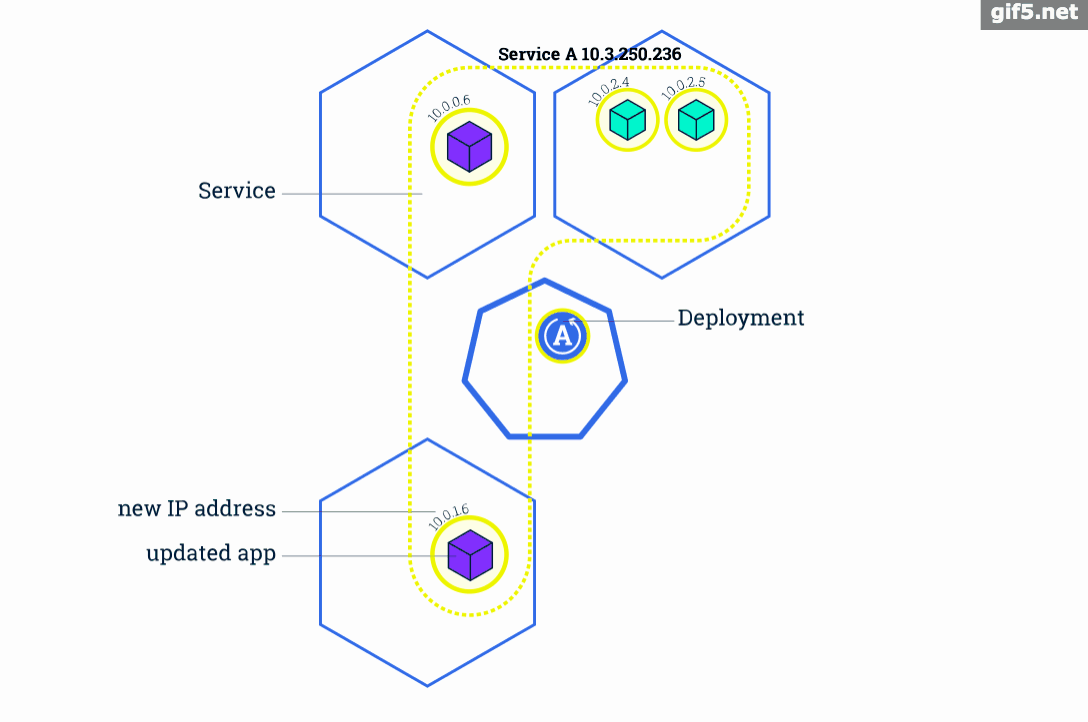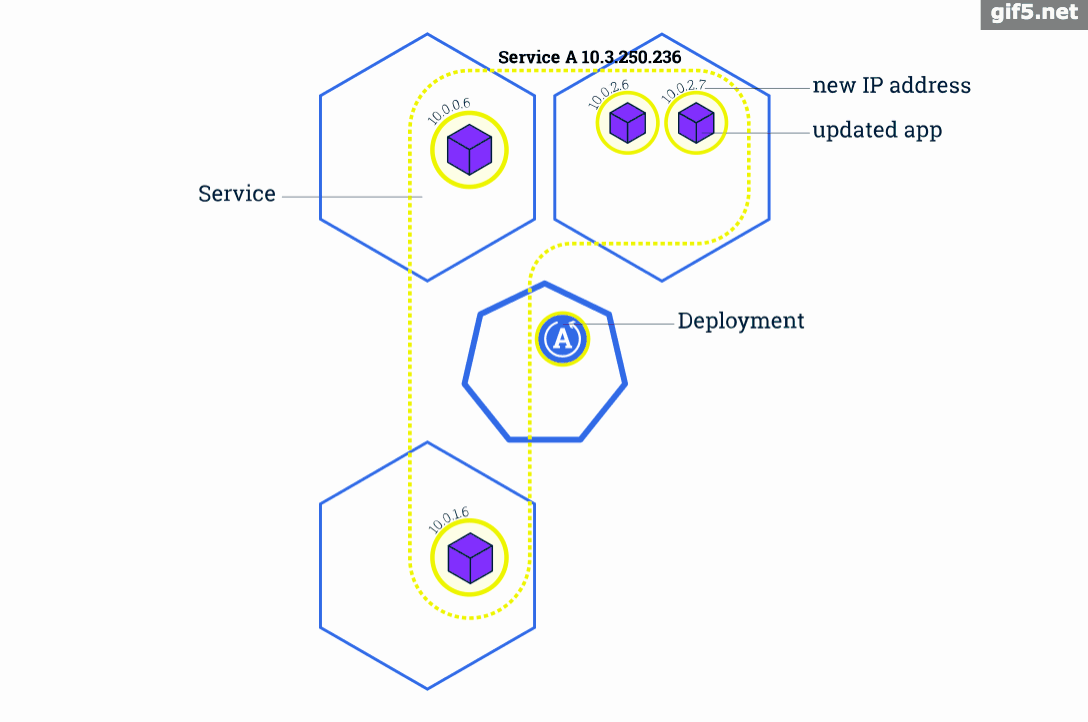
我们之所以不会直接将应用定义为Pod,而是定义为 Deployment 的一个重要原因就是因为只有将应用定义成 Deployment 时才能支持滚动升级。当 Deployment 中的容器需要升级更新时,Deployment 会先创建一个新的 ReplicaSet 及Pod,然后停止并删除旧的 ReplicaSet 中的一个Pod,接着再新建一个新版本Pod,然后再删除一个旧版本的Pod......以此实现滚动式的更新,所以在更新过程中应用可以实现不中断地服务。
假设我们上面介绍的 Deployment 创建了,Pod 也运行起来了。如何才能访问到我们的应用呢?
最直接想到的方法就是直接通过 Pod的 ip + 端口号去访问,但如果实例数很多呢?好,拿到所有的 Pod - ip 列表,配置到负载均衡器中,轮询访问。但上面我们说过,Pod 可能会死掉,甚至 Pod 所在的 Node 也可能宕机,Kubernetes 会自动帮我们重新创建新的Pod。再者每次更新服务的时候也会重建 Pod。而每个 Pod 都有自己的 ip。所以 Pod 的ip 是不稳定的,会经常变化的,不可能每次ip变化都去修改一下负载均衡中的ip列表。
面对这种变化我们就要借助另一个概念:Service。它就是来专门解决这个问题的。不管Deployment的Pod有多少个,不管它是更新、销毁还是重建,Service总是能发现并维护好它的ip列表。Service对外也提供了多种入口:
NodeIP:NodePort。spec.externlName 设定)。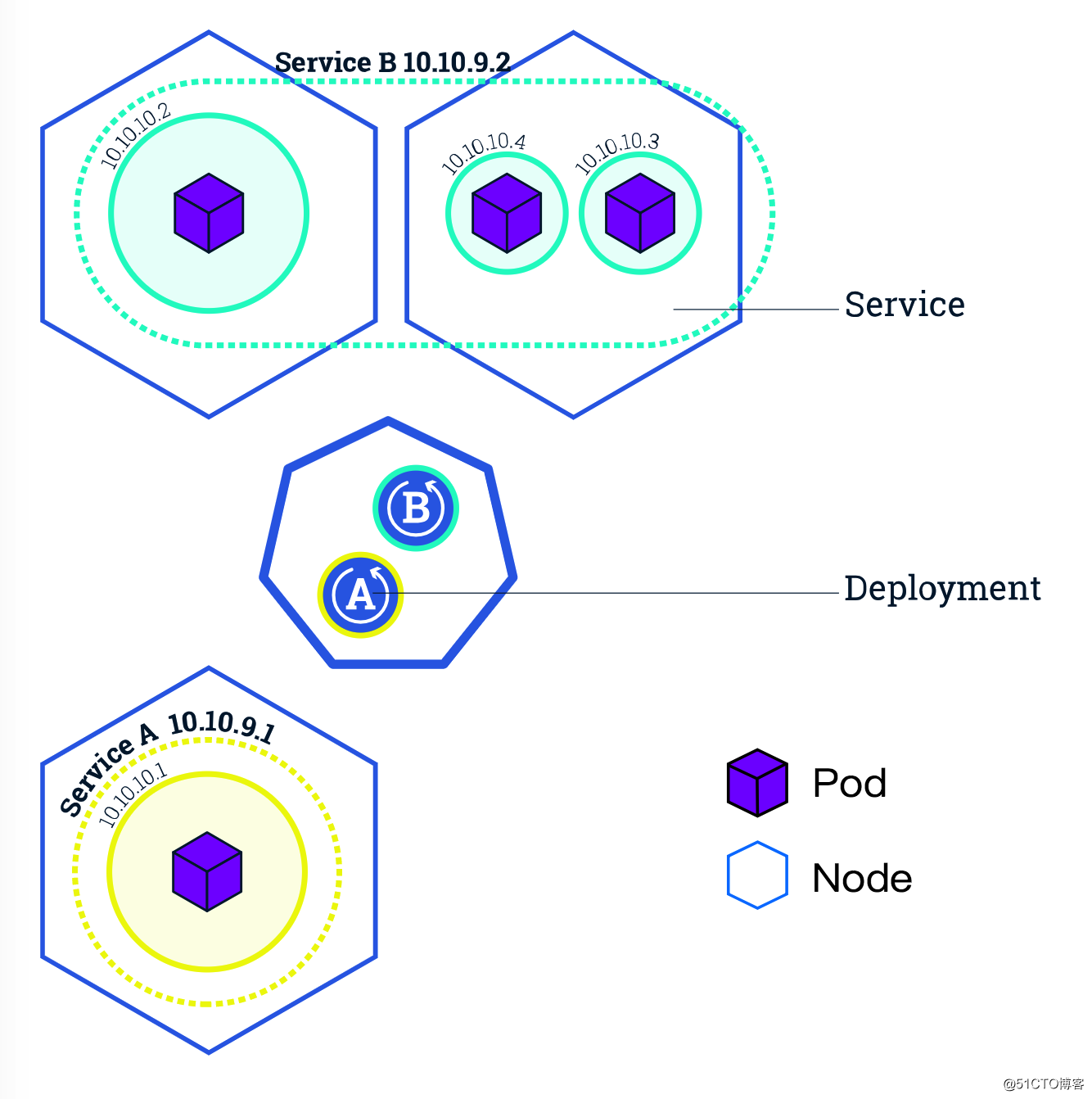
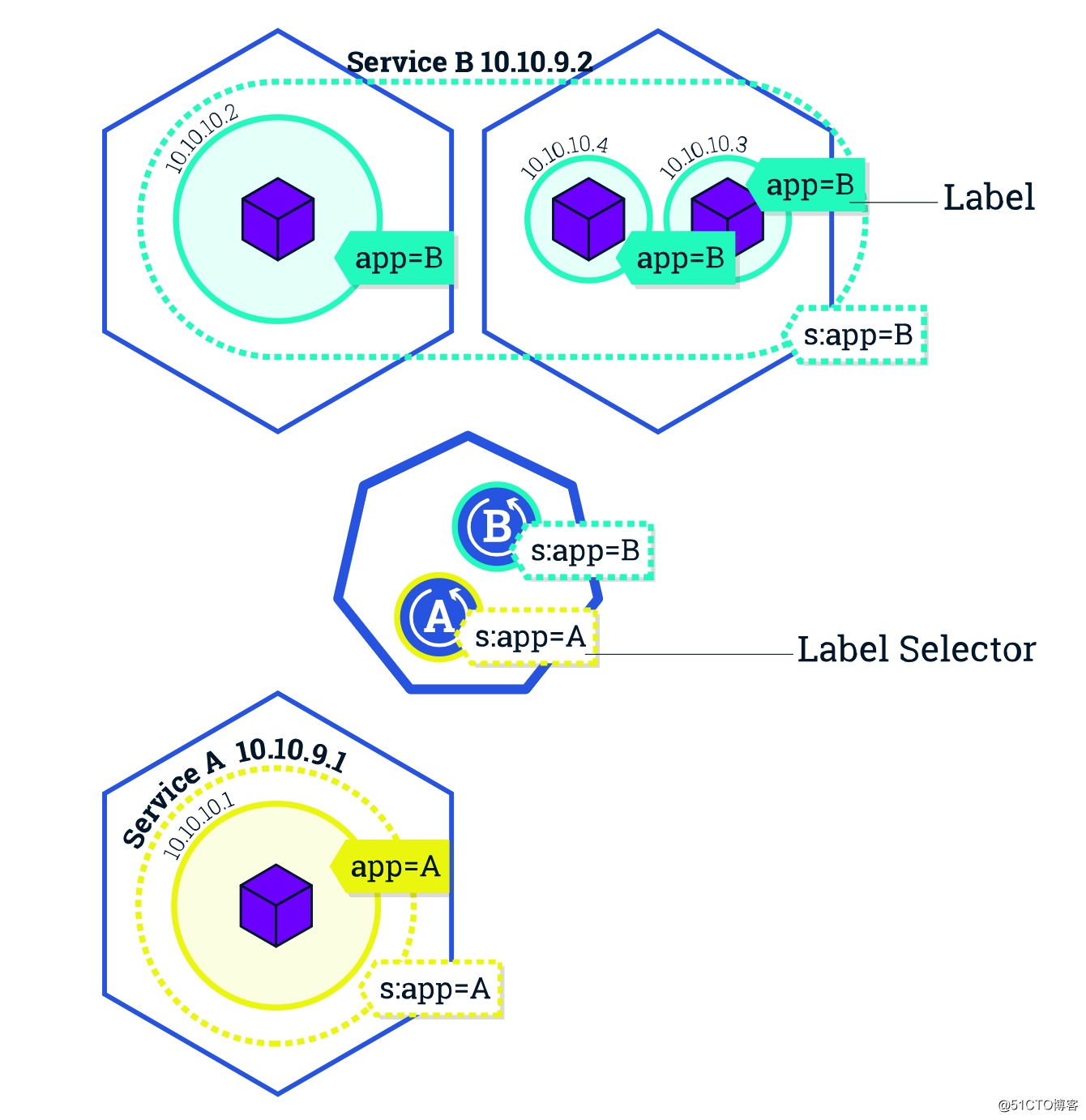
好,看似服务访问的问题解决了。但大家有没有想过,Service是如何知道它负责哪些 Pod 呢?是如何跟踪这些 Pod 变化的?
最容易想到的方法是使用 Deployment 的名字。一个 Service 对应一个 Deployment 。当然这样确实可以实现。但Kubernetes 使用了一个更加灵活、通用的设计 - Label 标签,通过给 Pod 打标签,Service 可以只负责一个 Deployment 的 Pod 也可以负责多个 Deployment 的 Pod 了。Deployment 和 Service 就可以通过 Label 解耦了。
关于Kubernetes的认证与授权机制内容比较多也比较复杂,所以这里引用一些文章作为参考:
也可以直接翻阅官方文档:
标签:地址 灵活 http 官方 计算机 creat Kubernete 作用 架构
原文地址:https://blog.51cto.com/zero01/2525514