标签:alt 链表 初始 并查集 rgs hash函数 压缩 常量 union
这一篇我们看看经典又神奇的并查集,顾名思义就是并起来查,可用于处理一些不相交集合的秒杀。有时候我们会遇到这样的场景,比如:M={1,4,6,8},N={2,4,5,7},我的需求就是判断{1,2}是否属于同一个集合,当然实现方法有很多,一般情况下,普通青年会做出O(MN)的复杂度,那么有没有更轻量级的复杂度呢?嘿嘿,并查集就是用来解决这个问题的。
从名字可以看出,并查集其实只有两种操作,并(Union)和查(Find),并查集是一种算法,所以我们要给它选择一个好的数据结构,通常我们用树来作为它的底层实现。
1. 节点定义
/// <summary>
/// 树节点
/// </summary>
public class Node
{
/// <summary>
/// 父节点
/// </summary>
public char parent;
/// <summary>
/// 节点的秩
/// </summary>
public int rank;
}2. Union操作
<1> 原始方案
首先对集合的所有元素进行打散,这样的话每个元素都是一个独根的树,然后开始Union其中某两个元素,让他们成为一个集合,最坏情况下我们进行M次的Union时会存在这样的一个链表的场景,如下图:
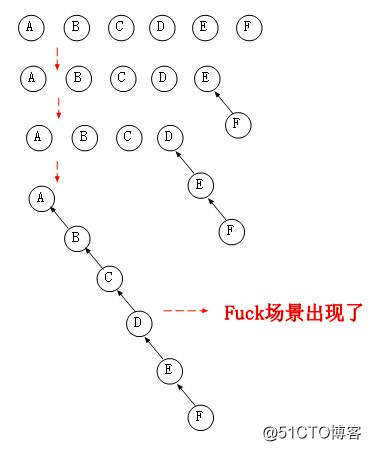
从图中可以看到,Union时出现了最坏的情况,而且这种情况还是比较容易出现的,导致在Find的时候也就没啥意义了,复杂度为O(N)。
<2> 按秩合并
其实你可以发现出现这种情况的原因在于我们Union时都是将合并后的大树作为小树的孩子节点存在,那么我们在Union时能不能判断一下,将小树作为大树的孩子节点存在,最终也就降低了新树的深度,比如图中的Union(D,{E,F})的时候可以做出如下修改。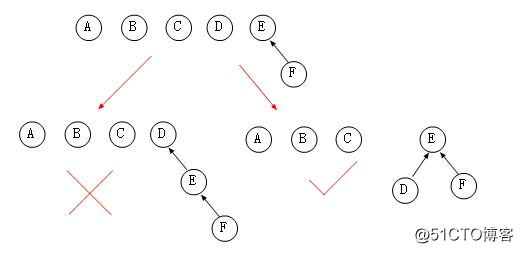
可以看出,图中右侧正确的做法有效的降低了树的深度,在N个元素的集合中,构建树的深度不会超过LogN层。M次操作的复杂度为O(MlogN),从代码上来说,我们用Rank来统计树的秩,可以理解为树的高度,独根树时Rank=0,当两棵树的Rank相同时,可以随意挑选合并,在新根中的Rank++就可以了。
#region 合并两个不相交集合
/// <summary>
/// 合并两个不相交集合
/// </summary>
/// <param name="root1"></param>
/// <param name="root2"></param>
/// <returns></returns>
public void Union(char root1, char root2)
{
char x1 = Find(root1);
char y1 = Find(root2);
//如果根节点相同则说明是同一个集合
if (x1 == y1)
return;
//说明左集合的深度 < 右集合
if (dic[x1].rank < dic[y1].rank)
{
//将左集合指向右集合
dic[x1].parent = y1;
}
else
{
//如果 秩 相等,则将 y1 并入到 x1 中,并将x1++
if (dic[x1].rank == dic[y1].rank)
dic[x1].rank++;
dic[y1].parent = x1;
}
}
#endregion
3.Find操作
我们学算法,都希望能把一个问题优化到地球人都不能优化的地步,针对logN的级别,我们还能优化吗?当然可以。
<1>路径压缩
在Union和Find这两种操作中,显然在Union操作上已经做到了极致,那我们可不可以在Find上面捣鼓一下,运用伸展树的玩法,它的伸展思想就是压缩路径。

从图中可以看出,当我 Find(F) 的时候,找到 “F” 后就要开始准备一直回溯,在回溯的过程中,把该节点的父亲指向根节点。最终我们会形成一个压缩后的树,当我们再次 Find(F) 的时候,只要 O(1) 的时间就可以获取,这里有个注意的地方就是Rank,当在路径压缩时,最后树的高度可能会降低,可能你会意识到原先的Rank就需要修改了,所以我要说的就是:当路径压缩时,Rank保存的就是树高度的上界,而不仅仅是明确的树高度,可以理解成"伸缩椅"伸时候的长度。
#region 查找x所属的集合
/// <summary>
/// 查找x所属的集合
/// </summary>
/// <param name="x"></param>
/// <returns></returns>
public char Find(char x)
{
//如果相等,则说明已经到根节点了,返回根节点元素
if (dic[x].parent == x)
return x;
//路径压缩(回溯的时候赋值,最终的值就是上面返回的"x",也就是一条路径上全部被修改了)
return dic[x].parent = Find(dic[x].parent);
}
#endregion或许你还注意到了在路径压缩后,我们将LogN的复杂度降低到Alpha(N),Alpha(N)可以理解成一个比hash函数还有小的常量,嘿嘿,这就是算法的魅力。
最后上一下总的运行代码:
class Program
{
static void Main(string[] args)
{
//定义 6 个节点
char[] c = new char[] { ‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘, ‘F‘ };
DisjointSet set = new DisjointSet();
set.Init(c);
set.Union(‘E‘, ‘F‘);
set.Union(‘C‘, ‘D‘);
set.Union(‘C‘, ‘E‘);
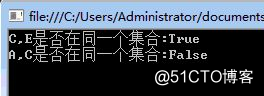
var b = set.IsSameSet(‘C‘, ‘E‘);
Console.WriteLine("C,E是否在同一个集合:{0}", b);
b = set.IsSameSet(‘A‘, ‘C‘);
Console.WriteLine("A,C是否在同一个集合:{0}", b);
Console.Read();
}
}
/// <summary>
/// 并查集
/// </summary>
public class DisjointSet
{
#region 树节点
/// <summary>
/// 树节点
/// </summary>
public class Node
{
/// <summary>
/// 父节点
/// </summary>
public char parent;
/// <summary>
/// 节点的秩
/// </summary>
public int rank;
}
#endregion
Dictionary<char, Node> dic = new Dictionary<char, Node>();
#region 做单一集合的初始化操作
/// <summary>
/// 做单一集合的初始化操作
/// </summary>
public void Init(char[] c)
{
//默认的不想交集合的父节点指向自己
for (int i = 0; i < c.Length; i++)
{
dic.Add(c[i], new Node()
{
parent = c[i],
rank = 0
});
}
}
#endregion
#region 判断两元素是否属于同一个集合
/// <summary>
/// 判断两元素是否属于同一个集合
/// </summary>
/// <param name="root1"></param>
/// <param name="root2"></param>
/// <returns></returns>
public bool IsSameSet(char root1, char root2)
{
return Find(root1) == Find(root2);
}
#endregion
#region 查找x所属的集合
/// <summary>
/// 查找x所属的集合
/// </summary>
/// <param name="x"></param>
/// <returns></returns>
public char Find(char x)
{
//如果相等,则说明已经到根节点了,返回根节点元素
if (dic[x].parent == x)
return x;
//路径压缩(回溯的时候赋值,最终的值就是上面返回的"x",也就是一条路径上全部被修改了)
return dic[x].parent = Find(dic[x].parent);
}
#endregion
#region 合并两个不相交集合
/// <summary>
/// 合并两个不相交集合
/// </summary>
/// <param name="root1"></param>
/// <param name="root2"></param>
/// <returns></returns>
public void Union(char root1, char root2)
{
char x1 = Find(root1);
char y1 = Find(root2);
//如果根节点相同则说明是同一个集合
if (x1 == y1)
return;
//说明左集合的深度 < 右集合
if (dic[x1].rank < dic[y1].rank)
{
//将左集合指向右集合
dic[x1].parent = y1;
}
else
{
//如果 秩 相等,则将 y1 并入到 x1 中,并将x1++
if (dic[x1].rank == dic[y1].rank)
dic[x1].rank++;
dic[y1].parent = x1;
}
}
#endregion
}
标签:alt 链表 初始 并查集 rgs hash函数 压缩 常量 union
原文地址:https://blog.51cto.com/huangxincheng/2525497