ps -ef | grep java (先查java进程ID)
kill -9 PID(生产环境谨慎使用)
kill、killall、pkill命令的区别
kill:通过pid来杀死进程
killall (killall [参数] [进程名]):Linux系统中的killall命令用于杀死指定名字的进程(kill processes by name)。我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall把这两个过程合二为一,是一个很好用的命令。
pkill:pkill 和killall 应用方法差不多,也是直接杀死运行中的程式;如果你想杀掉单个进程,请用kill 来杀掉。例子: pkill -9 firefox
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
head:
跟tail是相反的,tail是看后多少行日志;例子如下:
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;
cat:
tac是倒序查看,是cat单词反写;例子如下:
cat -n test.log |grep "debug" 查询关键字的日志
2. 应用场景一:按行号查看---过滤出关键字附近的日志
1)cat -n test.log |grep "debug" 得到关键日志的行号
2)通常查找出错误日志 cat error.log | grep ‘nick‘ , 这时候我们还有个需求就是输出当前这个日志的前后几行:
cat error.log | grep -B 5 ‘nick‘ 显示nick及前5行
cat error.log | grep -A 5 ‘nick‘ 显示nick及后5行
cat error.log | grep -C 5 ‘nick‘ 显示file文件里匹配nick字串那行以及上下5行
cat error.log | grep -n -B10 -A10 5 ‘nick‘ 显示file文件里匹配nick字串前后10行
3. 应用场景二:选取日志中特定范围进行分析
1)cat -n test.log |tail -n +1000|head -n 20 从第1000行开始,显示20行
tail -n +1000表示查询1000行之后的日志
head -n 20 则表示在前面的查询结果里再查前20条记录
2)cat catalina.out | head -n 1400| tail -n +1350 显示1350行到1400行 (实现原理都差不多,就是通过语法糖)
(1)按日期截取 :一般在日志系统中都会记录打印日志的时间,通常我们非常需要查找指定时间端的日志:
sed -n ‘/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p‘ test.log
特别说明:该命令中的两个日期值必须是日志文件中包含的值,否则该命令无效.; 先 grep ‘2014-12-17 16:17:20‘ test.log 来确定日志中是否有该 时间点
(2)按行数截取
sed -n ‘10000,20000p’ test.log
sed -i ‘/关键词/d‘ catalina.out 删除包含关键词的行
4.应用场景三:日志内容特别多,打印在屏幕上不方便查看(1)使用more和less命令,
如: cat -n test.log |grep "debug" |more 这样就分页打印了,通过点击空格键翻页
(2)使用 >xxx.txt 将其保存到文件中,到时可以拉下这个文件分析
如:cat -n test.log |grep "debug" >debug.txt
5:使用管道进行and or条件处理
and 使用管道实现 例如: grep -n ‘日志排查‘ test.log | grep ‘日志‘
or 用-E 例如:grep -n -E ‘日志排查|hello‘ test.log 满足两个关键字的都可以找出来
6:如何看查占用cpu最多的进程?
方法一
核心指令:ps
实际命令:
ps H -eo pid,pcpu | sort -nk2 | tail
执行效果如下:
[work@test01 ~]$ ps H -eo pid,pcpu | sort -nk2 | tail
31396 0.6
31396 0.6
31396 0.6
31396 0.6
31396 0.6
31396 0.6
31396 0.6
31396 0.6
30904 1.0
30914 1.0
结果:
瞧见了吧,最耗cpu的pid=30914。
画外音:实际上是31396。
方法二
核心指令:top
实际命令:
top
Shift + t
top 命令类似于 Windows 的任务管理器,能够显示 Linux 系统中运行的进程的动态实时视图。
默认情况下,top 输出结果是按 CPU 占用进行排序,每 5s 更新一次结果。我们可以使用 top-b|head-50 显示排前 50 的占用 CPU 最高的进程( Linux 中如何找出 CPU 占用高的进程
)。
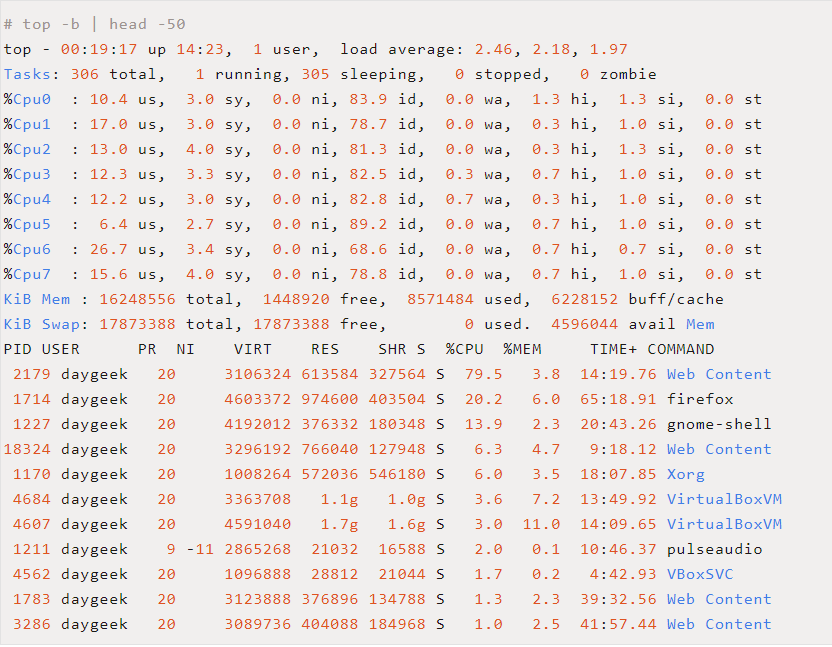
上面的命令解释如下:
-
-b:批次档模式
-
head -50:显示输出结果的前 50 个
-
PID:进程的 ID
-
USER:进程的归属者
-
PR:进程的等级
-
NI:进程的 NICE 值
-
VIRT:进程使用的虚拟内存
-
RES:进程使用的物理内存
-
SHR:进程使用的共享内存
-
S:这个值表示进程的状态: S = 睡眠,R = 运行,Z = 僵尸进程
-
%CPU:进程占用的 CPU 比例
-
%MEM:进程使用的 RAM 比例
-
TIME+:进程运行了多长时间
-
COMMAND:进程名字
如果想看进程的完整信息,可以加 -c 参数,如 top-b-c|head-50
使用 ps
ps 就是进程状态的缩写,可以显示当前运行进程的详细信息,如用户名、用户 ID、CPU 使用率、内存使用、进程启动日期时间、命令名等等。
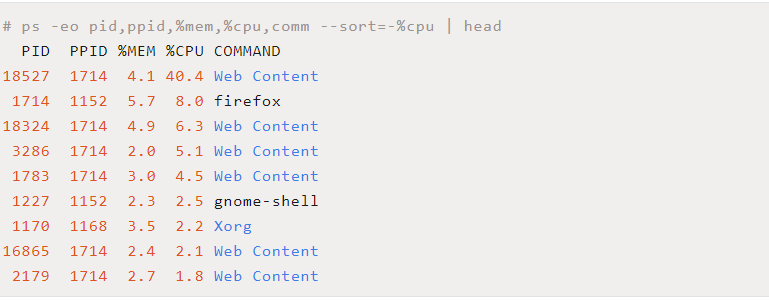
使用 ps-eo pid,ppid,%mem,%cpu,cmd--sort=-%cpu|head 可以显示占用 CPU 较高的进程信息(注意 --sort=-%cpu)。如下:

# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%cpu | head PID PPID %MEM %CPU CMD 18527 1714 4.2 40.3 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab 1714 1152 5.6 8.0 /usr/lib/firefox/firefox --new-window 18324 1714 4.9 6.3 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab 3286 1714 2.0 5.1 /usr/lib/firefox/firefox -contentproc -childID 14 -isForBrowser -prefsLen 8078 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab 1783 1714 3.0 4.5 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab 1227 1152 2.3 2.5 /usr/bin/gnome-shell 1170 1168 3.5 2.2 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3 16865 1714 2.5 2.1 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab 2179 1714 2.7 1.8 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
上命令的解释如下:
-
-e:选择所有进程
-
-o:自定义输出格式
-
–sort=-%cpu:基于 CPU 使用率对输出结果排序
-
head:显示结果的前 10 行
-
PID:进程的 ID
-
PPID:父进程的 ID
-
%MEM:进程使用的 RAM 比例
-
%CPU:进程占用的 CPU 比例
-
Command:进程名字
如果想看命令名字而不是命令的绝对路径,可以:
7:找到了最耗CPU的进程ID,对应的服务名是什么呢?
方法一
核心指令:ps
实际命令:
ps aux | fgrep pid
执行效果如下:
[work@test01 ~]$ ps aux | fgrep 30914
work 30914 1.0 0.8 309568 71668 ? Sl Feb02 124:44 ./router2 –conf=rs.conf
结果:
瞧见了吧,进程是./router2
画外音: grep 和fgrep的区别?
两者都是搜索工具,但功能上有区别。
1,首先,grep支持的是标准正则表达式。
2,fgrep,不支持正则表达式,只用于匹配固定字符串。
所以后者要比前者速度快,当然同时后者的搜索功能要弱于前者。
方法二
直接查proc即可。
实际命令:
ll /proc/pid
执行效果如下:
[work@test01 ~]$ ll /proc/30914
lrwxrwxrwx 1 work work 0 Feb 10 13:27 cwd -> /home/work/im-env/router2
lrwxrwxrwx 1 work work 0 Feb 10 13:27 exe -> /home/work/im-env/router2/router2
画外音:这个好,全路径都出来了。
8:如何查看某个端口的连接情况?
方法一
核心指令:netstat
实际命令:
netstat -lap | fgrep port
执行效果如下:
[work@test01 ~]$ netstat -lap | fgrep 22022
tcp 0 0 10.58.xxx.29:22022 *:* LISTEN 31396/imui
tcp 0 0 10.58.xxx.29:22022 10.58.xxx.29:46642 ESTABLISHED 31396/imui
tcp 0 0 10.58.xxx.29:22022 10.58.xxx.29:46640 ESTABLISHED 31396/imui
方法二
核心指令:lsof
实际命令:
lsof -i :port
执行效果如下:
[work@test01 ~]$ /usr/sbin/lsof -i :22022
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
router 30904 work 50u IPv4 69065770 TCP 10.58.xxx.29:46638->10.58.xxx.29:22022 (ESTABLISHED)
router 30904 work 51u IPv4 69065772 TCP 10.58.xxx.29:46639->10.58.xxx.29:22022 (ESTABLISHED)
router 30904 work 52u IPv4 69065774 TCP 10.58.xxx.29:46640->10.58.xxx.29:22022 (ESTABLISHED)
9:归档压缩文件导出指定内容到文件
命令: zcat 压缩文件 |grep ‘关键词‘ > 111.txt