标签:灰产 不难 时长 value proc headers 需要 ide 图片下载
Python3 网络爬虫(四):视频下载,那些事儿!来自专辑
网络爬虫教程
点击上方“Jack Cui”,选择“加为星标”
第一时间关注技术干货!
1
你知道的视频下载“姿势”,有哪些吗?
本文绝对有你意想不到的玩法!
2
陈年往事
视频下载,跟图片下载其实并无差别,甚至更简单。
玩过视频下载的,应该对「you-get」并不陌生。
「you-get」支持各大视频网站的视频下载,国内外加起来近 80 家。像国内的爱奇艺、腾讯视频、抖音、快手、B站、A站,国外的 Youtube、Twitter、TED、Instagram等等。
你只需要一行命令,就可以轻松下载想要的视频。
you-get https://www.bilibili.com/video/BV1NZ4y1j7nw比如,下载“黑人抬棺原版视频”。
简单好用!
URL:https://github.com/soimort/you-get
有了「you-get」就“无敌”了吗?
并非如此,「you-get」对于短视频下载较好。对于爱奇艺、腾讯视频里面的长视频内容,支持就有些局限。比如 VIP 付费内容,只能下载个 6 分钟时长的片头。
付费的 VIP 内容,也可以下载吗?
当然可以。
早在 2 年前,我就搭建过视频解析网站。
甭管是爱奇艺、腾讯、还是优酷,也甭管是免费视频还是付费视频,只要给个视频网址链接,分分钟解析播放。
用自己搭建的这个解析网站,白嫖了半年的视频。后来,用我这个网站看视频的人越来越多,索性就给它停了。
说实话,自己白嫖就算了,还带着大家一起白嫖,就有些过分了。
后来付费意识逐渐增强,不想再做白嫖党,也就办了爱奇艺的年度会员。
这种视频解析网站现在仍然有很多,但大多数都早已不能用了。
在网络上,有个叫「视频解析接口」的东西。
这些大大小小的视频解析网站,其实就是调用的这些第三方「视频解析接口」实现的。
背后的原理也并不复杂,就是拿着一些 VIP 会员账号,在后台解析视频,然后分享给别人看的。
随着版权意识、版权管理的加强,以及技术的更新迭代,这类「视频解析接口」也就逐渐失效了。
在网络上,还有个叫「资源采集网」的东西。
「视频解析接口」大量失效,那帮搞「灰产」的人另辟蹊径,既然视频无法解析,那就搜索资源吧。
现在,与其叫它们「视频解析接口」,不如叫它们「视频搜索接口」。
这些「视频搜索接口」拿着视频地址,去「资源采集网」匹配资源。
「资源采集网」其实就是一个大型网络爬虫,它会采集网络上的视频资源,并将它们整合到一起。
这里的说头,太多了。扯远了,回归正题。
3
背景讲完了,那就进入今天的主题,从「资源采集网」下载我们想要的视频。
以「越狱第一季」为例,越狱算是带我入坑的美剧之一,Miller 太帅了。
本文要爬的网站名叫「ok 资源网」,长这样: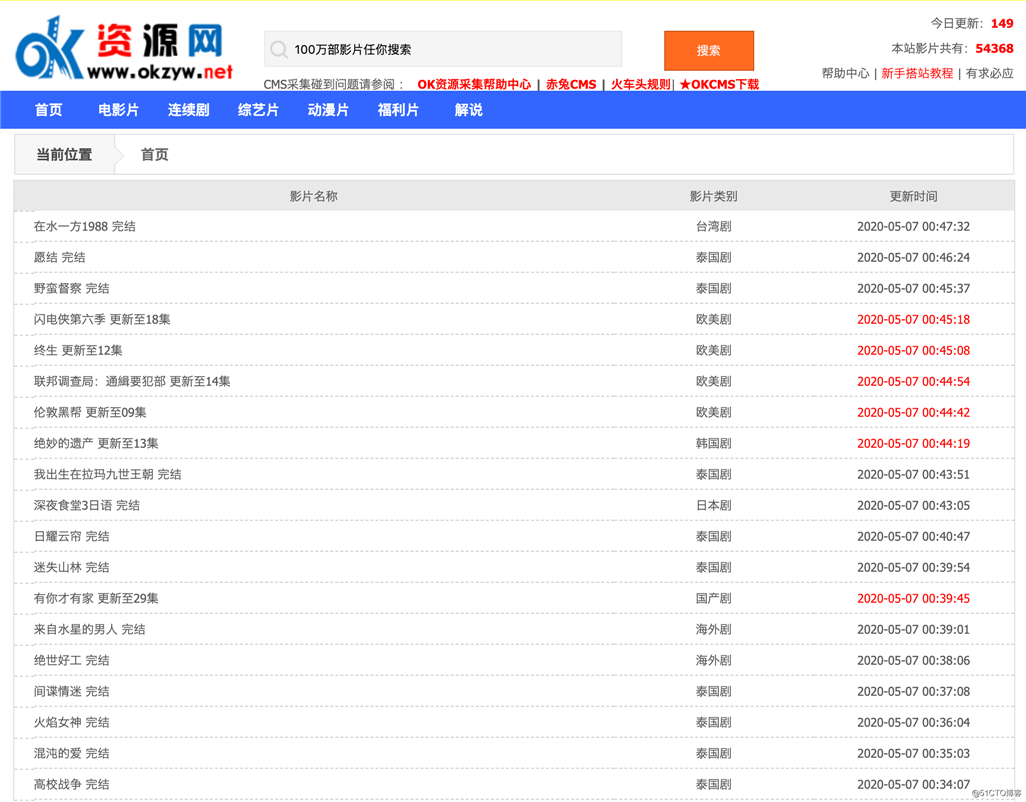
思路也不复杂,搜索、解析、下载。
想要下载视频,首先得找到资源,采用站内搜索很简单。
抓搜索的请求包也特别简单,教一个小技巧:
第一步输入要搜索的内容,第二步打开并清理 Network,第三步点击搜索按钮。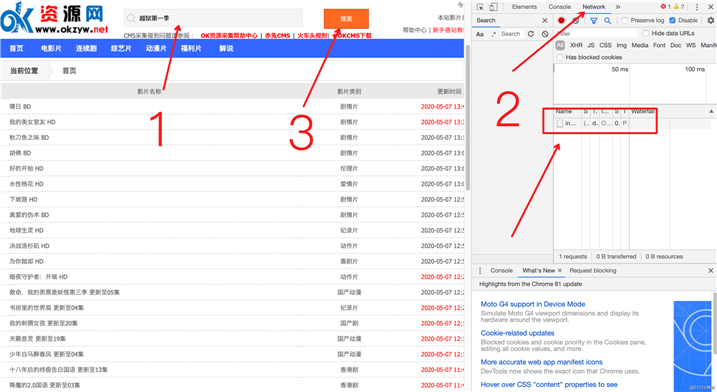
Network 里第一个弹出的就是搜索的请求包。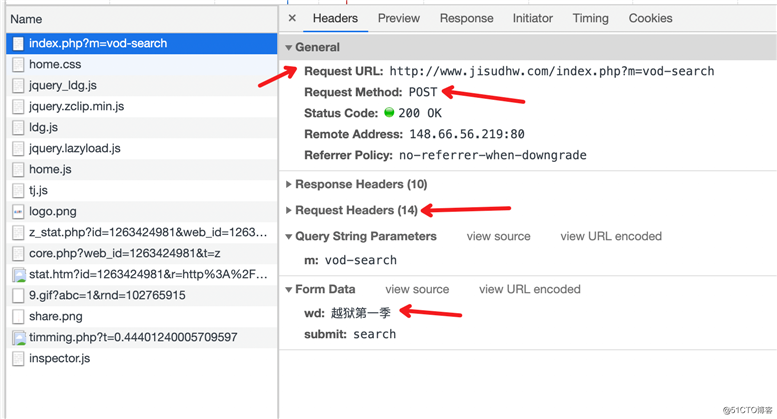
可以看到,这是一个 POST 请求。
之前的实战内容,无论是下载小说,还是下载图片,都是 GET 请求。
GET 请求,就是字面意思,从服务器获取数据。POST 请求,也是字面意思,给服务器发送数据。
因为我们是搜索嘛,得告诉服务器,咱搜索啥,给服务器传递数据,就是通过 POST。
能 POST 的数据有很多,可以是简单的字符串、也可以是一张图片。
POST 啥数据,那就看服务器要啥数据,要啥给啥,就这么简单。
看一下搜索的结果页,不难发现,搜索结果存储在 class 属性为 xing_vb4 的 span 标签里。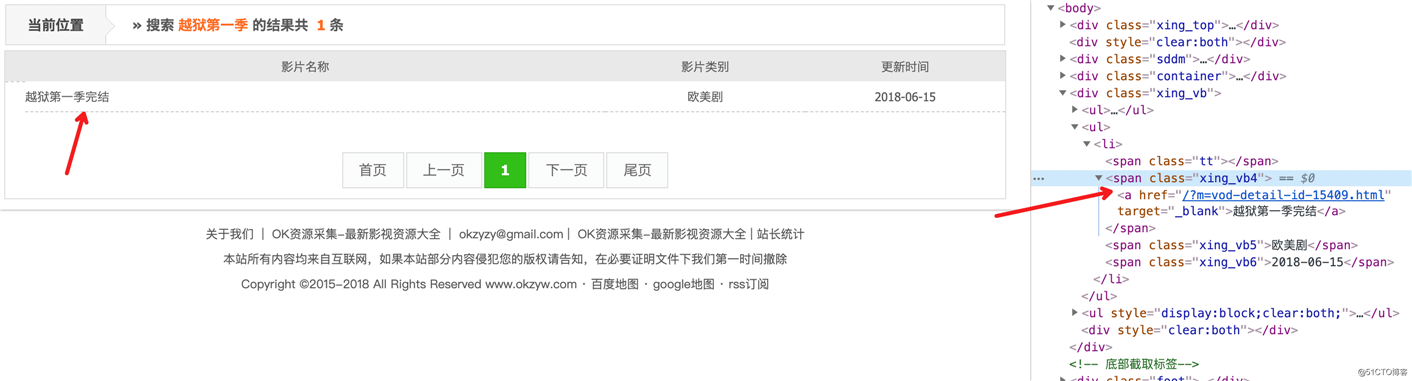
没有难度啊,直接搞起。根据浏览器抓包结果,填写 data 信息即可。由于网站也有简单的 Header 反爬虫,所以一些必要的 Headers 信息也要填写。
import requests
from bs4 import BeautifulSoup
search_keyword = ‘越狱第一季‘
search_url = ‘http://www.jisudhw.com/index.php‘
serach_params = {
‘m‘: ‘vod-search‘
}
serach_headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36‘,
‘Referer‘: ‘http://www.jisudhw.com/‘,
‘Origin‘: ‘http://www.jisudhw.com‘,
‘Host‘: ‘www.jisudhw.com‘
}
serach_datas = {
‘wd‘: search_keyword,
‘submit‘: ‘search‘
}
r = requests.post(url=search_url, params=serach_params, headers=serach_headers, data=serach_datas)
r.encoding = ‘utf-8‘
server = ‘http://www.jisudhw.com‘
search_html = BeautifulSoup(r.text, ‘lxml‘)
search_spans = search_html.find_all(‘span‘, class_=‘xing_vb4‘)
for span in search_spans:
url = server + span.a.get(‘href‘)
name = span.a.string
print(name)
print(url)顺利拿到详情页地址: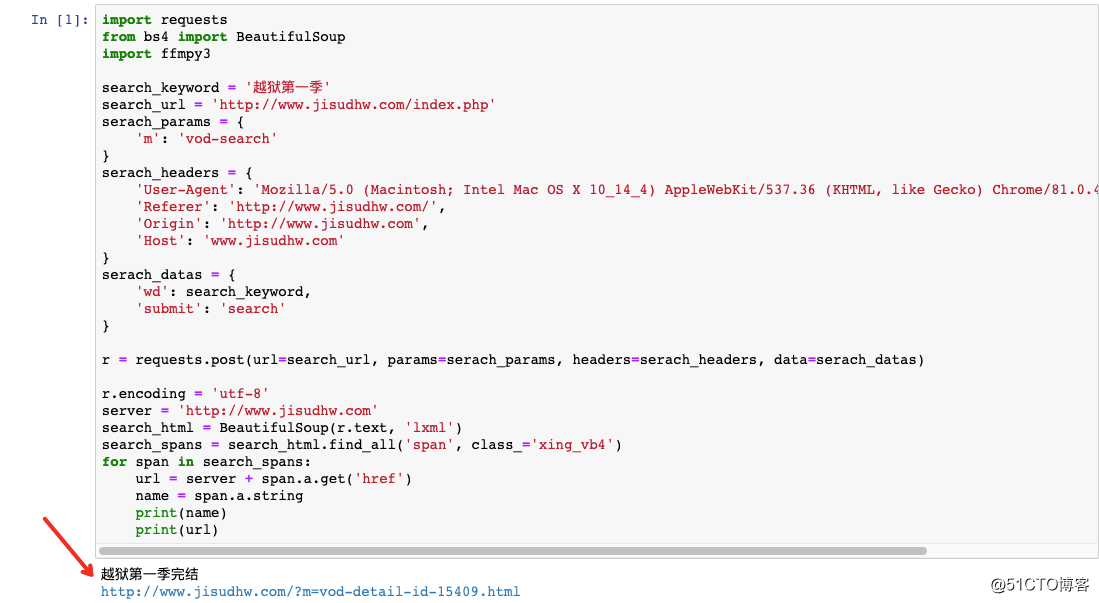
解析详情页,获得下载链接,我们先看下详情页都有啥。
URL:http://www.jisudhw.com/?m=vod-detail-id-15409.html
视频详情页,至少有两种播放类型,一种是 m3u8 ,一种是 kuyun 。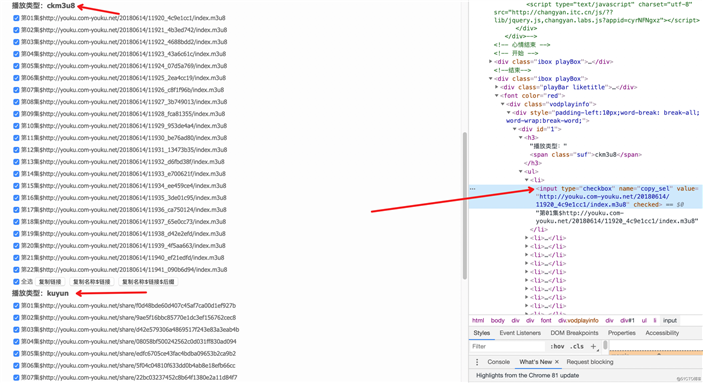
拿到其中一种链接即可,我们以 m3u8 为例进行说明。
可以看到,视频链接都放在了 input 标签里,直接匹配:
import requests
from bs4 import BeautifulSoup
detail_url = ‘http://www.jisudhw.com/?m=vod-detail-id-15409.html‘
r = requests.get(url = detail_url)
r.encoding = ‘utf-8‘
detail_bf = BeautifulSoup(r.text, ‘lxml‘)
num = 1
serach_res = {}
for each_url in detail_bf.find_all(‘input‘):
if ‘m3u8‘ in each_url.get(‘value‘):
url = each_url.get(‘value‘)
if url not in serach_res.keys():
serach_res[url] = num
print(‘第%03d集:‘ % num)
print(url)
num += 1将结果都存放到了字典里,这样方便后续视频链接和视频名称的一一对应。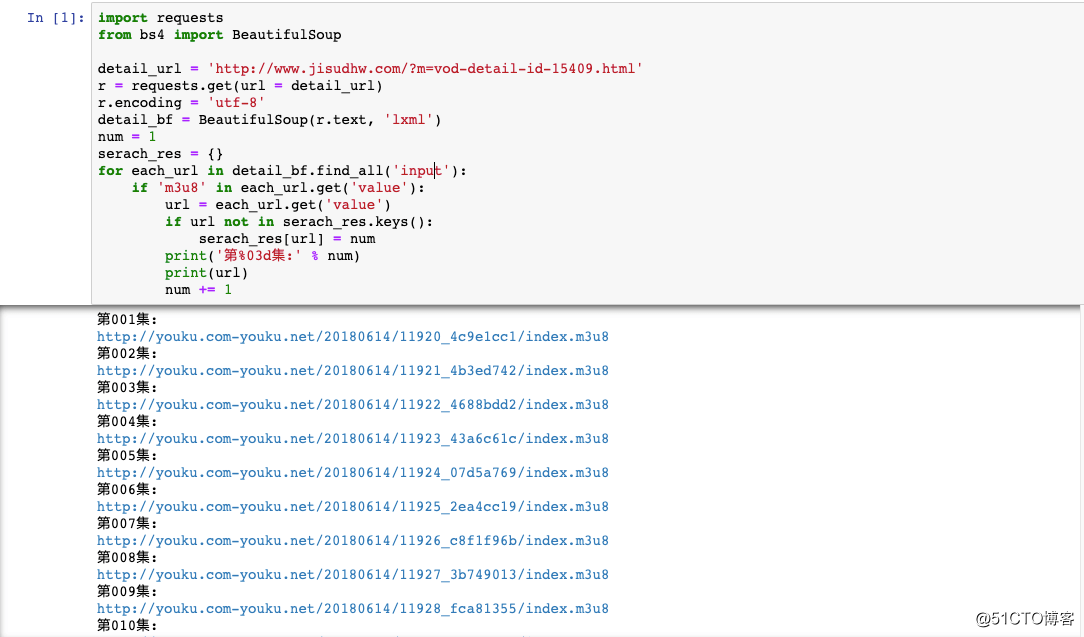
视频下载,一般而言,无非两种情况。
一种,链接明确是以 mp4、mkv、rmvb 这类视频格式后缀为结尾的链接,这种下载很简单,跟图片下载方法一样,就是视频文件要比图片大而已。
另一种,链接是以 m3u8 这类分段视频后缀结尾的链接。啥是分段视频?
抓包看一下就知道了,打开视频播放链接:
http://youku.com-youku.net/share/f0d48bde60d407c45af7ca00d1ef927b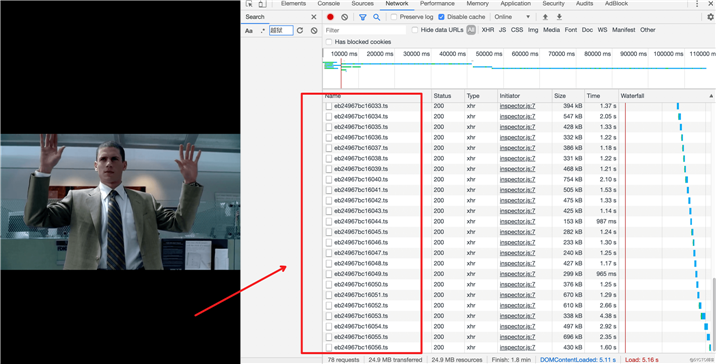
现在很多视频都是分段存储的,你看视频的时候,其实是在加载一个个 ts 视频片段,一个片段是几秒钟的视频。
这种视频要怎么下载?怎么将 ts 视频片段组合成一个视频?
其实,如果知道方法,就很简单。
m3u8 这种格式的视频,就是由一个个 ts 视频片段组成的。
一个 m3u8 文件并不大,你可以把它理解为链表,每个 ts 视频片段文件,都有下一个时序的 ts 视频片段的地址。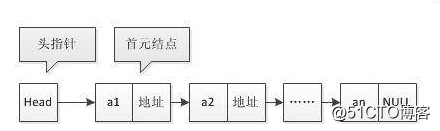
记住一点,解决音频和视频的一些问题,可以看看 FFmpeg,它的中文名叫多媒体视频处理工具。
FFmpeg 有非常强大的功能包括视频采集、视频格式转换、视频抓图、给视频加水印等功能。
这种 ts 视频片段合成,格式转换问题,交给 FFmpeg 就好了。
要使用 FFmpeg,需要先安装配置一番。
下载地址:https://ffmpeg.zeranoe.com/builds/安装好后,记得配置环境变量。
FFmpeg 也有 Python API 接口,名字叫 ffmpy3,安装好 FFmpeg 后,可以直接通过 pip 安装。
pip install ffmpy3
都弄好,就可以愉快的玩耍了。
比如想要下载 m3u8 文件。
URL:
http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8
可以在命令行输入如下指令:
ffmpeg -i "http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8" "第001集.mp4"视频会保存为「第001集.mp4」。
如果用 Python 接口,也只需要两行代码:
import ffmpy3
ffmpy3.FFmpeg(inputs={‘http://youku.com-youku.net/20180614/11920_4c9e1cc1/index.m3u8‘: None}, outputs={‘第001集.mp4‘:None}).run()FFmpeg 自动整合 ts 分段视频,并保存为 mp4 格式的视频。
是不是很简单?
4
代码整合在一起,开始下载电视剧。
import os
import ffmpy3
import requests
from bs4 import BeautifulSoup
from multiprocessing.dummy import Pool as ThreadPool
search_keyword = ‘越狱第一季‘
search_url = ‘http://www.jisudhw.com/index.php‘
serach_params = {
‘m‘: ‘vod-search‘
}
serach_headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36‘,
‘Referer‘: ‘http://www.jisudhw.com/‘,
‘Origin‘: ‘http://www.jisudhw.com‘,
‘Host‘: ‘www.jisudhw.com‘
}
serach_datas = {
‘wd‘: search_keyword,
‘submit‘: ‘search‘
}
video_dir = ‘‘
r = requests.post(url=search_url, params=serach_params, headers=serach_headers, data=serach_datas)
r.encoding = ‘utf-8‘
server = ‘http://www.jisudhw.com‘
search_html = BeautifulSoup(r.text, ‘lxml‘)
search_spans = search_html.find_all(‘span‘, class_=‘xing_vb4‘)
for span in search_spans:
url = server + span.a.get(‘href‘)
name = span.a.string
print(name)
print(url)
video_dir = name
if name not in os.listdir(‘./‘):
os.mkdir(name)
detail_url = url
r = requests.get(url = detail_url)
r.encoding = ‘utf-8‘
detail_bf = BeautifulSoup(r.text, ‘lxml‘)
num = 1
serach_res = {}
for each_url in detail_bf.find_all(‘input‘):
if ‘m3u8‘ in each_url.get(‘value‘):
url = each_url.get(‘value‘)
if url not in serach_res.keys():
serach_res[url] = num
print(‘第%03d集:‘ % num)
print(url)
num += 1
def downVideo(url):
num = serach_res[url]
name = os.path.join(video_dir, ‘第%03d集.mp4‘ % num)
ffmpy3.FFmpeg(inputs={url: None}, outputs={name:None}).run()
# 开8个线程池
pool = ThreadPool(8)
results = pool.map(downVideo, serach_res.keys())
pool.close()
pool.join()由于视频太大了,要是一个一个地下载,有些慢,适当开个线程,8 线程下载。
来吧,一起看「越狱」吧!
5
本文仅是探讨一些关于视频下载的技术,切勿滥用。
支持正版,从我做起。
关注微信公众号,公众号文章评论区留言,获赞数前2名的读者,将获得爱奇艺1个月黄金 VIP 会员。
Jack Cui
gzh-1.jpg
长按识别二维码关注
Jack Cui
分享或点在看是最大的支持
喜欢作者
4 人喜欢
文章已于2020-05-08修改
阅读原文
标签:灰产 不难 时长 value proc headers 需要 ide 图片下载
原文地址:https://blog.51cto.com/14915208/2526153